A800芯片价格疯涨还有倒卖乱象“报价仅仅有效两个小时”,“根本就买不到”,“一天可以从98000/片涨到110000/片”,很多很多电子经销商和卖家都在各自的朋友圈和群聊中讨论最近最火爆的英伟达A800芯片。基本上现在A800芯片是一天一个价,量多就按照10万/片,量少11万/片都不一定能拿到,是笔者和经销商友人询问了目前市场状况后得到的回答。
A800芯片价格疯涨还有倒卖乱象“报价仅仅有效两个小时”,“根本就买不到”,“一天可以从98000/片涨到110000/片”,很多很多电子经销商和卖家都在各自的朋友圈和群聊中讨论最近最火爆的英伟达A800芯片。基本上现在A800芯片是一天一个价,量多就按照10万/片,量少11万/片都不一定能拿到,是笔者和经销商友人询问了目前市场状况后得到的回答。 笔者询问相关从业者聊天截图
笔者询问相关从业者聊天截图
不仅是海南经销商朋友这边的回答,据澎湃新闻报道,英伟达在国内的代理商也向媒体表示:“考虑到禁售传闻,大家都比较惜售,这一个多礼拜以来涨幅了20%-30%了。而且也有渠道商从一些私人手里收来,据说有些服务商的运维人员通过特殊手段用旧卡替换掉较新的显卡,再以各种理由流出市场,转而在各种“二道贩子”手里交易,而这一切其实都是背后的利益驱使。”而且这一切背后的由头都指向,此前的一条消息称,美国可能在今年7月采取相关禁令措施,阻止全球最大的显卡制造商向中国出售最高端的显卡芯片,英伟达A800芯片据传也在限制名单之列。 英伟达芯片(图源:官网)
英伟达芯片(图源:官网)
 A800究竟是何方神圣时间推回到2022年11月,英伟达推出了中国特供版GPU芯片A800,可以直接取代A100系列,是专门为了解决美国商务部半导体出口新规而设计。其芯片数据传输速率为400GB/s,低于A100的600GB/s,内存带宽最高为2TB/s,目前A800系列有三个版本和SXM和PCIe两种不同接口:分别是40GB HBM2线程PCIe接口、80GB HBM2e显存PCIe接口、80GB HBM2e显存SXM接口。
A800究竟是何方神圣时间推回到2022年11月,英伟达推出了中国特供版GPU芯片A800,可以直接取代A100系列,是专门为了解决美国商务部半导体出口新规而设计。其芯片数据传输速率为400GB/s,低于A100的600GB/s,内存带宽最高为2TB/s,目前A800系列有三个版本和SXM和PCIe两种不同接口:分别是40GB HBM2线程PCIe接口、80GB HBM2e显存PCIe接口、80GB HBM2e显存SXM接口。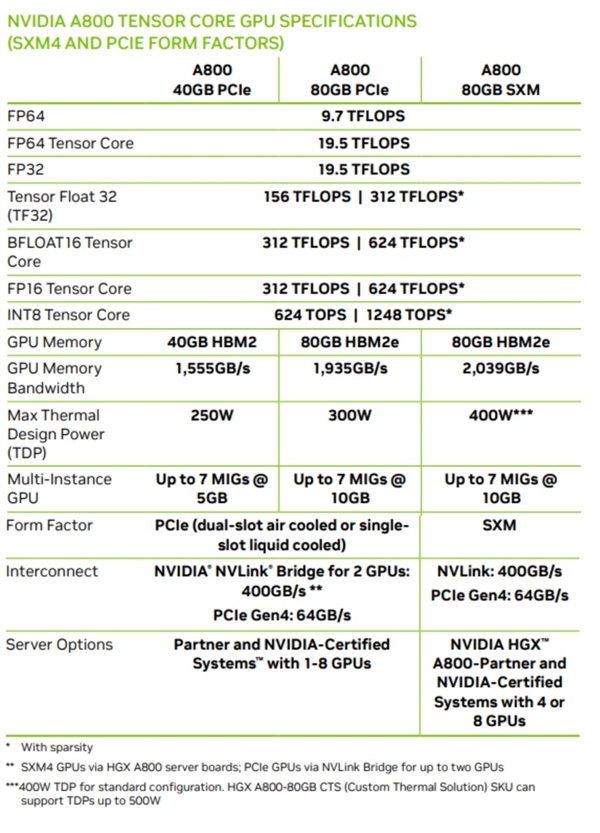
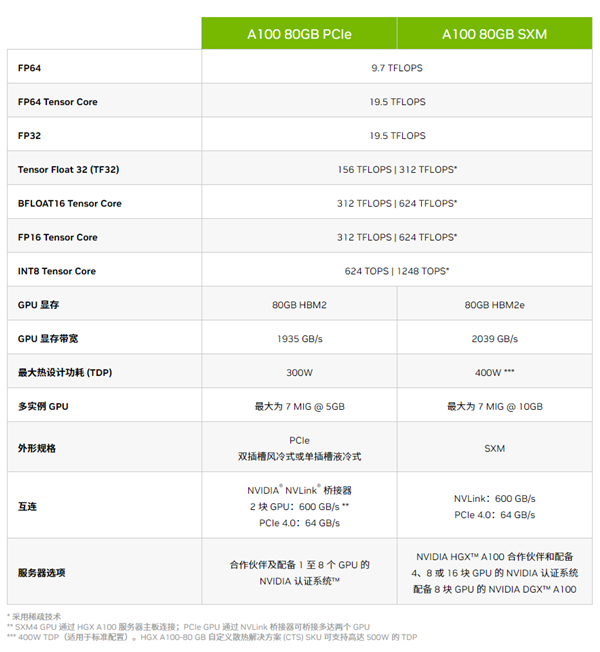 A800和A100芯片性能(图源:官网)
A800和A100芯片性能(图源:官网)
根据官方放出的数据看来,A800就是A100的马甲卡,将NVLink高速互连总线的带宽从600GB/s降低到400GB/s,其他参数保持不变。像是9.7TFlops FP64双精度、19.5TFlops FP32单精度等极高计算性能、1.6-2.0TB/s显存带宽,最高八卡互联并行等功能也是应有尽有。随着GPT 和LLaMA等大模型的火热,运算卡和算力成为国家战略级的议题,大模型的训练需要大量AI芯片,像是国外的英伟达、AMD、高通等知名半导体企业和国内的平头哥、字节跳动芯片部门纷纷招兵买马的大刀阔斧的投入到AI芯片的研究中,据悉台积电5/7nm制程订单已经近乎饱和,排产订单已延续至2024年初,并且单量还在逐步走高。对手的加入,一方面是让全新的市场百花齐放,另一方面是竞争会引起价格的下降,低价高质的竞品对于垄断的厂商是一大威胁,英伟达A100系列高达1万美元,而H100则高达3万美元。也当真应了文章标题所说,工程师干一年的薪水还赶不上一块显卡的售价。AMD在某些硬件的参数其实已经超越了英伟达的H100 例如前一阵的芯片MI300X的显存最高位192GB,5.2TB/s的内存带宽和896GB/s的InfinityFabric带宽,相较于英伟达的H100芯片,MI300X提供了更高的HBM密度和HBM带宽,为客户节省了大量成本。 AMD MI300X 发布会(图源:网络)
AMD MI300X 发布会(图源:网络)
AMD的加入可以说是英伟达垄断地位的搅局者,一家独大的市场终究是畸形的,有挑战者自然也就有挑战者的挑战者,国内的不少公司也在你追我赶,像是瀚博半导体的载天VA1:通用AI推理加速卡、寒武纪的智能加速卡-MLU370-S4系列、昆仑芯AI加速卡R200系列等等也都百花齐放。良性的竞争带来技术的进步,封锁只会故步自封,相信国内的芯片厂商需要的只是时间,假以时日势必会有属于国产自主知识产权的AI芯片和大模型。【扩展阅读】:【SXM】NVIDA GPU-SXM主要是针对英伟达的高端GPU服务器,通过主板上集成的NVSwitch实现NVLink的连接,不需要通过主板上的PCIe进行通信,它能支持8块GPU卡的互联互通,实现了GPU之间的高带宽。这里说的NVLink技术不仅能够实现CPU和GPU直连,能够提供高速带宽,还能够实现交互通信,大幅度提高交互效率,从而满足最大视觉计算工作负载的需求。【PCIe】把PCIe GPU卡插到PCIe插槽上,然后和CPU、同一个服务器上其他的GPU卡进行通信,也可以通过网卡与其他的服务器节点上的设备进行通信。但是这种传输速度不快,如果想要和SXM一样,有很快的传输速度,可以使用NVlink桥接器实现GPU和CPU之间的通信,但是和SXM不一样的地方就是它只能实现2块GPU卡之间的通信。 *作者:我的果果超可爱, 来源:电子工程专辑
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。