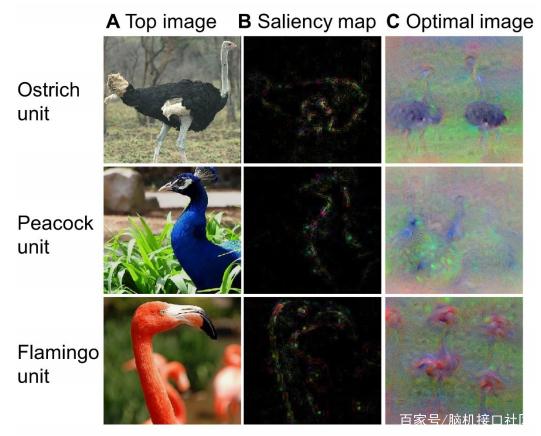
用于精确目标检测的多网格冗余边界框标注
论文地址:https://arxiv.org/pdf/2201.01857.pdf
现在领先的目标检测器是从基于深度CNN的主干分类器网络重新调整用途的两级或单级网络。
一、前言
现在领先的目标检测器是从基于深度CNN的主干分类器网络重新调整用途的两级或单级网络。YOLOv3就是这样一种众所周知的最先进的单级检测器,它接收输入图像并将其划分为大小相等的网格矩阵。具有目标中心的网格单元负责检测特定目标。
今天分享的,就是提出了一种新的数学方法,该方法为每个目标分配多个网格,以实现精确的tight-fit边界框预测。研究者还提出了一种有效的离线复制粘贴数据增强来进行目标检测。新提出的方法显着优于一些当前最先进的目标检测器,并有望获得更好的性能。
二、背景
目标检测网络旨在使用紧密匹配的矩形边界框在图像上定位对象并正确标记它。如今,有两种不同的方法可以实现这一目的。第一个也是性能方面,最主要的方法是两阶段目标检测,最好的代表RCNN及其衍生物[Faster r-cnn: Towards real-time
object detection with region proposal networks]、[Fast r-cnn]。相比之下,第二组目标检测实现因其出色的检测速度和轻量级而广为人知,被称为单阶段网络,代表性示例为[You only look once: Unified, real-time object detection]、[Ssd: Single shot multibox detector]、[Focal loss for dense object detection]。两阶段网络依赖于一个潜在的区域建议网络,该网络生成可能包含感兴趣对象的图像的候选区域,第二个检测头处理分类和边界框回归。在单阶段目标检测中,检测是一个单一的、完全统一的回归问题,它在一个完整的前向传递中同时处理分类和定位。因此,通常,单阶段网络更轻、更快且易于实现。

今天的研究依然是坚持YOLO的方法,特别是YOLOv3,并提出了一种简单的hack,可以同时使多个网格单元预测目标坐标、类别和目标置信度。每个对象的多网格单元分配背后的基本理论是通过强制多个单元在同一对象上工作来增加预测紧密拟合边界框的可能性。

多网格分配的一些优点包括:
(a)为目标检测器提供它正在检测的对象的多视角视图,而不是仅依靠一个网格单元来预测对象的类别和坐标;
(b ) 较少随机和不稳定的边界框预测,这意味着高精度和召回率,因为附近的网格单元被训练来预测相同的目标类别和坐标;
(c) 减少具有感兴趣对象的网格单元与没有感兴趣对象的网格之间的不平衡。
此外,由于多网格分配是对现有参数的数学利用,并且不需要额外的关键点池化层和后处理来将关键点重新组合到其对应的目标,如CenterNet和CornerNet,可以说它是一个更实现无锚或基于关键点的目标检测器试图实现的自然方式。除了多网格冗余注释,研究者还引入了一种新的基于离线复制粘贴的数据增强技术,用于准确的目标检测。
三、MULTI-GRID ASSIGNMENT

上图包含三个目标,即狗、自行车和汽车。为简洁起见,我们将解释我们在一个对象上的多网格分配。上图显示了三个对象的边界框,其中包含更多关于狗的边界框的细节。下图显示了上图的缩小区域,重点是狗的边界框中心。包含狗边界框中心的网格单元的左上角坐标用数字0标记,而包含中心的网格周围的其他八个网格单元的标签从1到8。

到目前为止,我已经解释了包含目标边界框中心的网格如何注释目标的基本事实。这种对每个对象仅一个网格单元的依赖来完成预测类别的困难工作和精确的tight-fit边界框引发了许多问题,例如:
(a)正负网格之间的巨大不平衡,即有和没有对象中心的网格坐标
(b)缓慢的边界框收敛到GT
(c)缺乏要预测的对象的多视角(角度)视图。
所以这里要问的一个自然问题是,“显然,大多数对象包含一个以上网格单元的区域,因此是否有一种简单的数学方法来分配更多这些网格单元来尝试预测对象的类别和坐标连同中心网格单元?”。这样做的一些优点是(a)减少不平衡,(b)更快的训练以收敛到边界框,因为现在多个网格单元同时针对同一个对象,(c)增加预测tight-fit边界框的机会(d) 为YOLOv3等基于网格的检测器提供多视角视图,而不是对象的单点视图。新提出的多重网格分配试图回答上述问题。

Ground-truth encoding
四、训练
A. The Detection Network: MultiGridDet
MultiGridDet是一个目标检测网络,通过从YOLOv3中删除六个darknet卷积块来使其更轻、更快。一个卷积块有一个Conv2D+Batch Normalization+LeakyRelu。移除的块不是来自分类主干,即Darknet53。相反,将它们从三个多尺度检测输出网络或头中删除,每个输出网络两个。尽管通常深度网络表现良好,但太深的网络也往往会快速过度拟合或大幅降低网络速度。
B. The Loss function


Coordinate activation function plot with different β values
C. Data Augmentation
离线复制粘贴人工训练图像合成工作如下:首先,使用简单的图像搜索脚本,使用地标、雨、森林等关键字从谷歌图像下载数千张背景无对象图像,即没有我们感兴趣的对象的图像。然后,我们从整个训练数据集的随机q个图像中迭代地选择p个对象及其边界框。然后,我们生成使用它们的索引作为ID选择的p个边界框的所有可能组合。从组合集合中,我们选择满足以下两个条件的边界框子集:
if arranged in some random order side by side, they must fit within a given target background image area
and should efficiently utilize the background image space in its entirety or at least most part of it without the objects overlap.
五、实验及可视化
Pascal VOC 2007上的性能比较


coco数据集上的性能比较


从图中可以看出,第一行显示了六个输入图像,而第二行显示了网络在非极大抑制(NMS)之前的预测,最后一行显示了MultiGridDet在NMS之后对输入图像的最终边界框预测。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。