
工业检测应用中可扩展的微处理器视觉系统的评估框架
算法流程图
本文引用地址:http://www.amcfsurvey.com/article/85676.htm上图给出了检测图像缺陷的算法。原始图像通过过滤去掉噪声,并平滑由于传送器上的角度问题而造成的部分颜色和明亮度的变化。
图像转化为HLS模型,以便再通过两个16位输入8位输出的查找表转化成单色。HLS模型中,色度(H)和饱和度(S)由颜色决定,而明亮度(L)主要由能被光照到的物体表面的方位决定。这两要素在8位单色像(图表中为M)的结构中被编码。这一步骤可以用于检测颜色错误和总体方向错误,因而显得比较重要。
在对图像进行去斑降噪之后,开始对图像进行连接性的分析。分析结果用于从单色和彩色图像中选择区域,以获得另外的特性。这一步一般会减少百分之七十的像素数量。
所选区域用单色进行量测,彩色则用于发展每个区域的特性。获得的特性是颜色,通过单色图像、连接框、边界圆、周长、凸包和面积等要素修正。
这些特性作为神经网络识别器的输入。之所以选择神经网络识别器是因为要处理的图像区域相当复杂。统计型的识别器难以进行计算,而且对噪声敏感。神经网络使用100个输入,在第一个隐藏层使用200个节点,第二层使用100个节点,输出层(通过/未通过)使用一个节点。
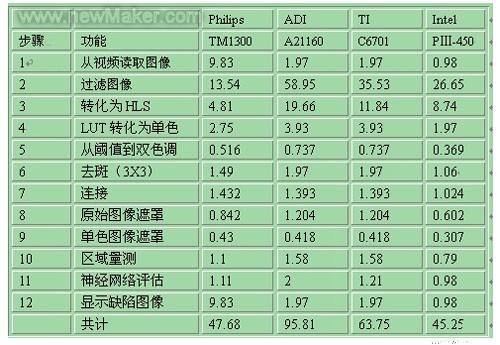
选择处理系统的下一步就是要使用下面所选的微处理器进行评估算法:Analog Devices公司的21160Hammerhead,Intel®(P3-450),Philips公司的半导体TM1300 TriMedia和德州仪器(TI)的C6701。每种处理器的编码已经优化过,每种类型单个处理器的执行时间也已测过。下表给出了每个处理器执行每一步算法的结果。
分析与结果
所有时间单位为毫秒
从上表中,我们可以发现每种处理器都有各自的优点。若以总时间来论,则PⅢ-450无疑是最佳的。其中两种处理器需要保持与照相机同步的图像速度。所有情况下,系统需要另外一个处理器来提供操作系统支持,如磁盘驱动和用户界面。PⅢ的计算能力似乎不够理想,但在限制于存储器总线性能的应用中,它仍然是个相当出色的处理器。PⅢ的存储器总线速度是其他处理器的两倍,TM1300是个例外,PⅢ的存储器总线速度只是它的1.4倍(800MB/s VS 572MB/s)。
Philips和TI的处理器拥有许多处理单元,这使得它们具有相当好的总体性能,尽管在时钟速度上它们远慢于Intel PⅢ-450。Philips的TM1300使用一个视觉端口对处理器进行直接的读取和显示。Intel PⅢ-450、Analog Devices 21160和TI C6701则使用DMA控制器进行读取和显示。
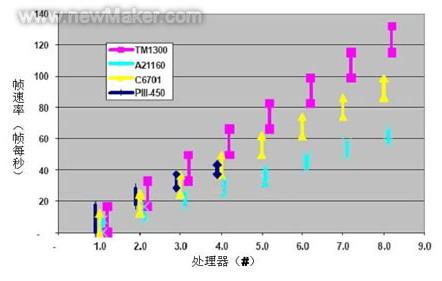
上图给出了随着处理器的增加可达到的帧速率。从图中可以看出,TM1300和PⅢ-450在此应用中性能相当,居于最前,TMS320C6701稍慢些,ADI21160则是最慢的。Philip TM1300、Analog Devices 21160和TI C6701都需要两个处理器以保持图像速率。但它们(在PC上的协处理器板上)的成本却远低于PⅢ-450。一个多处理器的PⅢ-450系统需要花费几千美元(大约3000美元)——价格高于基本的单处理器PC. Philip TM1300、Analog Devices 21160和TI C6701的协处理器系统最低只需1500美元。
另外,随着额外的处理器的增加,PⅢ的效率开始降低。多处理器PⅢ系统中使用的共享多处理器(SMP)总线因为处理器间的总线冲突从而降低了存储器密集应用的性能。随着额外处理器的增加,冲突更加突出,效率也就更低了。装有超过4个PⅢ处理器的系统并不多见。连接处理器到照相机需要有特定的硬件。基于21160和TMS320C6701的解决方案所要花的成本要高于基于TriMedia和PⅢ的解决方案所花的成本。
结论
以元件检测应用为例,我们发现在存储器带宽发挥重要作用的应用场合,奔腾PⅢ-450无疑是个极为出色的处理器。然而,基于集群的体系结构却产生了负面影响,因为存储器总线饱和严重制约了将来的可扩展性(如PⅢ-450)。相反,基于本地存储器体系解决方案的处理器却能随着处理器的增加而线性地提高其处理量。
Intel PⅢ受其外围逻辑(PC)的限制,在一些应用场合不能发挥其性能。尽管AGP总线的使用会改善这种情况,但其SMP设计最终将限制其扩展性。因此,在要求严格的视觉应用场合尤其是需要用于将来扩展的应用场合,最可行的办法是保留一个更易扩展、有更高吞吐量的协处理器板,最终使得成本低于本地解决方案所花的成本。 (end)







评论