
高带宽嵌入式应用中SoC微控制器的新型总线设计
传统SoC总线架构已不能满足新的联网嵌入式设计对高带宽数据流进行实时控制的需求, NetSilicon开发的可编程总线带宽控制系统可以使多个资源同时访问总线,使其既满足应用要求又不会影响其他重要操作的性能。本文将对该系统的可编程总线带宽分配方案进行探讨。
本文引用地址:http://www.amcfsurvey.com/article/78050.htm32位嵌入式设计越来越要求对网络上高带宽数据流进行实时控制,特别是在系统级芯片(SoC)层面,以确定性和无争议的方式传输数据和控制信息变得非常重要。各种操作直接处于系统开发者既定的控制之下也很重要,而这在基于总线的SoC设计中并不总是能够实现。
设计者和芯片供应商常常借鉴板级及系统级架构技术,以便在最短的设计时间内以最低的开发成本进行SoC设计。由于手机和PDA等设备对确定性的实时响应需求很少,所以传统解决方案在此类应用中表现还不错。
但在许多新的联网嵌入式设计中,传统总线架构不能满足共享总线对高带宽及高密度数据流的需求,在下列应用中尤其如此,如工业用人机界面(HMI)网络显示、 POS终端设备,具有不同数据带宽需求的彩色打印机、网络投影仪和监视摄像机,以及网络打印机、数字复印机、多功能一体机、传真机和扫描仪等。
许多基于片上串行互连的替代方案正在研发中,这些替代方案类似于串行结构、交叉交换(crossbar switch)和基于数据包的总线。在这些新方案得以完善之前,鉴于时间和成本压力,必须找到能修改从板级设计借鉴过来的共享总线架构的方法,以满足新的 32位嵌入式联网设计对确定性和实时性的要求。
传统SoC总线的优缺点
SoC开发者不愿意放弃这种通用共享总线,因为它可以减少设计周期中的规范制定及验证工作,能使SoC的高层次集成如同将扩展卡插到背板上一样简单。通过采用通用总线,开发者可以集中精力投入到更高层次的决策中。
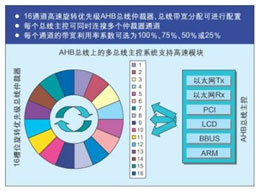
图1:NS9xxx的带宽控制系统。
ARM公司在高级微控制器总线架构(AMBA)中采用通用总线,允许获得许可的使用者专注于自己的应用开发,从而快速将产品推向市场。
微处理器、 DMA控制器、存储器控制器及其它更高性能的模块通过AHB连接。性能较低的模块,比如UART、通用输入/输出(GPIO)及定时器等,则通过APB连接。
但是,基于ARM的SoC所瞄准的许多高端嵌入式应用,要求它们在处理这些应用的确定性与实时性需求的同时,还可以访问高带宽网络环境。
这些应用要求SoC能够发出控制信号、采集数据并在网络上实时传输数据。基于不同的网络特性及其带宽要求,现有SoC总线架构的性能将会得到尽可能的提升,例如,高端联网嵌入式应用可能要处理通过以太网连接从照相机传输到打印机的视频数据位流,或从服务器传输到打印机的图像,与此同时还可能根据与扫描、刷新和更新周期有关的确切要求对本地 LCD显示进行更新。使用外部LCD时,LCD控制器必须知道通过该总线传输的具体字节数量、数据发送顺序以及数据在显示器上显示的特定时隙和顺序,同时也很必要将信息不断地馈送给LCD用于更新。
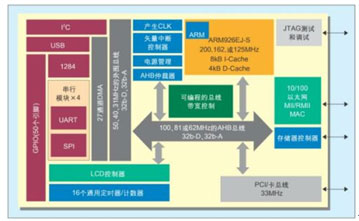
图2: NS9750原理框图。
共享总线的概念并不能满足SoC中的这些要求。在典型的AHB设计中,总线主控是总线上全部的主要资源,也就是说,当总线空闲时,它们可向总线请求完成一个任务所需要的时间。但在基于ARM的SoC中,程序设计者不能直接控制当它们掌管总线时可得到多少总线资源。
共享总线架构用多种方式来区分这些操作的优先次序,包括:菊花链仲裁、集中式并行仲裁、基于自选或冲突监测的分布式仲裁以及带多个总线请求的总线仲裁。但当指定的主控接管总线后,其他操作就会搁置在一边。目前还没有一种机制能够让多个资源同时访问总线,使其既满足应用要求,又不会影响其他重要操作提供确定性及实时性响应的能力。
在AMBA环境中处理这类情况的一种通用方法是使用仲裁通道。如果有六个总线主控,总线便设计成有六个仲裁通道。但是,片上仲裁逻辑根据请求访问该总线的主控数目来分配这些通道,而不是把每个通道指定给某个特定的主控。如果有四个主控请求访问总线,则这六个通道会在这四个主控之间进行分配,确保每个主控有平等的机会访问该总线。
然而,这并不能解决如何分配足够的总线带宽以完成某一特定任务这一基本问题。若其中一个操作需要三个通道,而其它操作总共只需要两个通道,则每一种操作将会分配到相同数量的可用通道空间。其结果是,有的通道没有充分利用 (甚至根本没用到),而有的则超负荷使用,影响SoC在极低延迟内对事件进行确定性响应的能力。
可编程总线带宽控制系统
因此,需要一种可编程的总线带宽分配方案,在某一特定时刻为某一特定的主控分配其所需的总线配置,并将剩余的总线空间分配给其它可能要求访问该总线的主控。由于这种方案可能随时间改变,因此需要一种机制以便按照常规原理重新分配总线资源。
NetSilicon 公司已开发一种新的带宽控制系统来取代采用AMBA架构的带宽控制系统。该系统采用一个16槽位旋转优先级总线仲裁器(见图1),这种仲裁器包含一套可编程伪随机或旋转优先级缓存替换算法。例如,在NetSilicon的 NS9750(见图2)中,AHB上的六个通道不是通过竞争进行分配,而是根据16槽位总线分配方案由六个总线主控分享。通过系统控制模块中的专用寄存器,系统开发者目前可采用三种方法在SoC中分配总线资源。
在最高层次,某特定总线主控每次发出的一个访问请求,都会按请求顺序得到响应,直到这六个主控全被轮询。根据所需带宽,每一个总线主控可分配到一定数目的槽位并独占这些槽位。例如在NS9750中,四个槽位分配给CPU,四个槽位给以太网,四个槽位给BBus桥,三个槽位给LCD,三个槽位给PCI/卡总线,但在系统运行期间系统软件会根据需要重新评估这一分配方案,这可用来确定AHB总线周期的数目。如果在下一个评估周期中情况没有发生变化,则沿用以前的设置,如果情况有变,则协定新的总线主控槽位分配方案。
为对总线资源进行更精确的控制,这种循环仲裁方案提供两个附加层次的可编程性能:分配给ARM CPU的总线带宽大小以及这16个槽位中每个槽位的带宽利用率。
NS9750 的ARM926EJ-S内核作为总线主控时不能控制所有总线资源,缺省情况下它只能控制50%的总线带宽或16个槽位中的8个,这样可确保其它五个总线主控可以一直占有至少50%的总线带宽。不过,在程序设计者直接控制下,它可以按照指令将其部分带宽释放给另一个总线主控,或者,在该总线仲裁周期内或程序设计者认为必要的任何周期中控制另外的槽位。
程序设计者也可为每个槽位选择带宽利用系数——100%、75%、50%或25%。这一选择是通过控制何时以及以怎样的顺序分配每个槽位的访问来实现的,系数为25%,则这个槽位每四个周期只能被轮询一次;系数为50%,则每两个周期轮询一次;75%,则每四个周期轮询三次。
对旋转总线仲裁器进行编程
程序设计者可通过包含在系统控制模块内的几个寄存器定义多种选项。第一个寄存器是16入口总线请求配置寄存器,它的每一个入口代表一个主控和一个准许槽位的总线请求。每一个请求/准许槽位每次只能分配给一个总线主控,但根据总线主控的带宽要求,每个总线主控可同时连接多个请求/准许槽位。当多个通道分配给一个主控时,这些通道应均匀分布在这16个通道当中。
每个请求/准许槽位都有一个两位的带宽压缩字段(BRF),用以确定每个槽位能对系统总线进行仲裁的频率(100%、75%、 50%或25%)。BRC将总线请求信号输出到第二个16入口总线请求寄存器(BRR),默认情况下,BRC中未被分配的槽位将阻止用任何总线请求信号设置相应的BRR入口。
第四个寄存器用于存储哪个总线主控有数据在等待向AHB传输,而第五个寄存器则是程序设计者用来为每个总线请求和准许槽位(分配给特定总线主控)分配权重值。
使用循环仲裁
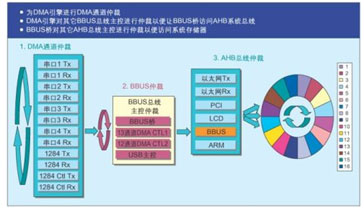
图3:NS9xxx的总线架构。
在前面例子中,当基于特定仲裁再分配调度方案的LCD请求额外的总线访问时,程序设计者可根据LCD必须处理的数据流的性质来指定分配给LCD的优先级。如果程序设计者认为需要分配10个槽位给LCD控制器,剩余的6个槽位会按最初仲裁方案分配给其它总线主控。这样LCD控制器可获得十倍于正常情况下可得到的带宽,以及十倍于其它主控的带宽来处理这种特定情形下的负载。
当通过以太网连接传送数据、同时LCD屏幕进行刷新的时候,这种特性十分重要。LCD需要实时、准确地进行刷新,且不会被以太网请求中断。
在典型的AMBA总线架构中,如果LCD对总线提出请求,不论有怎样的刷新需求,它都不得不等待直到以太网主控将总线释放出来。采用新的循环可编程仲裁方案,程序设计者可降低以太网传输的优先级,使数据以更低但可接受的速率传输,确保LCD得以适当地刷新而不至于使屏幕出现空白。
如果为保证活动画面显示对LCD延时和带宽要求极高,则以太网协议需求还可进一步降低传输速率。但停止数据流传输是不可以的。实际上,如果LCD主控控制了该总线并且只有当刷新工作完成后才将总线释放,则有可能停止数据流的传输。
在外围总线中增加突发模式DMA
在基于AMBA的设计中,外围总线的传统设计方法是假定基于ARM内核的嵌入式器件用于低端性能应用。但现在的器件经常需要在不切断低带宽外围电路访问总线资源的情况下,运行一种或多种高带宽应用。在具有较多外围电路的设计中,这种情况特别容易出问题。例如NS9750或NS9360,它们支持USB、 I2C,具有四个多功能串行模块(可选用UART或SPI,同步模式下的速率可达11Mbps)、50个单独的可编程GPIO引脚、一个IEEE1284 外围端口以及16个通用定时器或计数器(每个都有自己的I/O引脚)。
在传统的APB实现方案中,采用FIFO就足以应付通信外设(如UART)的低速率传输,FIFO可以在处理器必须介入并访问APB之前将数个字节传送到接口。但在本文所描述的许多高端嵌入式应用中,一个或多个这样的外围电路可能需要高带宽传输,要求能通过APB/AHB桥快速访问主要的高性能总线。
一种让外围总线工作于这种突发模式的方法,是仅用一条突发模式外围总线(如NetSilicon的 BBUS)替代APB总线。这种突发模式外围总线带有四个支持突发模式的总线主控(见图3):第一个总线主控是具有13个通道的DMA引擎,支持13个 USB端点;第二个总线主控是具有12个通道的DMA引擎,支持4个串行模块(每个串行模块有8个通道)和1284端口;第三个总线主控为BBUS- AHB桥,它包含一个DMA引擎,该引擎具有可访问AHB系统总线的通道;第四个总线主控是一个USB宿主模块。另外,这种DMA引擎有两个独立的专用 DMA通道,可支持连接到外部存储总线的外部设备。为简化突发模式状态,每一个内部DMA通道以“飞越模式”(fly-by mode)在系统存储器及BBUS外围电路之间传输数据,而两个外部DMA通道则选择存储器到存储器的传输模式。


评论