
AVS 运动补偿电路的VLSI 设计与实现
摘要:
提出了一种基于AVS 标准的高效的运动补偿电路硬件结构, 该设计采用了8 ×8 块级流水线操作, 运动矢量归一化处理和插值滤波器组保证了流水线的高效运行以及硬件资源的最优利用。采用Verilog 语言完成了VLSI 设计, 并通过EDA 软件给出仿真和综合结果。
关键词:
运动补偿; 流水线; AVS
0 引言
AVS 标准是数字音视频编解码技术标准工作组(AVS 工作组) 制定的数字音视频编码标准,其视频部分已于2006 年2 月份被信产部颁布为国家标准,于2006 年3 月1 日起实施。该标准主要面向高清晰度和高质量数字电视广播、数字存储媒体和其他相关应用。
运动估计和运动补偿是AVS 中去除时间冗余的主要方法,它采用多种宏块划分方式,1P4 像素插值、双向估计和多参考帧等技术大大提高了编码效率,但同时也给编解码器增加了一定的复杂度。本文针对AVS 所特有的运动补偿解码过程进行深入分析,并提出了与其算法相适应的运动补偿电路的设计方案,电路采用Verilog 语言描述,并给出了综合和仿真的结果。
1 AVS 运动补偿关键技术分析研究
与其他视频编解码算法相类似,AVS 的运动补偿技术主要涉及三个步骤:通过比特流中的相关信息计算运动矢量、按照运动矢量的指示进行地址转换从MIU 中读取参考像素值、通过参考像素值对当前解码块进行预测。同时,作为一种高效率的视频压缩算法,AVS 也有其独特的技术特征。
AVS 共有4 种宏块划分类型:16 ×16 ,16 ×8 ,8 ×16和8 ×8 ,比MPEG- 2 增加了8 ×8 大小块的运动估计,但并未像H. 264 一样进行更细一级到4x4 块的划分;同时AVS 支持的最大参考帧数为2 帧,而不是MPEG- 4PH. 264 的16 帧,这些都使得AVS 既保证了一定的数据压缩率,又控制了运算复杂度。
AVS 充分利用了图像的运动连续性,对双向预测分两种模式进行处理:对称模式和直接模式。在对称模式中,前向矢量由当前图像中空间相邻块的运动矢量获得,而后向运动矢量由前向运动矢量通过一定的对称规则获得,从而节省了后向运动矢量的编码开销;在直接模式中,前向和后向运动矢量都是由后向参考图像中相应位置的时间相邻块的运动矢量获得,不需要传送运动矢量差值,从而也提高了编码效率。
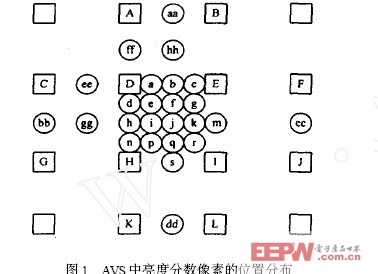 |
2 AVS 运动补偿处理器的VLSI 结构设计
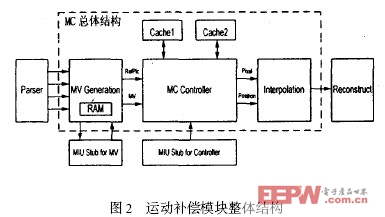
2. 1 运动补偿处理器整体结构
分析AVS 的解码算法,其运动矢量的计算,参考像素的读取以及插值的计算三个部分计算量相当,于是该运动补偿结构相应的包括三个主要功能模块:MV Generation ,MC Controller 和Interpolation ,整个解码器通过三个模块的并行流水操作完成,从而实现了高清图像的实时解码。其中,MV Generation 根据Parser 解出的宏块信息来产生运动补偿过程所需要的运动矢量;MC Controller 根据得到的运动矢量从参考帧读取相应的参考像素并总体控制运动补偿的进行; Interpolation 完成非整数像素点的插值以及加权平均等一系列后处理操作,并将结果输出给Reconstruct 模块。
 |
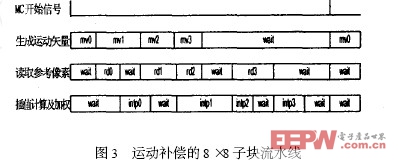
2. 2 MC Controller 的流水控制
在运动补偿过程中,运动矢量的计算,MIU 访问地址的转换以及像素的插值之间具有严格的数据依赖特性,并且,运动矢量的生成时间以及向MIU 响应时间均无法确定,导致运动补偿存在严重的等待问题。如果对每个宏块都依次采用生成运动矢量、读取参考像素、插值计算三个步骤,将会形成非常严重的时钟浪费。
对此本文采用8 ×8 子块级的流水线结构,通过握手机制对运动矢量的生成,参考像素的读取,插值计算和加权进行调度,有效的降低了各模块间因等待造成的时钟浪费。
 |
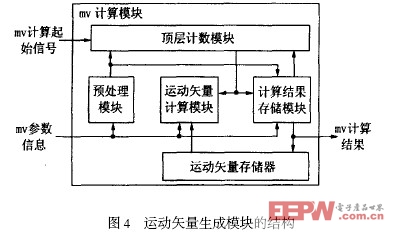
2. 3 MV Generation 的归一化设计
AVS 支持16 ×16 ,16 ×8 ,8 ×16 和8 ×8 共四种宏块划分,灵活的宏块划分方式大大提高了AVS 的压缩率。但由于当前宏块及其相邻宏块的划分均没有一定的规律可循,如果依据常规宏块的划分规则进行运动矢量的存储,则不仅要记录当前宏块的宏块划分,还要记录其相邻宏块的宏块划分,增加了硬件的实现复杂度。
于是,将各种宏块划分的运动矢量均统一到8 ×8的块上,对于运动矢量的生成和存储均采用8 ×8 的块为一个最小单位。对于16 ×16 ,16 ×8 ,8 ×16 的宏块,令划分在同一块内的8 ×8 子块共用一个计算结果,从而读取参考块的运动矢量时,可不必考虑相邻宏块的划分类型,只需一套运动矢量生成电路就可以实现各种划分方式的宏块的运动矢量的计算和存储,简化了运动矢量生成电路的设计和控制,其总体结构如图4 所示。
为了实现流水作业,这里对所有类型的宏块中的四个8 ×8 块按照左上、右上、左下和右下的顺序从0 进行编号。首先,预处理模块根据当前宏块的宏块类型和帧类型对宏块的划分类型进行判断,顶层计数模块给出当前解码8 ×8 子块的子块号。
 |
2. 4 1P4 像素亮度差值器
为了更加逼近实际图像的运动效果,AVS 采用了特有的1P4 精度的亮度预测。但分数像素插值在提高图像质量的同时,也大大增加了计算的复杂度,这在VLSI 实现时直接表现为成本的上升和功耗的增加。例如在解码每秒30 帧,1 920 ×1 080 像素的高清码流时,为了保证视频播放的实时性,最坏情况 下每秒钟需要对1 944 000 个8 ×8 像素的亮度块进行插值操作。巨大的计算量给亮度插值器的VLSI实现带来了一个难题,即如何在保证视频解码实时性的前提下,尽可能缩小芯片的面积并降低系统的时钟频率。
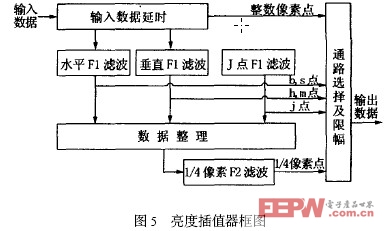 |
其中F1 和F2 均为4 抽头滤波,F1 滤波系数为3 仿真试验基于上述结构,本文完成了Verilog HDL 的RTL级描述,在modelsim5. 8 中对该运动补偿模块进行前仿,将testbench 中对MIU 的等待时间统一设为10 个时钟周期,则P 帧每个宏块需要120 到230 个时钟周期不等,其中P skip 宏块类型占用的时钟最少,P8 ×8 宏块占用的时钟最多;B 帧中每个宏块需要180 到490 个时钟周期不等,其中B Direct 宏块需要的时钟最少,B8 ×8 双向宏块需要的时钟最多。
另外,本文采用Synplify 为开发平台对该运动补偿设计进行综合,选用Virtex4 XC4VLX80 器件,在速度选择为- 10 的条件下,可综合达到121. 1MHz ,共占用9 179个逻辑单元。可见本结构大大减少了视频解码过程中运动补偿占用的时钟周期,不仅充分满足了实时解码高清图像的速度需求,而且有效的控制了硬件资源的使用量。
4 结束语
在视频实时解码芯片的设计中,处理速度和硬件资源的占用是影响芯片性能的两个关键性问题。
本文在对AVS 运动补偿算法进行合理分析的基础上,提出以上结构,该结构既能够高效的实现高清视频的实时解码,又合理的控制硬件资源的使用量。
参考文献:
[1 ] 先进音视频编码标准[ S] . 2004.
[2 ] LI J H , LINGN. An efficient decoder design for MPEG- 2 MP@ML [C] . IEEE Int Conf . on Application - Specific Systems , Architectures and Processors. 1997 :509 - 518.
[3 ] MASAKI T , MORIMOTO Y, ONOYE T , et al . VLSI implementation of inverse discrete cosine transformer and motion compensator for MPEG- 2 HDTV video decoding[J ] . IEEE Trans. on Circuits and Systems for Video Technology , 1995 ,5(5) :387 - 395.
[4 ] 惠新叶,郑志航,叶楠,MPEG- 2 运动补偿的VLSI 设计[J ] . 上海交通大学学报,1999 ,7 :903 - 906.
[5 ] 刘龙,韩崇昭,王占辉. MPEG - 4 运动补偿的VLSI 结构设计 [J ] . 通信学报,2005 (11) :117 - 124.
[6 ] Bhasker J . Verilog HDL 综合实用教程[M] . 北京:清华大学出版社,2004.
[7 ] 高文,黄铁军. 心愿编码标准AVS 及其在数字电视中的应用[J ] . 电视技术,2003 (11) :4 - 6.







评论