
语音识别技术的研究与发展
摘 要: 回顾了语音识别技术的发展历史,描述了语音识别系统的基本原理,介绍了语音识别的几种基本方法,并对语音识别技术面临的问题和发展前景进行了讨论。
1 语音识别技术概述
语音识别是解决机器“听懂”人类语言的一项技术。作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。如今,随着语音识别技术研究的突破,其对计算机发展和社会生活的重要性日益凸现出来。以语音识别技术开发出的产品应用领域非常广泛,如声控电话交换、信息网络查询、家庭服务、宾馆服务、医疗服务、银行服务、工业控制、语音通信系统等,几乎深入到社会的每个行业和每个方面。
广泛意义上的语音识别按照任务的不同可以分为4个方向:说话人识别、关键词检出、语言辨识和语音识别[1]。说话人识别技术是以话音对说话人进行区别,从而进行身份鉴别和认证的技术。关键词检出技术应用于一些具有特定要求的场合,只关注那些包含特定词的句子,例如对一些特殊人名、地名的电话监听等。语言辨识技术是通过分析处理一个语音片断以判别其所属语言种类的技术,本质上也是语音识别技术的一个方面。语音识别就是通常人们所说的以说话的内容作为识别对象的技术,它是4个方面中最重要和研究最广泛的一个方向,也是本文讨论的主要内容。
2 语音识别的研究历史及现状
语音识别的研究工作始于20世纪50年代,1952年Bell实验室开发的Audry系统是第一个可以识别10个英文数字的语音识别系统。1959年,Rorgie和Forge采用数字计算机识别英文元音和孤立词,从此开始了计算机语音识别。60年代,苏联的Matin等提出了语音结束点的端点检测,使语音识别水平明显上升;Vintsyuk提出了动态编程,这一提法在以后的识别中不可或缺。60年代末、70年代初的重要成果是提出了信号线性预测编码(LPC)技术和动态时间规整(DTW)技术,有效地解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。
80年代语音识别研究进一步走向深入:HMM模型和人工神经网络(ANN)在语音识别中成功应用。1988年,FULEE Kai等用VQ/I-IMM方法实现了997个词汇的非特定人连续语音识别系统SPHINX。这是世界上第1个高性能的非特定人、大词汇量、连续语音识别系统。
进入90年代后,语音识别技术进一步成熟,并开始向市场提供产品。许多发达国家如美国、日本、韩国以及IBM、Apple、ATT、Microsoft等公司都为语音识别系统的实用化开发研究投以巨资。同时汉语语音识别也越来越受到重视。IBM开发的 ViaVoice和Microsoft开发的中文识别引擎都具有了相当高的汉语语音识别水平。
进入21世纪,随着消费类电子产品的普及,嵌入式语音处理技术发展迅速[2]。基于语音识别芯片的嵌入式产品也越来越多,如Sensory公司的RSC系列语音识别芯片、Infineon公司的Unispeech和Unilite语音芯片等,这些芯片在嵌入式硬件开发中得到了广泛的应用。在软件上,目前比较成功的语音识别软件有:Nuance、IBM的Viavoice和Microsoft的SAPI以及开源软件HTK,这些软件都是面向非特定人、大词汇量的连续语音识别系统。
我国语音识别研究一直紧跟国际水平,国家也很重视。国内中科院的自动化所、声学所以及清华大学等科研机构和高校都在从事语音识别领域的研究和开发。国家863智能计算机专家组为语音识别技术研究专门立项,并取得了高水平的科研成果。我国中科院自动化所研制的非特定人、连续语音听写系统和汉语语音人机对话系统,其准确率和系统响应率均可达90%以上。
3 语音识别系统
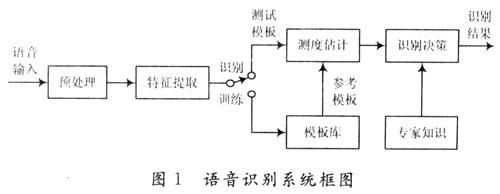
语音识别本质上是一种模式识别的过程,未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。图1是基于模式匹配原理的自动语音识别系统原理框图。
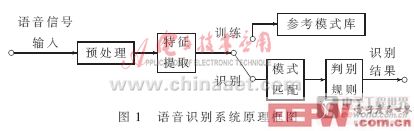
(1)预处理模块:对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行语音信号的端点检测、语音分帧以及预加重等处理。






评论