
在TM1300上实现H.26L的4%26#215;4点整数变换
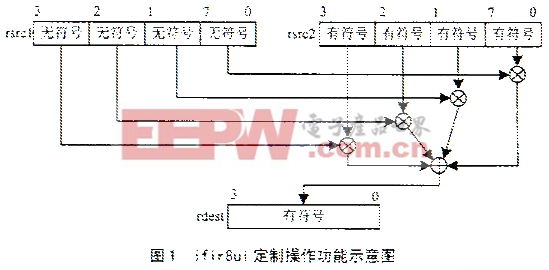 图1为ifir8ui定制操作功能示意图。 3 实验结果 本文提出的基于TM1300的4%26;#215;4整数变换的快速算法,使用了并行算是技术大大减少了计算量。实验表明,进行1个4%26;#215;4点整数变换,直接用乘法和加法运算需要80个机器周期,改进后的算法只需28个机器周期;而利用TM1300进行1个8%26;#215;8点定点DCT变换需要180个机器周期,也明显大于4个4%26;#215;4点整数变换时间。在变换方面H.264的变换编码运算复杂度小于其它编码方法。
图1为ifir8ui定制操作功能示意图。 3 实验结果 本文提出的基于TM1300的4%26;#215;4整数变换的快速算法,使用了并行算是技术大大减少了计算量。实验表明,进行1个4%26;#215;4点整数变换,直接用乘法和加法运算需要80个机器周期,改进后的算法只需28个机器周期;而利用TM1300进行1个8%26;#215;8点定点DCT变换需要180个机器周期,也明显大于4个4%26;#215;4点整数变换时间。在变换方面H.264的变换编码运算复杂度小于其它编码方法。

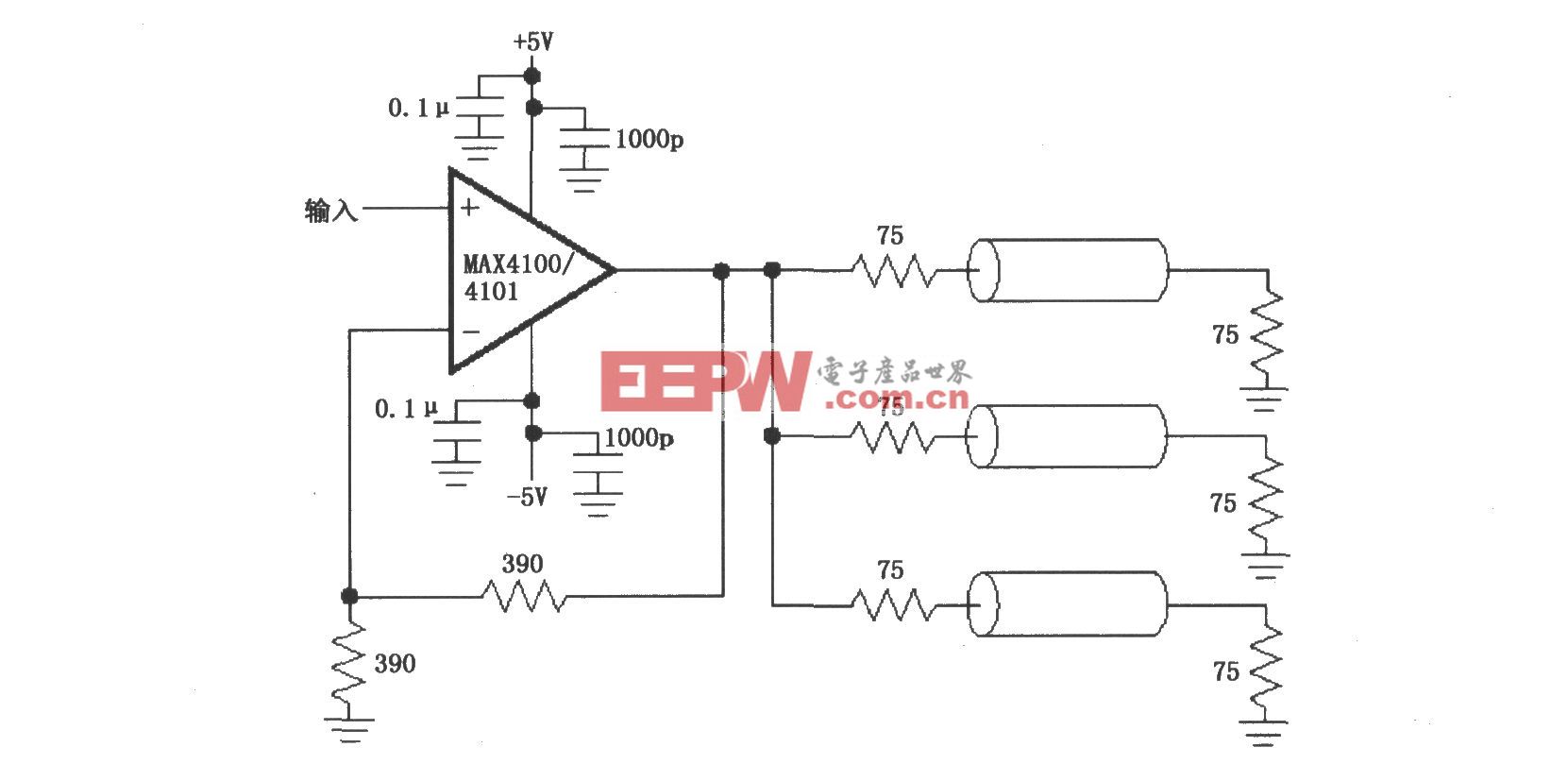

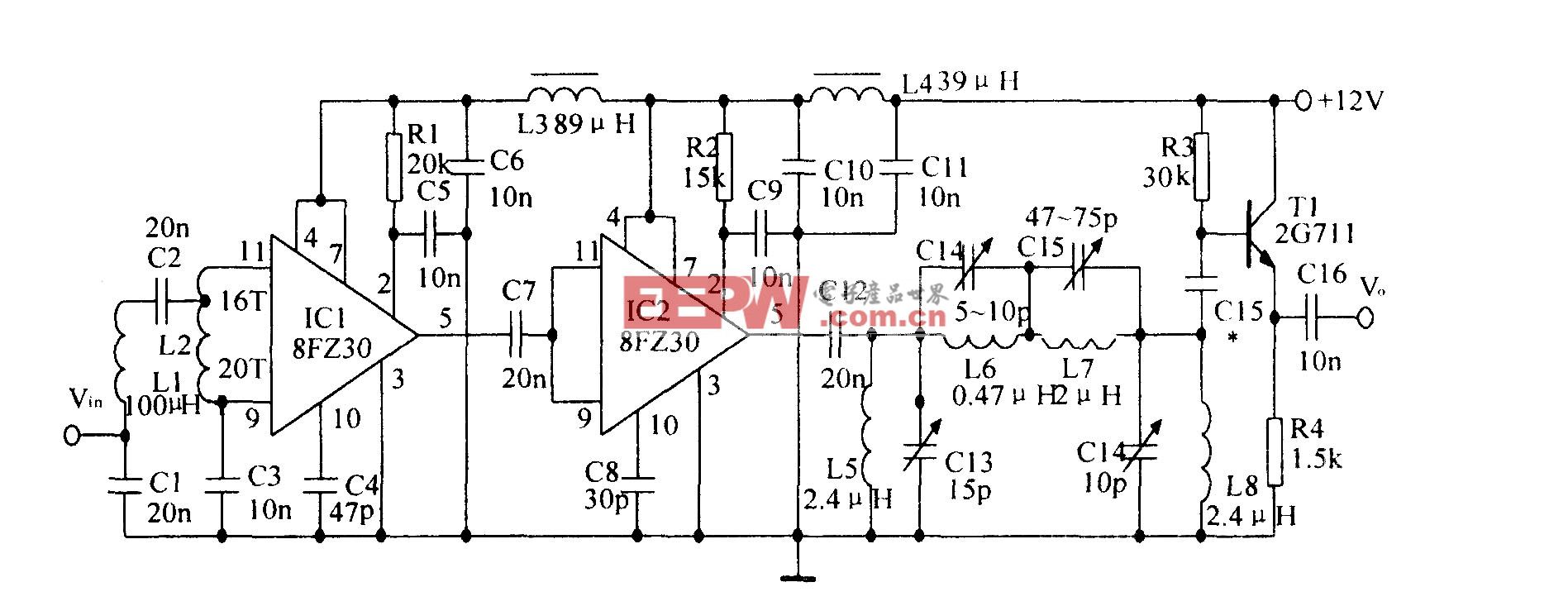




评论