
基于DSP的G.729语音编解码算法的优化和实现
随着多媒体信息技术和网络技术的飞速发展,信息量快速增长,使信道资源显得越来越宝贵。为了在有限的信道资源下传输尽可能多的信息,语音压缩成为必要手段。ITU组织(国际电信联盟)在l996年制定了G.729协议,即共轭结构码激励线性预测编码算法(CS-ACELP)。其编码速率为8kb/s,可以满足网络通信的要求,具有良好的语音质量,对不同的应用环境有较强的适应性,是一种性能较好的语音压缩国际标准,被广泛应用在个人移动通信、卫星通信等各个领域。
1 G.729编解码算法的原理
语音信号的波形编码力图使重建语音波形保持原始语音信号的波形形状。这类编码器通常将语音信号作为一般的波形信号来处理,它具有适应能力强、语音质量好等优点,但所需用的编码速率高。参数编码通过对语音信号特征参数的提取及编码来降低编码速率,力图使重建语音信号尽可能保持原语音的语意,而重建信号的波形同原语音信号的波形可能会有相当大的差别。二十世纪70年代中期,特别是80年代以来,语音编码技术有了突破性的进展,提出了一些非常有效的处理方法,如混合编码。这种算法克服了原有波形编码器与声码器的弱点,而结合了它们各自的长处,在4kb/s~16kb/s速率上能够得到高质量合成语音,而在本质上也具有波形编码的优点。G.729所描述的CS-ACELP(Conjugate-Structure Al2gebraic-Coder-Excited Linear Prediction)声码器采用的CELP声码器就属于这类编码器。
2 算法优化和DSP应用改进
2.1 算法的优化改进
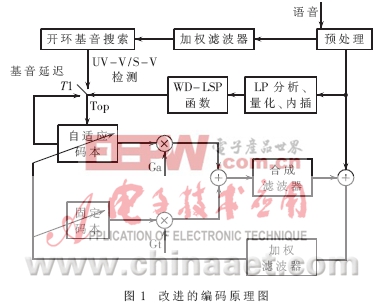
首先在算法上进行改进,如图1所示,采用一种结合WD-LSP(Weighted Delta-LSP)[1]函数并结合次最优部分码本快速搜索的CS-ACELP语音编码算法,同时采用基于声学心理模型的知觉加权滤波器,使语音编码在不降低语音质量的情况下降低计算复杂度。WD-LSP函数主要用于区分UV-V(unvoice-voice)/S-V(silence-voice)的边界。其原理是:如果函数值大于给定的极限值η,则开环基音延迟Top重新估计,否则,开环基音延迟Top用前一帧自适应码本延迟来更新。在第i帧Fi的WD-LSP函数和用于确定开环基音延迟Top的算法如下:

其中LSPi(k)是在第i帧中的k阶LSP系数;wk是加权系数,它用于增强UV-V/S-V边界的WD-LSP函数。为了获取wk,一个包含23 014个UV-V边界和9 519个S-V边界的大型数据库用于估计delta-LSP在UV-V/S-V边界的平方根值(RMS)。因此,WD-LSP用于检测VU-V/S-V边界非常敏感。η是一个设为0.01的极限值。整个计算可节省21%的计算量,经过这种算法前后语音信号如图2所示。

L_32=hi_word16+lo_word1
Hi_word=L_32>>16
Lo_word=L_32-hi_word>>1
当累加器中的数值超过一定范围时将会产生溢出。在G.729算法标准中, 累加器的值被限定在80000000~7FFFFFFF之内——即最小负数和最大正数。不过在TMS320C5416中,如果将PMST寄存器中的OVM置位,则溢出会得到自动处理。





评论