
基于Blackfin561的JPEG2000压缩算法实现及优化
O 引言
JPEG2000数字图像压缩标准是国际标准组织(ISO)和国际电信联盟(ITU)联合制定的新一代静止图像压缩标准。与以往的压缩标准相比,JPEG2000标准具有很多优点。它不仅仅在图像编码过程中能保证良好的图像质量,而且还具有现代图像压缩所要求的新性能,如同时支持有损压缩和无损压缩两种模式、保证在图像传输过程中的容错性、支持感兴趣区域编码等。但是,由于新技术的引入,JPEG2000的算法复杂度也相应提高,在实际应用中,JPEG2000并不如想象中的那么应用广泛。而DSP由于其丰富灵活的指令集、特殊的内部结构、超强的数据吞吐能力及运算速度,使得以DSP处理器为核心的方法成为实现JPEG2000算法的一种有效途径。
1 JPEG2000系统的组成原理
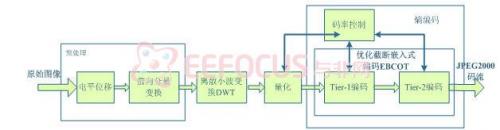
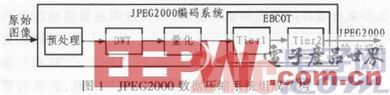
JPEG2000相对于JPEG的最大改进就是以离散小波变换(DWT)代替了DCT编码。JPEG2000的编解码流程如图1所示。本系统首先对源图像数据进行离散小波变换,然后对变换后的小波系数进行量化,接着对量化后的数据熵编码,最后形成输出码流。解码器是编码器的逆过程,解码时,首先对码流进行熵解码,然后解量化和小波反变换,最后生成重建图像数据。
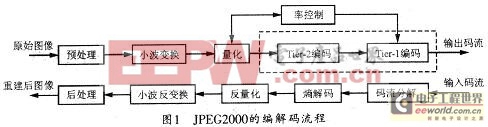
通过预处理可为不同类型的图像提供一个统一的接口,以便于后续使用同样的编码器进行处理,这一步骤是将多种类型的图像压缩加入到统一框架中的关键。它主要包括三个步骤:图像分片、直流平移和分量变换。
小波的多分辨率分析特性使之既可高效地描述图像的平坦区域,又可有效地表示图像信号的局部突变(即图像的边缘轮廓部分),它在空域和频域都有良好的局部性,因而能够聚焦到图像的任意细节。
优化截断嵌入块编码(The Embedded BlockCoding with Optimized Truncation,简称EBCOT)是JPEG2000标准的核心,它不仅能对图像进行有效压缩,同时,其产生的码流还具有分辨率可伸缩性、信噪比可伸缩性、随机访问和处理等非常好的特性。EBCOT分Tierl和Tier2两部分,EBCOT可将子带分成互不重叠的编码块,每个编码块的比特层编码称为Tierl;然后对所有编码块的编码流进行优化截断排序和打包等处理,以使其成为Tier2。
2 Blackfin56l处理器
Blackfin处理器是一类专为满足当今嵌入式音频、视频和通信应用的计算要求和功耗约束条件而设计的新型32位DSP。Blackfin处理器主要基于ADI和Intel公司联合开发的微信号架构(MSA),它将一个32位RISC型指令集和双16位乘法累加(MAC)信号处理功能与通用型微控制器所具有的易用性组合在了一起。Blackfin561是Blackfin处理器系列中的新型对称双核处理器成员,可在相同的频率条件下实现性能的翻番。该器件具有以下特点:
(1)高性能的处理器内核
Blackfin处理器架构基于一个10级RISCMCU/DSP流水线和一个专为实现最佳代码密度而设计的混合16/32位指令集架构。Blackfin561具有两个内核频率可达600MHz的处理器,可提供高效RISC MCU控制任务执行能力。
(2)高带宽DMA能力
Blackfin561具有多个独立的DMA控制器,这些控制器可支持自动数据传输,而且所需的处理器内核开销极少。DMA传输可出现于内部存储器和诸多具有DMA功能的外设之间。传输也有可能出现于外设和与外部存储器接口相连的外部器件之间,包括SDRAM控制器和异步存储器控制器。
(3)专用视频指令
除了具有对8位数据以及许多像素处理算法所常用的字长的固有支持之外,Blackfin处理器架构还包括专为增强视频处理应用而定义的指令。
(4)高效控制处理
Blackfin561提供有各种各样的微控制器型外设,包括UARTS、SPI、PPI控制器、支持PWM的定时器、看门狗定时器、实时时钟和一个无缝同步和异步存储器控制器。因而为设计师提供了巨大的设计灵活性,并最大限度地降低了终端系统成本。
(5)分层的存储器架构
Blackfin561支持改进的哈佛结构,该结构是具有分级的存储器结构的组合。BF56l器件的地址总线宽度为32位,可以访问4G字节的地址空间。Blackfin处理器的存储器架构在器件实现中可提供Level l(L1)和Level 2(L2)存储模块,并可以通过EBIU外接L3处理器(SDRAM、Flash等)。
3 系统设计
本系统主要实现数字图像的采集和压缩处理。它有效利用了Blackfin561的专用视频接口PPI和其它丰富的接口资源,具有设计简单、便于软件编程的特点。图2所示其系统工作流程及连接框图。
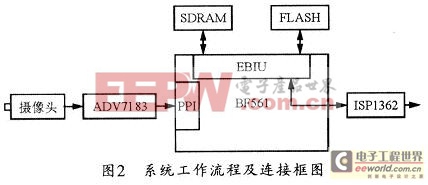
由图2可见,本系统首先由CCD摄像头来采集图像,输入的模拟信号经ADV7183视频编码芯片转换成ITU一656格式的数字视频流,该视频流通过BF561的PPI传输到SDRAM。然后由DSP从SDRAM读入图像,并执行JPEG2000编码操作,最后将压缩视频流输入到输出模块进行传输。输出模块由USB控制芯片ISPl362组成,可以实现系统和PC机的互连。FLASH用来存放加载文件LDR。
4 JPEG2000算法移植
如果用户导入的Blackfin处理器的C代码能够兼容ANSI C语言,那么,就能直接在Blackfin上进行构建并执行这个“现成的”代码程序。但是结合嵌入式应用环境,移植时还需注意以下几点:
首先要注意不同的平台对数据类型的长度定义可能是不一样的。在程序移植中可以对数据类型使用typedef宏进行定义,如“typedef intINT32;”这样便于移植时更改。
其次,因为嵌入式系统中的存储空间有限,而且是分级的,且不同级别的处理器大小和运算速度均不同。因此,在定义变量时需要考虑其存放地址。通过section(“存储器段名”)语句可以将变量和代码放入指定地址。其中“存储器段名”可在ldf件中设置。
第三为了程序调用方便,PC平台下的C程序会经常使用大量的动态内存分配(如calloc、realloc、new等)。考虑到嵌入式系统的特点,即需要不停的循环处理,因此,应该用静态数组代替动态内存分配。这样不仅可以避免动态内存分配造成的内存碎片问题,同时存储结构也更加清楚明了。
此外,由于源程序中有许多文件操作,而嵌入式系统并不直接支持文件操作,所以应予以剔除,用读写数组的方式来替代。
最后应注意Visual DSP++兼容的C语言库函数。由于它不能识别malloc.h>等库文件名称,而calloc、malloc等动态内存分配函数均包含在stdlib.h>中。所以,若要使用malloc,只需在程序中包入stdlib.h>即可。注意以上几点,C语言源程序就可以在VisualDSP++下运行,从而实现其功能了。
5 程序优化
由于移植后的算法只是简单的实现了图像编码功能,而远不能保证其实时性,因而需要对其进行优化。优化主要涉及浮点转定点运算、代码优化和存储器优化。
5.1 浮点运算转定点运算
Blackfin处理器是一款定点处理器。该处理器本身并不支持float、double等浮点数据类型,而只能通过仿真实现,所以,用Blackfln直接进行浮点运算是很费时的。因而应将小波变换及其它涉及浮点运算的模块全部定点化。
可以将浮点系数乘以一个尺度因子,使其变换成整数。然后在运算过程中再除以尺度因子,这样就避免了浮点操作。同时,Blackfin处理器是针对小数形式进行优化设计的,它提供了大量的运算指令,可以快速的执行定点和小数运算。若用汇编编写,则可以充分发挥处理器的性能,优化幅度更大。下面给出小波变换定点化的一段程序:

5.2 代码优化
设计时可以结合具体的硬件环境对代码本身做出大量优化,以使得编译器能够充分的使用硬件循环、软件流水化、矢量化等技术。但是,也应注意一下几个方面:
首先,因为循环是程序中时间消耗最大的部分,所以要把主要精力集中在循环程序的设计上。应尽量使用短循环;避免循环执行的依赖性;确保内部循环次数比外部的多;在循环中应避免条件代码,否则会出现大量控制流延迟;在循环体中不要放函数调用语句,这样会妨碍编译器用硬件循环结构。
其次,定点处理器本身不直接支持除法操作,所以,应该尽量避免除法。如“if(X/Y>A/B)”可以写成“if(X*B>A*Y)”。通过移位操作同样可以避免除法,如除以8可以用左移3位来代替。最后,通过查询表的方法也可以避免一些复杂运算。
5.3 存储器优化
Blackfin56l中的存储器采用分层结构,距离核最近的Ll存储器运行速度最快,但容量很小。因此需要对图像数据进行合理的存储器资源分配,以使得绝大多数操作都集中在L1存储器。下面以小波变换为例来进行说明。
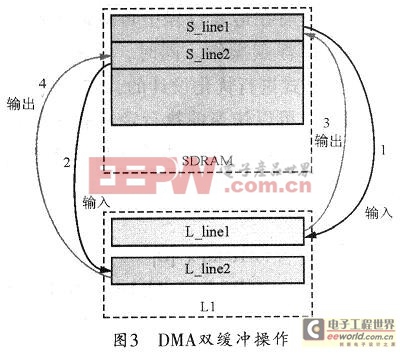
本系统中待处理的图像位于SDRAM中。图3所示是DMA双缓冲操作示意图,DMA优化的总体思想是以一行图像数据为基本单位,然后通过DMA把要处理的数据转移到Ll,实现数据的高效处理。传输可采用双缓冲乒乓操作,这样可避免DMA传输数据所耗费的时间。
为了验证JPEG2000编码器在BF56l上移植和优化后的效果,我们对一幅512x512x8bit图像进行测试并给出了相关数据。表l所列为16倍压缩率下优化前后的数据对比。

6 结束语
JPEG2000是新一代图像压缩国际标准。本设计可实现JPEG2000图像压缩算法在DSP上的移植和优化,压缩后的图像具有较高的信噪比。同时经过优化,其编码器的运算速度也得到了很大的提高,可以满足实际应用的需要。最后的结果。所以,为了在高频输入时,系统也能正常工作,可以把CA3140替换成高频特性比较好的LM616l,这样可以提高系统的高频特性。


评论