
以基于赛灵思 FPGA 的硬件加速技术打造高速系统
设计人员时常需要通过增加计算能力或额外输入(或两者)延长现有的嵌入式系统的寿命。而可编程系统平台在这里大有用武之地。我们曾经希望用安全网络连接功能升级一套网络可编程系统。安全网络连接功能需要加密才能运行安全外壳 (SSH)、传输层安全 (TLS)、安全套接层(SSL) 或虚拟专用网 (VPN) 等协议。这种安全需求与把各种系统接入因特网的需求同步增长,例如,为了启用远程管理与分布式控制系统。
本文引用地址:http://www.amcfsurvey.com/article/236325.htm因该领域仍在发展并且标准尚未固定,因此成本主要取决于一次性工程费用。所以,FPGA 技术能实现最高价值。我们的系统基于 Mi s s i n g L i n k Electronics (MLE) 公司的“软”硬件平台,其FPGA 灵活的 I/O 能够连接各种传感器和执行器。该平台采用可编程逻辑实现片上系统,以 MicroBlaze ™ CPU或 PowerPC® CPU 作为其核心。 CPU 为操作系统与用户空间应用软件运行 MLE Linux 软件栈。由于采用 MicroBlaze 或PowerPC 作为主 CPU,当运行嵌入式Linux 操作系统外加强大加密功能时该系统显然无法提供所需要的计算性能。况且也无法改变物理硬件。为了实现系统加速,我们使用可编程系统把计算从软件域转移到硬件侧。
协处理硬件可编程系统基本上是一个或几个CPU( 运行操作系统与应用软件)的组合,外加一个 FPGA。FPGA 在其中用作灵活的接口“适配器”及协处理硬件。我们可以在单独辅助芯片上实现可编程系统,或者将全部都集成到单个的器件上。我们可以根据 FPGA 器件和 CPU 之间的通信方式,采用不同方法调节系统性能和功能。
其中一种方法就是添加对等处理器,通过内存映射状态和控制寄存器与 CPU实现同步。因为通过同一系统总线运行所有通信会很快降低性能,因此我们实际上希望把 CPU 数据流与对等处理器分开。而采用赛灵思 Central DMA 或多端口储存器控制器 (MPMC) 等片上系统组件能够轻松满足上述愿望。
另外,也可以增加一个协处理器,这种情况下能通过增加自定义指令(也叫编译功能)有效地扩展 CPU 的指令集。例如,它适合浮点单元,而且赛灵思结构协处理器模块 (FCM) 技术能轻松支持上述功能。此处的优势是在 CPU 和协处理器之间使用一条从内存到系统总线的专用通信通道。对于 PowerPC,其为辅助处理单元 (APU),而对于 MicroBlaze,则是快速单工链路 (FSL)。
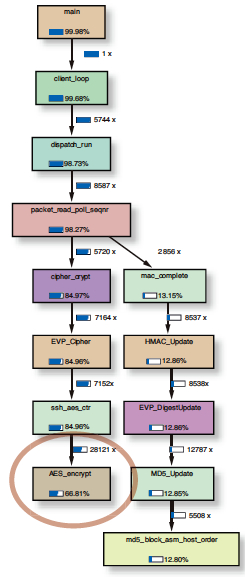
图 1 — 在采用 Valgrind 工具的 SCP 传输中,AES 加密占用三分之二的计算任务。
AES:黄金标准
但是没有重大的系统重新设计,又该如何真正加速加密?
对于加密,高级加密标准 (AES) 是一个事实标准。
采用 AES 加密时,无法通过定义减少计算任务,从而使嵌入式系统很快达到性能极限。如图 1 所示,其中显示用Valgrind 分析工具、通过 SCP(SSH 会话)进行的文件传输的分析结果。此时AES 加密占用三分之二计算任务。
AES-128采用秘钥和 128 位块大小,使用许多并发 8 字节运算。AES 属于分组密码,基于按 4x4 字节阵列组织的固定分组大小运算。我们曾经采用 128位分组大小,它能抵挡所有已知攻击,安全性甚至强于 192 位和 256 位版本。
采用 128 位 AES 时,执行加密与解密需要 12 个回合,每个回合需要几步运算。第一项任务是通过所谓的密匙扩展过程从密钥中算出回合金钥。每个回合都采用纯文本自身的回合密匙执行纯文本的逐位异或运算。然后进行字节代替、行位移和列混合运算,并再次执行回合金钥的异或运算。
最后一个回合稍有不同,因为其中省略了一些步骤。加密过程采用所谓的S 盒(其提供非线性)执行替代。我们可以把它安置到一个 16×16×8 位矩阵中,从而能够适应常见的赛灵思 BRAM原语。多个 S 盒实例可以加速 IP 核并在适当的位置为内核提供所需数据,而无需等待对主存储器的长时间总线存取。解密过程大同小异,其采用相同密钥,但方向相反,并且使用不同 S 盒。
快 12 倍
在加密和解密中,大部分运算按行或列执行,剩下四项运算并行计算 —而硬件对此任务得心应手。这样就能够通过不同来源实现 AES 硬件的各个部分。为了加速系统,我们从庞大、快速增长的 OpenCores.org 资源库获取AES 内核。
我们删除了原有的总线接口(因为它适用于另一种 FPGA 架构),另外为APU 添加了一个接口,以便把 AES 内核作为 FCM 协处理器连接到 PowerPC上。我们共使用 8 个所谓的 UDI 指令在PowerPC 和 AES FCM 之间传输数据。工作结果非常令人满意( 见图2) 。硬件加速的系统比原实现快了12 倍。原来用以 300 MHz运行的独立的 PowerPC 加密一个单块需要 17.8微秒,而采用以 150 MHz 运行的 AESFCM 只需 1.5 微秒。如果只以升级到速度稍快的 CPU来加速运算,我们采用硬件加速后的 1.5 微秒速度表现超过基于 Intel Atom 1.6-GHz CPU 的纯软件实现(其需要 2.7 微秒)。上述结果证明了使用 FPGA 技术的硬件加速的卓越潜能。

图 2 — 硬件加速系统(中间绿条)快于独立的 PowerPC 或 Atom 处理器。










评论