
基于SoPC的嵌入式文字识别系统设计
摘 要: 设计了一种基于SoPC的嵌入式文字识别系统。在FPGA平台下,基于SoPC框架搭建软硬件协同系统,设计硬件电路完成文字图像的采集和预处理,嵌入Linux系统,使用其下的识别引擎完成文字图像的识别。采用Altera公司的SoPC builder构建系统框架,Quartus II完成硬件电路的设计,在宿主机Linux环境下完成了软件部分的交叉编译并嵌入到FPGA平台。整体设计在DE2-70开发板上完成了系统验证。
关键词: 文字识别;可编程逻辑器件;可编程片上系统;Linux
计算机文字识别也被称为光学文字识别[1]OCR(Optical Character Recognition),在智能计算机和办公自动化领域有着极其重要的应用。文字识别的基本原理是通过诸如照相机、扫描仪等图像输入设备获取文字图片,经过图像处理后使用光学模式判别等算法分析文字图片,最后将判断出的文字编码储存起来从而完成文字识别。
文字识别设备对识别速度要求较高,因此图像采集和预处理的速度十分关键。同时对识别率要求高,识别字体种类多,因此选用带学习功能的软件引擎非常重要。另外系统需要交互界面和大量外围设备的驱动,因此需要引入操作系统以方便设计开发。
1 SoPC系统设计
系统功能设计的整体方案如图1所示。各部分功能介绍如下:
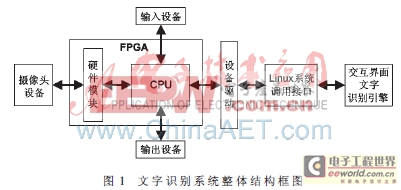
(1)图像采集功能,通过外接的摄像头模块完成图像的采集;
(2)由硬件模块完成文字图像预处理功能,能够对采集的文字图像进行倾斜纠正[2]、图像分割[3]、二值化[4]等处理,保证系统的性能和速度,以提高后续的文字识别率;
(3)文字图像识别功能,能够将文字图像中的文字识别出来并保存在TXT中;
(4)识别结果的存储和发送功能,能够将识别结果文件存入SD卡或U盘中,或者通过网络发送给上位机;
(5)交互界面功能:能够通过LCD模块或者外接的VGA设备等输出设备以及键盘、触摸屏或者鼠标等输入设备与使用者交互。
整个系统由一块FPGA和摄像采集、输入输出等外围设备组成。FPGA硬件模块完成摄像采集控制和图像预处理,CPU作为系统主控控制外设和硬件模块的数据流。文字识别模块和外围设备驱动在Linux平台上进行开发或移植。
本文采用Altera Cyclone2系列的FPGA,通过Altera提供的SoPC技术,可以将Nios Ⅱ软核处理器和外围设备接口IP通过Avalon总线连接起来,并集成在一块FPGA上。图2是系统的SoPC设计。
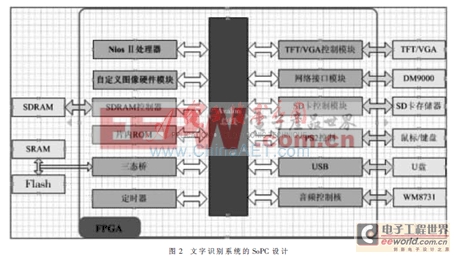
2 系统硬件设计
文字识别硬件设计主要包括文字图像的采集控制和文字图像的预处理。文字图像的预处理又分为边缘检测、倾斜纠正、文字区域提取、二值化。硬件模块总体设计图如图3所示。
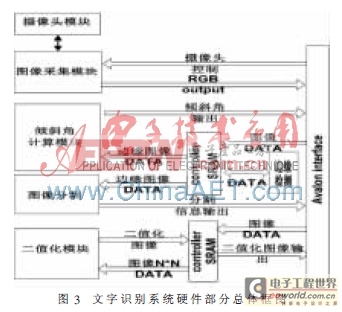
对于待识别的文字图像,影响文字识别准确率的不仅仅是后端引擎的性能,更重要的是文字图像的质量和实际使用的文字图像,除了光照不均匀且有倾斜外,还会有不少干扰信息。因此,本设计选取倾斜纠正、文字图像分割、二值化等预处理方法来减少干扰因素,保证后续文字识别的质量。本设计的处理方法概括如下:
(1)图像边缘就是图像中灰度发生急剧变化的地方。本设计采用一阶导数的Sobel算子的边缘检测算法可以满足设计的需要。本设计中将最后得到的梯度值简化为水平方向梯度绝对值和垂直方向梯度绝对值之和。求出梯度后采用基本全局门限:当某像素点(x,y)的梯度值大于或等于设定的门限T时,规定该点的像素值为1,反之则为0。
(2)文字图像倾斜纠正包括倾斜角计算和图像旋转,即将拍摄中获取的倾斜图像根据倾斜角度进行旋转,最后得到校正后的图像。本设计采用基于Hough的变换来计算倾斜角。基本原理是通过找出图像中通过最多点的直线,即为图像的倾斜角。变换中,将二维图像中的点通过极坐标系表示,而平面坐标系中一条直线上的所有点对应的极坐标系曲线交于极坐标系中唯一一点(ρ,θ),因此,只需要寻找极坐标系中最大值即可。
(3)文字图像的分割可以提取文字信息区域以减少背景等干扰,同时,由于图像区域的减少,对于光照不均匀也有一定的改善。本设计根据文字图像的具体特点设计分割方法,首先将经过倾斜纠正的文字图像通过边缘检测算法得到边缘检测图片;后通过逐行和逐列扫描确定行和列的阈值;接着对所有符合阈值的区域进行分析,相隔较近的区域进行联通,从而确定最终的分割区域。最后根据分割区域对原图进行图像分割。
(4)经过倾斜纠正和图像分割后得到的文字图像仍有光照不均匀和噪声的影响,因此需要进行二值化处理。对图像进行二值化不仅能提高文字识别的精度,对后端引擎的识别速度也有不少的帮助。考虑到实际拍摄的图片光照不均匀的程度较高,使用全局或者混合二值化的效果都不理想,且考虑到硬件实现等因素,本设计采取局部阈值二值化。
3 系统软件设计
本设计软件部分基于嵌入式Linux。首先在NiosⅡ处理器中植入嵌入式Linux;然后在Linux内核中配置外围设备驱动并加入一些自定义的设备驱动;最后基于Linux移植或者开发交互界面、文字识别引擎等。另外,还需要移植bootloader,系统启动后,bootloader将Linux内核搬到SDRAM中运行,从而实现系统开机自启动的功能。
整体流程是:首先将bootloader和Linux内核下载进入Flash,同时设定复位地址为Flash中内核bootloader的入口地址。系统启动时先启动bootloader,初始化外围设备,并通过串口打印输出信息,同时将Linux内核搬运到SDRAM进行解压。Linux内核解压完成后内核启动。只是Linux初始化所有的外围硬件设备,启动nano-X图形接口和nano-wm窗口管理器和基于FLTK的交互界面。交互界面上是各种的按钮选择,包括图片浏览、图像采集、文本浏览编辑、网络连接及文字识别等应用程序的按钮。当按键选择各种功能后会进入相应的功能模块。当程序运行完成后通过选择返回按钮再次进入到交互界面的按键选择部分。
4 系统功能验证
将硬件信息配置进入FPGA,同时通过Flashprogrammer将bootloader和Linux下载到Flash。Linux内核启动完成后,调用交互界面程序,系统可以通过鼠标键盘进行输入操作,通过VGA输出交互界面。此外,可通过串口对系统进行调试并看到打印出来的系统信息。
本设计通过NiosⅡ控制图像采集模块,通过DE2-70开发板上的开关可以调节曝光,采集回的图像通过NiosⅡ写入SD卡,用来验证图像采集模块的功能。开发板和摄像头通过支架固定在文字识别区域上方。实际采集的效果满足应用需求。
由于受DE2-70开发板上SDRAM大小的限制,本设计Tesseract引擎的数据文件不能太大。因此先使用默认引擎进行英文的识别,然后用拍摄的几幅文字图像对引擎进行训练;再使用经过训练的引擎对图像进行识别。最终的图像识别结果存入SD卡中。文字识别的效果图如图4所示。

图4(a)是默认引擎的识别效果图,图4(b)是经过训练的引擎识别效果图。通过对比可以看出,未经训练的识别效果错误率高达18.59%,而经过训练的引擎识别效果明显好于默认引擎识别的结果,错误率仅为7.7%。但是在一些图像伪影和不连续处,两个引擎都出现了不同程度的错误。其原因在于目前的文字识别理论还尚未成熟,难以达到百分之百的文字识别精确度。
本文通过硬件电路完成文字图像采集和文字图像预处理,嵌入式软件完成文字识别,实现了一种基于SoPC的嵌入式文字识别系统。此设计中构建了完整的SoPC系统,嵌入了Linux操作系统,通过软硬件协同充分发挥各自的优点,达到了较好的文字识别效果。




评论