
基于16位单片机的语音电子门锁系统
 1 算法原理 说话人识别算法原理框图如图1所示。 1.1 预处理 (1)去噪 对麦克风输入的模拟语音信号进行量化和采样,获得数字化的语音信号;再将含噪的语音信号通过去噪处理,得到干净的语音信号后并通过预加重技术滤除低频干扰,尤其是50Hz或60Hz的工频干扰,提升语音信号的高频部分,而且它还可以起到消除直流漂移、抑制随机噪声和提升清音部分能量的作用。 (2)端点检测 本系统采用语音信号的短时能量和短时过零率进行端点检测。语音信号的采样频率为8kHz,每帧数据为20ms,共计160个采样点。每隔20ms计算一次短时能量和短时过零率。通过对语音信号的短时能量和短时过零率检测可以剔除掉静默帧、白噪声帧和清音帧,最后保留对求取基音、LPCC等特征参数非常有用的浊音信号。 1.2 特征提取 在语音信号预处理后,接着是特征参数的提取。特征提取的任务就是提取语音信号中表征人的基本特征。 1.2.1 特征参数的选取 选取的特征必须能够有效地区分不同的说话人,且对同一说话人的变化保持相对稳定,同时要求特征参数计算简便,最好有高效快速算法,以保证识别的实时性。 说话人特征大体可归为下述几类: (1)基于发声器官如声门、声道和鼻腔的生理结构而提取的参数。如谱包络、基音、共振峰等。其中基音能够很好地刻画说话人的声带特征,在很大程度上反映了人的个性特征。 (2)基于声道特征模型,通过线性预测分析得到的参数。包括线性预测系数(LPC)以及由线性预测导出的各种参数,如线性预测倒谱系数(LPCC)、部分相关系数、反射系数、对数面积比、LSP线谱对、线性预测残差等。根据前人的工作成果和实际测试比较,LPCC参数不但能较好地反馈声道的共振峰特性,具有较好地识别效果,而且可以用比较简单的运算和较快的速度求得。 (3)基于人耳的听觉机理,反映听觉特性,模拟人耳对声音频率感知的特征参数。如美国尔倒谱系数(MFCC)等。MFCC参数与基于线性预测的倒谱分析相比,突出的优点是不依赖全极点语音产生模型的假定,在与广西无关的说话人识别系统中MFCC参数能够比LPCC参数更好地提高系统的识别性能。 此外,人们还通过对不同特征参数量的组合来提高实际系统的性能。当各组合参量间相关性不大时,会有较好的效果,因为它们分别反映了语音信号的不同特征。 在计算机平台的仿真实验中,通过各种参数的实际比较,采用MFCC参数比采用LPCC参数有更好的识别效果。但在SPCE061A平台上做实时处理时,与LPCC系统相比,MFCC系数计算有两个缺点:一是计算时间长;二是精度难以保证。由于MFCC系统的计算需要FFT变换和对数操作,影响了计算的动态范围;要保证系统识别的实时性,就只有牺牲参数精度。而LPCC参数的计算有递推公式,速度和精度都可以保证,识别效果也满足实际需要。 本系统采用了基音周期和线性预测倒谱系数(LPCC)共同作为说话人识别的特征参数。 1.2.2 LPCC参数的提取 基于线性预测分析的倒谱参数LPCC可以通过简单的递推公式由线性预测系数求得。递推公式如下:
1 算法原理 说话人识别算法原理框图如图1所示。 1.1 预处理 (1)去噪 对麦克风输入的模拟语音信号进行量化和采样,获得数字化的语音信号;再将含噪的语音信号通过去噪处理,得到干净的语音信号后并通过预加重技术滤除低频干扰,尤其是50Hz或60Hz的工频干扰,提升语音信号的高频部分,而且它还可以起到消除直流漂移、抑制随机噪声和提升清音部分能量的作用。 (2)端点检测 本系统采用语音信号的短时能量和短时过零率进行端点检测。语音信号的采样频率为8kHz,每帧数据为20ms,共计160个采样点。每隔20ms计算一次短时能量和短时过零率。通过对语音信号的短时能量和短时过零率检测可以剔除掉静默帧、白噪声帧和清音帧,最后保留对求取基音、LPCC等特征参数非常有用的浊音信号。 1.2 特征提取 在语音信号预处理后,接着是特征参数的提取。特征提取的任务就是提取语音信号中表征人的基本特征。 1.2.1 特征参数的选取 选取的特征必须能够有效地区分不同的说话人,且对同一说话人的变化保持相对稳定,同时要求特征参数计算简便,最好有高效快速算法,以保证识别的实时性。 说话人特征大体可归为下述几类: (1)基于发声器官如声门、声道和鼻腔的生理结构而提取的参数。如谱包络、基音、共振峰等。其中基音能够很好地刻画说话人的声带特征,在很大程度上反映了人的个性特征。 (2)基于声道特征模型,通过线性预测分析得到的参数。包括线性预测系数(LPC)以及由线性预测导出的各种参数,如线性预测倒谱系数(LPCC)、部分相关系数、反射系数、对数面积比、LSP线谱对、线性预测残差等。根据前人的工作成果和实际测试比较,LPCC参数不但能较好地反馈声道的共振峰特性,具有较好地识别效果,而且可以用比较简单的运算和较快的速度求得。 (3)基于人耳的听觉机理,反映听觉特性,模拟人耳对声音频率感知的特征参数。如美国尔倒谱系数(MFCC)等。MFCC参数与基于线性预测的倒谱分析相比,突出的优点是不依赖全极点语音产生模型的假定,在与广西无关的说话人识别系统中MFCC参数能够比LPCC参数更好地提高系统的识别性能。 此外,人们还通过对不同特征参数量的组合来提高实际系统的性能。当各组合参量间相关性不大时,会有较好的效果,因为它们分别反映了语音信号的不同特征。 在计算机平台的仿真实验中,通过各种参数的实际比较,采用MFCC参数比采用LPCC参数有更好的识别效果。但在SPCE061A平台上做实时处理时,与LPCC系统相比,MFCC系数计算有两个缺点:一是计算时间长;二是精度难以保证。由于MFCC系统的计算需要FFT变换和对数操作,影响了计算的动态范围;要保证系统识别的实时性,就只有牺牲参数精度。而LPCC参数的计算有递推公式,速度和精度都可以保证,识别效果也满足实际需要。 本系统采用了基音周期和线性预测倒谱系数(LPCC)共同作为说话人识别的特征参数。 1.2.2 LPCC参数的提取 基于线性预测分析的倒谱参数LPCC可以通过简单的递推公式由线性预测系数求得。递推公式如下: 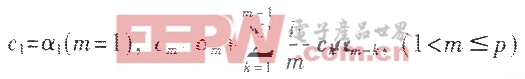 其中p为LPC模型的阶数,也是模型的极点个数。 (1)LPC模型阶数p的确定 为使模型假定更好地符合语音产生模型,应该使LPC模型的阶数p与共振峰个数相吻合,其次是考虑声门脉冲形状和口唇辐射影响的补偿。通常一对极点对应一个共振峰,10kHz采样的语音信号通常有5个共振峰,取p=10,对于8kHz采样的语音信号可取p=8。此外为了弥补鼻音中存在的零点以及其他因素引起的偏差,通常在上述阶数的基础上再增加两个极点,即分别是p=12和p10。实验表明,选择LPC分析阶数p=12,对绝大多数语音信号的声道模型可以足够近似地逼近。P值选得过大虽然可以略微改善逼近效果,但也带来一些负作用,一方面是加大了计算量,另一方面有可能增添一些不必要的细节。 (2)线性预测系数的求取 自相关解法主要有杜宾(Durbin)算法、格型(Lattice)算法和舒尔(Schur)算法等几种递推算法。其中在杜宾算法是目前最常用的算法,而且在求取LPC系数时计算量也量小,本系统采用该递推算法。图21.2.3 基音参数的提取 基音估计的方法很多,主要有基于短时自相关函数和基于短时平均幅度差函数(AMDF)等基音估计方法。 (1)基于短时自相关函数的基音估计 短时自相关函数在基音周期的整数倍位置存在较大的峰值,只要找出第一最大峰值的位置就可以估计出基音周期。 (2)基于短时平均幅度差函数(AMDF)的基音估计 基于短时平均幅度差函数(AMDF)在基音周期的整数倍位置存在较大的谷值,找到第一最大谷值的位置就可以估计出基音周期。这种方法的缺点是当语音信号的幅度快速变化时,AMFD函数的谷值深度会减小,从而影响基音估计的精度。 实际上第一最大峰(谷)值点的位置有时并不能与基音周期吻合,第一最大峰(谷)值点的位置与短时窗的长度有关且会受到共振峰的干扰。一般窗长至少应大于两个基音周期,才可能获得较好的估计效果。语音中最长基音周期值约为20ms,本系统在估计基音周期时窗长选择40ms。为了减小共振峰的影响,首先对语音进行频率范围为[60,900]Hz的带通滤波。因为最高基音频率为450Hz,所以将上限频率设为900Hz可以保留语音的一、二次谐波,下降频率为60Hz是为了滤除50Hz的电源干扰。 以上两种方法都是对语音信号本身求相应的函数。本系统采用的基音估计方法是:首先对带通滤波后的短时语音信号进行线性预测,求取预测残差;再对残差信号求自相关函数,找出第一最大峰值点的位置,即得到该段语音的基音估计值。实验表明,通过残差求取的基音轨迹比直接通过语音求取的基音轨迹效果更好,如图2所示。图2中横坐标为语音帧数,纵坐标为8000/f,其中f为基音频率。
其中p为LPC模型的阶数,也是模型的极点个数。 (1)LPC模型阶数p的确定 为使模型假定更好地符合语音产生模型,应该使LPC模型的阶数p与共振峰个数相吻合,其次是考虑声门脉冲形状和口唇辐射影响的补偿。通常一对极点对应一个共振峰,10kHz采样的语音信号通常有5个共振峰,取p=10,对于8kHz采样的语音信号可取p=8。此外为了弥补鼻音中存在的零点以及其他因素引起的偏差,通常在上述阶数的基础上再增加两个极点,即分别是p=12和p10。实验表明,选择LPC分析阶数p=12,对绝大多数语音信号的声道模型可以足够近似地逼近。P值选得过大虽然可以略微改善逼近效果,但也带来一些负作用,一方面是加大了计算量,另一方面有可能增添一些不必要的细节。 (2)线性预测系数的求取 自相关解法主要有杜宾(Durbin)算法、格型(Lattice)算法和舒尔(Schur)算法等几种递推算法。其中在杜宾算法是目前最常用的算法,而且在求取LPC系数时计算量也量小,本系统采用该递推算法。图21.2.3 基音参数的提取 基音估计的方法很多,主要有基于短时自相关函数和基于短时平均幅度差函数(AMDF)等基音估计方法。 (1)基于短时自相关函数的基音估计 短时自相关函数在基音周期的整数倍位置存在较大的峰值,只要找出第一最大峰值的位置就可以估计出基音周期。 (2)基于短时平均幅度差函数(AMDF)的基音估计 基于短时平均幅度差函数(AMDF)在基音周期的整数倍位置存在较大的谷值,找到第一最大谷值的位置就可以估计出基音周期。这种方法的缺点是当语音信号的幅度快速变化时,AMFD函数的谷值深度会减小,从而影响基音估计的精度。 实际上第一最大峰(谷)值点的位置有时并不能与基音周期吻合,第一最大峰(谷)值点的位置与短时窗的长度有关且会受到共振峰的干扰。一般窗长至少应大于两个基音周期,才可能获得较好的估计效果。语音中最长基音周期值约为20ms,本系统在估计基音周期时窗长选择40ms。为了减小共振峰的影响,首先对语音进行频率范围为[60,900]Hz的带通滤波。因为最高基音频率为450Hz,所以将上限频率设为900Hz可以保留语音的一、二次谐波,下降频率为60Hz是为了滤除50Hz的电源干扰。 以上两种方法都是对语音信号本身求相应的函数。本系统采用的基音估计方法是:首先对带通滤波后的短时语音信号进行线性预测,求取预测残差;再对残差信号求自相关函数,找出第一最大峰值点的位置,即得到该段语音的基音估计值。实验表明,通过残差求取的基音轨迹比直接通过语音求取的基音轨迹效果更好,如图2所示。图2中横坐标为语音帧数,纵坐标为8000/f,其中f为基音频率。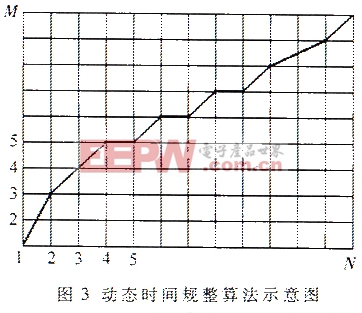 1.3 模式匹配 目前针对各种特征参数提出的模式匹配方法的研究越来越深入。典型的方法有:矢量量化方法、高斯混合模型方法、隐马尔可夫模型方法、动态时间规整(DTW)方法和人工神经网络方法。 这些方法都有各自的优点和缺点。其中DTW算法对于较长语音的识别,模板匹配运算量太大,但对短语音(有效语音长度低于3s)的识别既简单又有效,而且并不比其他方法识别率低,特别适用于短语音、与文本有关的说话人识别系统。本系统采用端点松驰两点的(DTW)算法,端点松驰引起的计算量增加并不大,还可以放松对端点检测的精度要求。 动态时间规整(DTW)算法基于动态规划的思想,解决了说话人不同时期发音长短、语速不一样的匹配问题。DTW算法用于计算两个长度不同的模板之间的相似程度,用失真距离表示。假设测试模板和参考模板分别用T和R表示,按时间顺序含有N帧和M帧的语音参数(本系统为12维LPCC参数),失真距离越小,表示T、R越接近。把测试模板的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧号m=1~M在纵轴上标出,如图3所示。通过这些表示帧号的整数坐标画出纵横线即形成网络,网格中的每一个交叉点(n,m)表示测试模板中某一帧与参考模式中某一帧的交会点,对应两个向量的欧氏距离。DTW算法可以归结为寻找一条通过此网格中若干交叉点的路径,使得该路径上节点的距离和(即失真距离)为最小。对于端点松弛的情况,路径搜索原理相同,只是增加了搜索路径。 2 硬件系统 语音电子门锁系统的核心是说话人识别模块。包括按键输入、语音信号采集、语音信号处理、FLASH存储扩展、扬声器输出、控制输出以及LCD模组等。说话人识别模型的原理框图如图4所示。其核心为语音信号处理,本系统选用特别适用于数字语音识别领域的凌阳16位单片机SPCE061A,并通过SPCE061A实现对其他各组成部分的编程控制。 SPCE061A是凌阳公司开发的一种性价比非常高的16位单片机。在2.6V~3.6V工作电压范围内,工作频率范围为0.32MHz~49.152Mhz,较高的处理速度使其能够非常容易、快速地处理复杂的数字信号;中断系统支持10个中断向量以及14个可来自系统时钟、定时器/计数器、时间基准发生器、外部中断、键唤醒、通用异步串行通信及软件中断的中断源,非常适合实时应用领域;内嵌2K字的SRAM和32K字的FLASH,具有32位可编程的多功能I/O端口;包含有7通道10位通用A/D转换器和内置麦克风放大器与自动增益控制AGC功能的单通道声音A/D转换器,以及具有音频输出功能的双通道10位D/A转换器;SPCE061A采用CMOS制造工艺,同时增加了软件激发的弱振方式、空闲方式和掉电方式,系统处于备用状态下(时钟处于停止状态),耗电仅为2μA3.6V,极大地降低了其功耗;另外,μ’nSPTM的指令系统还提供具有较高运算速度的16位%26;#215;16位的乘法运算指令和内积运算指令,为其应用增添了DSP功能,在复杂的数字信号处理方面既非常便利,又比专用的DSP芯片便宜得多. 说话人识别模块各组成部分完成的功能如下: (1)按键输入部分:共有数字键、训练键、删除键、确认键和取消键等16个按键,用于密码输入和工作模式选择。采用4%26;#215;4矩阵式键盘输入,只使用具有键唤醒功能IOA的低8位,可以合理利用硬件资源,且编程灵活。 (2)语音信号采集部分:通过SPCE061A内置麦克风放大器与自动增益控制AGC功能的单通道声音A/D转换器完成8kHz语音信号采集。 (3)FLASH存储扩展部分:用于存储说话人的个性特征参数参考模板。 (4)扬声器输出部分:通过SPCE061A具有音频输出功能的双通道10位D/A转换器完成用户训练、识别等各种操作的语音提示。 (5)控制输出部分:通过SPCE061A的可编程I/O口控制门锁控制电机。 (6)LCD模组部分:用以显示系统的工作状态,该部分根据成本和实际需要可选。
1.3 模式匹配 目前针对各种特征参数提出的模式匹配方法的研究越来越深入。典型的方法有:矢量量化方法、高斯混合模型方法、隐马尔可夫模型方法、动态时间规整(DTW)方法和人工神经网络方法。 这些方法都有各自的优点和缺点。其中DTW算法对于较长语音的识别,模板匹配运算量太大,但对短语音(有效语音长度低于3s)的识别既简单又有效,而且并不比其他方法识别率低,特别适用于短语音、与文本有关的说话人识别系统。本系统采用端点松驰两点的(DTW)算法,端点松驰引起的计算量增加并不大,还可以放松对端点检测的精度要求。 动态时间规整(DTW)算法基于动态规划的思想,解决了说话人不同时期发音长短、语速不一样的匹配问题。DTW算法用于计算两个长度不同的模板之间的相似程度,用失真距离表示。假设测试模板和参考模板分别用T和R表示,按时间顺序含有N帧和M帧的语音参数(本系统为12维LPCC参数),失真距离越小,表示T、R越接近。把测试模板的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧号m=1~M在纵轴上标出,如图3所示。通过这些表示帧号的整数坐标画出纵横线即形成网络,网格中的每一个交叉点(n,m)表示测试模板中某一帧与参考模式中某一帧的交会点,对应两个向量的欧氏距离。DTW算法可以归结为寻找一条通过此网格中若干交叉点的路径,使得该路径上节点的距离和(即失真距离)为最小。对于端点松弛的情况,路径搜索原理相同,只是增加了搜索路径。 2 硬件系统 语音电子门锁系统的核心是说话人识别模块。包括按键输入、语音信号采集、语音信号处理、FLASH存储扩展、扬声器输出、控制输出以及LCD模组等。说话人识别模型的原理框图如图4所示。其核心为语音信号处理,本系统选用特别适用于数字语音识别领域的凌阳16位单片机SPCE061A,并通过SPCE061A实现对其他各组成部分的编程控制。 SPCE061A是凌阳公司开发的一种性价比非常高的16位单片机。在2.6V~3.6V工作电压范围内,工作频率范围为0.32MHz~49.152Mhz,较高的处理速度使其能够非常容易、快速地处理复杂的数字信号;中断系统支持10个中断向量以及14个可来自系统时钟、定时器/计数器、时间基准发生器、外部中断、键唤醒、通用异步串行通信及软件中断的中断源,非常适合实时应用领域;内嵌2K字的SRAM和32K字的FLASH,具有32位可编程的多功能I/O端口;包含有7通道10位通用A/D转换器和内置麦克风放大器与自动增益控制AGC功能的单通道声音A/D转换器,以及具有音频输出功能的双通道10位D/A转换器;SPCE061A采用CMOS制造工艺,同时增加了软件激发的弱振方式、空闲方式和掉电方式,系统处于备用状态下(时钟处于停止状态),耗电仅为2μA3.6V,极大地降低了其功耗;另外,μ’nSPTM的指令系统还提供具有较高运算速度的16位%26;#215;16位的乘法运算指令和内积运算指令,为其应用增添了DSP功能,在复杂的数字信号处理方面既非常便利,又比专用的DSP芯片便宜得多. 说话人识别模块各组成部分完成的功能如下: (1)按键输入部分:共有数字键、训练键、删除键、确认键和取消键等16个按键,用于密码输入和工作模式选择。采用4%26;#215;4矩阵式键盘输入,只使用具有键唤醒功能IOA的低8位,可以合理利用硬件资源,且编程灵活。 (2)语音信号采集部分:通过SPCE061A内置麦克风放大器与自动增益控制AGC功能的单通道声音A/D转换器完成8kHz语音信号采集。 (3)FLASH存储扩展部分:用于存储说话人的个性特征参数参考模板。 (4)扬声器输出部分:通过SPCE061A具有音频输出功能的双通道10位D/A转换器完成用户训练、识别等各种操作的语音提示。 (5)控制输出部分:通过SPCE061A的可编程I/O口控制门锁控制电机。 (6)LCD模组部分:用以显示系统的工作状态,该部分根据成本和实际需要可选。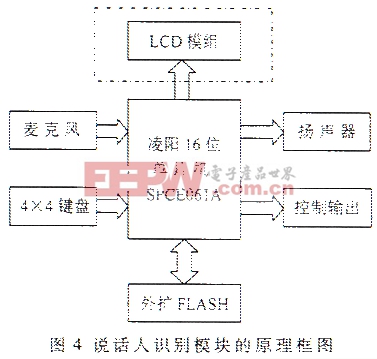 (7)SPCE061A:说话人的语音信号处理以及各部分的编程控制均由SPCE061A完成。 说话人识别模块有三种工作模式:训练模式、认证模式和密码模式,这三种模式都可通过工作模式按键选择。 (1)训练模式,说话人的声音通过麦克风进入语音信号采集前端电路。第一次语音输入时,由16位单片机SPCE061A对采集的语音信号进行处理,提取说话人的个性特征参数,并存储到外扩的FLASH内,形成说话人特征参数模板。可以进行三次训练,第二语音输入时,提取的个数特征参数与由第一次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将说话人特征参数模板更新为两次特征参数的平均值。第三次语音输入时,提取的个性特征参数与由第一、二次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将说话人特征参数模板更新为三次特征参数的平均值,形成最后的该说话人的特征参数模板。 (2)认证模式,同样通过麦克风录入说话人的声音,再由SPCE061A对采集的语音信号进行处理,将提取的说话人特征参数与存储在外扩FLASH内的特征参数模板进行匹配,匹配距离小于认证阈值时,通过认证;然后再判断匹配距离是否小于认证模式下的模板更新阈值,决定是否对模板进行更新。 (3)密码工作模式,在说话人感冒或其他使其声音发生暂时改变的情况下,可以采用长密码方式进行认证,以免因为非常原因被拒之门外。 另外,每个用户都有一个短密码(用户可自行修改),无论在训练模式还是认证模式都要输入此密码,以形成或找到与该用户相对应的特征参数模板。系统还设置一个具有长密码的超级管理员用户,可以通过键盘对用户模板进行添加或删除。 3 实验结果 对于说话人确认系统,表征其性能的最重要的两个参量是拒识率和误识率。前者是拒绝真实的说话人而造成的错误,后者是接受假冒者而造成的错误,二者与匹配阈值的设定相关。匹配阈值的设定与语音锁系统的应用场合、功能侧重有关,对于家庭、宾馆等门锁用户,要求误识率尽可能低,甚至为零;若用于公司员工考勤等同类功能,就不能有太高的拒识率。表1是对以下每种情况各进行100次实时匹配的结果,其中设定的阈值适合门锁用户。表1 100次实时匹配结果 发音分类次数同一个人相同发音同一个人相似发音同一个人不同发音不同人相同发音不同人相似发音不同人不同发音拒绝次数885100100100100接受次数92150000由以上实验结果可知,对于同一个人相同发送的拒识率为8%;对于同一个人相似发音情况,因为系统是对说话的人进行判别,对于这种情况,无论拒绝或接受都是合理的;对于同一个人不同发音和不同人发音的情况,误识率为零。使用录音机进行多次实验,通过认证的次数为零。对于门锁用户,这个结果十分理想的。若用于考勤等同类功能,可通过修改匹配阈值值实现。 声纹识别与其他生物识别技术相比,除具有不会遗失和忘记、不需记忆、使用方便等优点外,还具有以下特性:用户接受程度高,由于不涉及隐私问题,用户无任何心理障碍;声音输入设备造价低廉,而其他生特识别技术的输入设备通常造价昂贵。与利用虹膜、指纹和人脸等技术的门锁相比,基于SPCE061A构建的语音电子门锁系统具有成本低、使用方便、保密性好等优点。经大量实验测试表明,该系统性能稳定、识别效果好。下一步将进行小批量的试用,以发现问题并加以完善。但是,在环境噪声或干扰信号高于语音信号时,该系统将无法进行正确的语音识别,在背景噪声处理及其工程实际上还要进一步改进。
矢量控制相关文章:矢量控制原理
(7)SPCE061A:说话人的语音信号处理以及各部分的编程控制均由SPCE061A完成。 说话人识别模块有三种工作模式:训练模式、认证模式和密码模式,这三种模式都可通过工作模式按键选择。 (1)训练模式,说话人的声音通过麦克风进入语音信号采集前端电路。第一次语音输入时,由16位单片机SPCE061A对采集的语音信号进行处理,提取说话人的个性特征参数,并存储到外扩的FLASH内,形成说话人特征参数模板。可以进行三次训练,第二语音输入时,提取的个数特征参数与由第一次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将说话人特征参数模板更新为两次特征参数的平均值。第三次语音输入时,提取的个性特征参数与由第一、二次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将说话人特征参数模板更新为三次特征参数的平均值,形成最后的该说话人的特征参数模板。 (2)认证模式,同样通过麦克风录入说话人的声音,再由SPCE061A对采集的语音信号进行处理,将提取的说话人特征参数与存储在外扩FLASH内的特征参数模板进行匹配,匹配距离小于认证阈值时,通过认证;然后再判断匹配距离是否小于认证模式下的模板更新阈值,决定是否对模板进行更新。 (3)密码工作模式,在说话人感冒或其他使其声音发生暂时改变的情况下,可以采用长密码方式进行认证,以免因为非常原因被拒之门外。 另外,每个用户都有一个短密码(用户可自行修改),无论在训练模式还是认证模式都要输入此密码,以形成或找到与该用户相对应的特征参数模板。系统还设置一个具有长密码的超级管理员用户,可以通过键盘对用户模板进行添加或删除。 3 实验结果 对于说话人确认系统,表征其性能的最重要的两个参量是拒识率和误识率。前者是拒绝真实的说话人而造成的错误,后者是接受假冒者而造成的错误,二者与匹配阈值的设定相关。匹配阈值的设定与语音锁系统的应用场合、功能侧重有关,对于家庭、宾馆等门锁用户,要求误识率尽可能低,甚至为零;若用于公司员工考勤等同类功能,就不能有太高的拒识率。表1是对以下每种情况各进行100次实时匹配的结果,其中设定的阈值适合门锁用户。表1 100次实时匹配结果 发音分类次数同一个人相同发音同一个人相似发音同一个人不同发音不同人相同发音不同人相似发音不同人不同发音拒绝次数885100100100100接受次数92150000由以上实验结果可知,对于同一个人相同发送的拒识率为8%;对于同一个人相似发音情况,因为系统是对说话的人进行判别,对于这种情况,无论拒绝或接受都是合理的;对于同一个人不同发音和不同人发音的情况,误识率为零。使用录音机进行多次实验,通过认证的次数为零。对于门锁用户,这个结果十分理想的。若用于考勤等同类功能,可通过修改匹配阈值值实现。 声纹识别与其他生物识别技术相比,除具有不会遗失和忘记、不需记忆、使用方便等优点外,还具有以下特性:用户接受程度高,由于不涉及隐私问题,用户无任何心理障碍;声音输入设备造价低廉,而其他生特识别技术的输入设备通常造价昂贵。与利用虹膜、指纹和人脸等技术的门锁相比,基于SPCE061A构建的语音电子门锁系统具有成本低、使用方便、保密性好等优点。经大量实验测试表明,该系统性能稳定、识别效果好。下一步将进行小批量的试用,以发现问题并加以完善。但是,在环境噪声或干扰信号高于语音信号时,该系统将无法进行正确的语音识别,在背景噪声处理及其工程实际上还要进一步改进。
矢量控制相关文章:矢量控制原理





评论