
基于ARM和DSP架构的多处理器高速通讯协议设计
虽然DSP具备众多的优点, 但却不适合作系统控制,因为DSP通常没有强大的操作系统,没有完备的网络协议栈和可靠的文件系统,DSP架构在作控制指令时无法并行处理,分支判断和高速缓存没命中(cache miss)都会使运行效率极大降低。而这些正好是嵌入式RISC处理器的强项,比如ARM和MIPS系列,所以现在很多国际知名的半导体公司如PHILIPS和TI都推出了整合了RISC处理器和DSP的SOC芯片,如PNX8550、PNX8525、OMAP等。
高性能的DSP在进行媒体处理时会产生和消费大量的音视频数据,这些数据需要在RISC 和DSP两个处理器之间高速、稳定地交换数据,另外,RISC处理器也要经常给DSP发送指令,并且还要支持来自DSP的RPC调用。下面本文将要介绍一种基于多处理器之间的高速通讯机制,并且已在实践中得到商业化的应用。
本方案采用了SAMSUNG的S3C2510(ARM940T内核)和PHILIPS的Trimedia1300(TM1300) 数字信号处理器,ARM940T内置了PCI2.1规范的总线接口,Trimedia1300可以作为PCI的MASTER和SLAVE,基本架构如图-1。
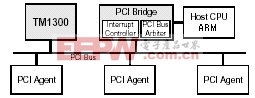
图-1
基于上述的硬件架构,在ARM和Trimedia1300处理器上分别采用了WindRiver的实时嵌入式操作系统(RTOS)vxWorks和pSos2.5,本通讯协议的基本思路为,在ARM的内存空间上开辟一块共享内存,并能使TRIMEDIA能够访问,数据通讯的握手协议通过两个处理器的中断来实现,配合信号量的使用,可以达到高速、高效通讯的目的,其软件架构如图-2。 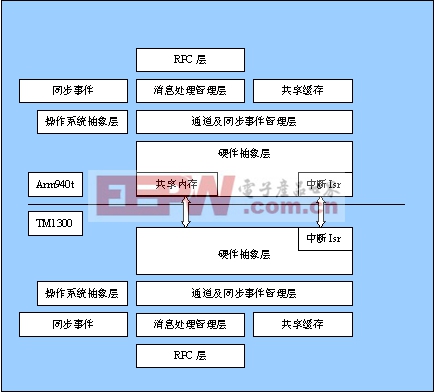
图-2
该通讯协议采用分层分布,两个处理器基本处于对称状态,因此,主要软件模块是公用的,有区别的是硬件抽象层和操作系统抽象层,与硬件和操作系统相关的模块比如中断驱动、信号量同步处理都分别提炼出来,单独放在这些模块文件中,减少软件开发和维护的工作量。下面对图-2中的软件模块进行说明:
1. 硬件抽象层:该层主要完成对不同处理器的硬件的抽象,比如地址映射、中断处理、 PCI配置空间的访问,IO寄存器的访问等功能。将两个处理器之间的硬件差异隐藏起来,以便上一层统一管理接口。
2. 操作系统抽象层:该层主要完成对不同操作系统之间的抽象,提供vxWorks和pSos两个操作系统的统一接口,主要是同步、信号量、关键代码的互斥保护机制等功能。
3. 通道及同步事件管理层:为了建立多处理器之间的多通道通讯和同步机制,该层支持多个通道独立通讯能力,每个通道都有唯一的句柄用于访问,通道的打开、使用、关闭相互独立。该层同时也支持命名的同步事件,可用于处理器之间的同步等待功能。
4. 消息处理管理层:该层完成多通道的指定长度分组包通讯功能,支持小数据量的通讯数据,并支持同步机制,DSP的控制指令可以采用这种方式进行通讯。
5. 共享缓存:支持多通道命名共享缓存,其中的数据可以同时被两个处理器访问,配合同步事件机制,流式数据可以采用这种方式进行高速、高效通讯。
6. 同步事件:支持多通道可命名的处理器之间的同步事件功能,ARM或DSP可以让对方等待同步事件,用于精确控制同步处理共享资源。
7. RPC(远程过程调用)层:在消息处理管理层和同步事件的基础上,当DSP处理器有时需要打印调试信息,或者读取HOST的资源时,比如调用printf、fopen、fread等标准c输入输出函数,通过该层处理后,ARM会调用相关函数完成指定的任务,并将结果返回给Trimedia1300。
在这里我们还要专门的描述的是位于硬件抽象层里的共享内存,它只在HOST的一方存在,所有需要两个处理器共享的数据都存储在该区域里,包括高层的共享缓存、消息、同步事件、通道信息等数据,因此需要主机维护物理连续的、一定大小的内存,并且是处理器非cacheable的区域。
下面本文将描述典型的控制指令传输方式,具体的过程见图-3
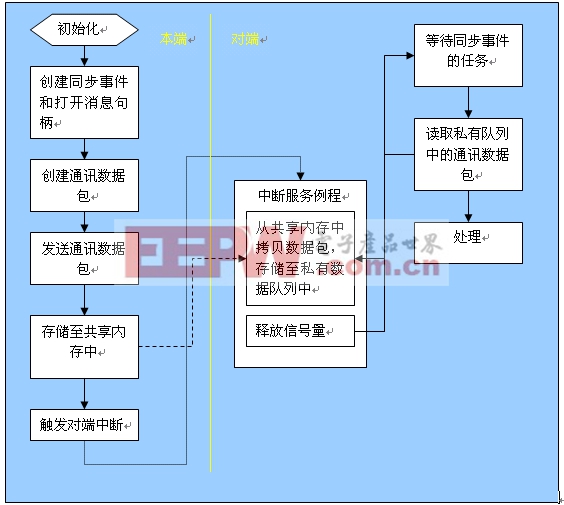
图-3
过程说明:本端处理器作初始化,创建同步事件,打开消息通讯句柄, 同步事件用于读取数据时任务阻塞,然后创建通讯数据包并且发送,发送例程将数据存储在共享缓冲区内,最后触发对方中断。对端处理器进入中断响应,首先中断例程分析共享数据区的通讯数据状态,发现某通道有新的未处理数据后,将其拷贝至自己的私有内存空间,并清理自己的共享数据区状态,然后释放在等待中的通讯任务的信号量,使读通讯数据包的任务解除阻塞状态,从私有数据区读取通讯数据包并作相应处理。
数据流通讯与数据包通讯类似,不过方法更简单,在创建共享缓存和同步事件后,一方写入数据后,出发同步事件,另一方等到同步事件解除后读取数据,效率很高而处理器开销节省至最低。
处理器之间的同步事件功能可以有效地对共享资源进行保护,防止多处理器同时对某一个共享资源访问,导致数据不完整。RPC(远程过程调用)功能能方便的用于系统调试和利用主处理器资源,能方便产品的调试和功能开发。
以上是简化的多处理器通讯模型,方法适用于大多数RISC+DSP的架构,另外为了实现该通讯机制,还必须先完成三个前提,下面将简单对此进行描述。
1. 位于HOST的共享内存必须是物理连续、非缓冲(none-cacheable)的一段内存,否则,两个处理器因为本身都带有数据高速缓存,会使数据的完整性无法保障,因此需要对两个处理器进行配置,对这段内存的访问关闭cache操作,具体操作过程不再赘述。
2. 在编译Trimedia1300程序的时候,将指向共享内存的指针设置为下载时解析,并且要将Trimedia1300的下载程序移植到vxWorks操作系统,再下载解析该指针时将其指向ARM已分配给好的物理连续内存,Trimedia1300程序开始运行后就可以立即对共享内存初始化并进行通讯。
3. 该通讯协议以vxWorks的BSP(板级支持包)的方式提供接口,并创建标准的vxWorks设备,便于安装、使用。
该通讯规范已经在实用化的商业多媒体机顶盒中运行,该产品的数据流量较大,对时延要求很高,控制命令非常密集,从总体评价来看,采用该通讯协议后,无论是其效率、延时、处理器占用时间、灵活性、稳定性、可拓展性均获得很好的表现,希望本文也能对正在开发类似产品的人员起一定的提示作用,能加快相关产品的研发。
2004-7-8
参考文献:
Tornado Online Manuals by Windriver
Trimedia SDE Documents by Philips Semiconductor
pSOS Manuals by Integrated Systems, Inc.
S3c2510A User’s manuals by Samsung Electronics
PCI Local Bus Specification by PCI Special Interest Group








评论