
基于ARM946E处理器的MP3解码优化系统设计
1 MPEG Audio Layer3的解码流程
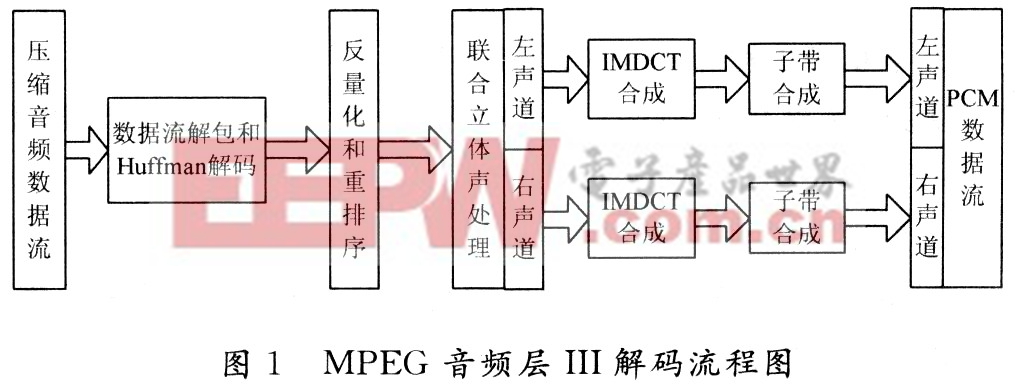
MP3解码算法流程如图1所示。
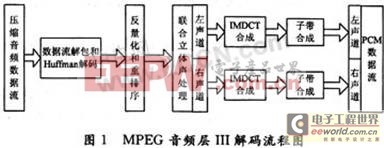
主要过程包括:数据流解码、Huffman解压缩、反量化与重排序、立体声解码、IMDCT和子带合成运算等。其中Huffman解码与反量化、IMDCT和子带合成等3个过程在MP3解码过程中占用了最多的CPU和内存资源,是嵌入式系统实现软件解码的关键。
2 ARM946E处理器
ARM946E处理器属于ARM9内核带有E扩展的一个可综合版本,执行v5TE架构指令。采用5级流水线,存储器系统根据哈佛体系结构重新设计,独立的数据和指令总线。带有一套存储器子系统,以提高系统性能和支持大型操作系统。
如图2所示,存储器子系统包含1个存储器保护单元(MPU)、高速缓存(Cache)和写缓冲(Write Buffer);CPU通过该子系统与系统存储器相连。
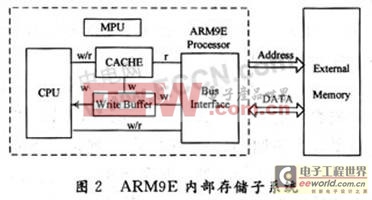
相对于ARM7,ARM9E性能上的提高主要表现在工作频率、改进的硬件特性及优化的指令执行效率。另外,ARM9E集成了轻量级的DSP处理能力,以很小的成本(CPU增加功能需要增加硬件)换来非常实用的DSP性能。充分利用好芯片资源是实现MP3解码优化的关键。
3算法优化
针对MP3中涉及较大运算的Huffman解码与反量化、IMDCT和子带合成,分别提出算法优化处理。
3.1 定长查找冗余表Huffman解码算法
Huffman解码器可以通过从头至尾逐一检测各符号,以查表比较的方式进行解码。即从一维的bit流中分辨出各个长度不同的Huffman码字,然后进行复杂的匹配。
由于LayerⅢ中的Huffman码表组长度不一,会增加码字的搜索时间。定长查找冗余表法扩充Huff—man查找表,每次选取定长N bit码流作为查找索引。查找表中包括跳转指针和编码值。
若节点索引值为跳转指针时,将通过扩充Huffman查找表得知此Huffman编码的后续bit数,并跳转到另外一个节点;然后再根据后续bit数从码流中取值;接着从上次跳转节点开始查找,如此重复直到找出对应huffman编码的内容。查找表利用Union数据结构实现,可减小Huffman表占用的空间。假设一Huffman编码长度为1,采用传统算法需要1次移位操作和1次比较,使用定长查找法只需[l/N]次查找和[l/N]次比较操作。
表1,表2是Huffman解码的举例说明:

若Huffman编码为000000001010(内容为“DAB”),定长N=3,即每次从码流中取3 b数据,解码步骤如下:
(1)取3 b数据000,从Huffman查找表检索,000对应为指针类型,指向表项号8,标志位为0,说明没有取到1个完整的Huffman编码,后续仍有3 b数据;
(2)继续取3 b数据000,从Huffman查找表的第8项开始检索,索引值为000对应的内容为“D”,此时标志位为1,即表示已完成1次Huffman解码;
(3)取3 b数据001,对应表内的第1项,标志位为1说明已取完该个Huffman编码,表项内容为“A”;
(4)取3 b数据010,对应表内的第2项,表项内容为“B”。
至此,已完整从Huffman编码“000000001010”解码出“DAB”的内容。
3.2 IMDCT与合成子带滤波的简化算法
反离散修正余弦变换(IMDCT)是在去混叠处理之后进行的,它的计算公式如式(1)所示:

子带合成滤波在解码过程中包括了32点到64点的IMDCT处理,如式(3)所示:

由于N(i)(k)具有对称特性,可以得出:

只要计算0≤in/4和n/2+1≤i3n/4范围的V(i)值即可。其减少了将近一半的计算量。
4代码优化
根据ARM946E处理器硬件特点,对实时性要求较高的关键程序进行C语言和ARM汇编级代码优化。
4.1减计数循环体
IMDCT和子带合成滤波器组2个运算量最大部分中有多个循环体运算,为了提高执行效率,推荐使用减计数循环体。
如表3所示,对于固定次数的循环,减计数循环比增计数循环速度快。这是因为每次增计数循环体外加3条指令,而减计数循环体外只有2条指令,减循环终止条件为减计数到零,而不是计数增加到某个特定的限制值。由于减计数结果已存储在指令条件标志里,省去与零比较指令。

4.2 内联函数和内嵌汇编
MP3解码算法中定点化乘法都是通过函数调用来实现,每次调用需要开销23~28个时钟周期,其中超过15个周期用于函数调用时PC指针以及寄存器压栈保护上。采用内联函数方式(使用关键字_inline声明)或宏指令,在编译阶段代码段将被直接展开。另外armcc编译器允许在C源程序中使用内嵌汇编(但代码可移植性差),使用包括汇编的内嵌函数,可以使编译器支持通常不能有效使用的ARM指令和优化方法,例如C编译器不支持的ARM v5E扩展指令。使用内联函数结合内嵌汇编实现移位乘法,可使平均时钟周期缩短为6~8个。
4.3 ARM DSP扩展指令的运用
ARM946E处理器支持ARM DSP扩展指令,主要包括3个类型:
(1)单周期的16×16和32×16 MAC操作;
(2)对原有的算术运算指令增加了饱和处理扩展;
(3)前导零(CLZ)运算指令,提高归一化、浮点运算以及除法操作的性能。
ARM处理器不支持浮点运算,经过测试及分析,定点运算中数值的截断误差选择为28 b,其可以达到较好的解码音质,不会因为爆音过多而影响播放效果。
完成类似的乘法功能,ARM的SMULL(32×32)指令需要3个周期,而ARM DSP扩展指令SMULWT(32×16)只需要1个周期。从数据的准确性上分析,由于乘数的精度为16 b,最终结果有些差异,但由于MP3解码运算都是基于28 b的定点数值的,所以通常的运算都是一个运算结果跟某一个固定定点表中的数据相乘的。若选择固定定点表中数据的高16 b数据进行运算,运算的结果误差在1 b以内。
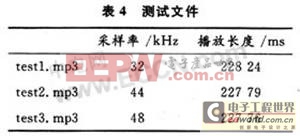
为了验证使用ARM DSP扩展指令的优化效果,在系统120 MHz主频下,以128 Kb/s的压缩速率进行编码测试,采用的测试文件如表4所示。
上述3个MP3测试文件的比特率均为128 Kb/s,使用这三首MP3歌曲进行解码分析结果如图3所示。
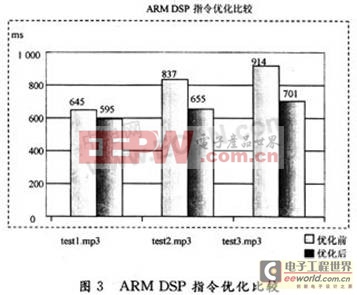
实验表明,使用ARM DSP扩展指令比使用ARM一般指令解码性能平均提高17.5%,主观听觉上音质效果无差异。
5 结 语
这里充分利用ARM946E处理器的DSP扩展指令特点提高程序代码的执行效率,对3个关键模块:Huffman解码,IMDCT运算,合成子带滤波进行算法优化及简化处理,减少了各模块的运算量,同时从C语言和ARM汇编层次来优化代码,取得了较好的实时MP3解码效果。


评论