
FPGA:PCI Express接口
随着 PCI Express 在高端 FPGA 中变得司空见惯,让我们看看 FPGA 供应商如何轻松实现该技术。特别是,我们更仔细地研究了赛灵思的 PCI Express 解决方案。
本文引用地址:http://www.amcfsurvey.com/article/202401/454643.htmPCI Express 1 - 连接器
PCI Express 通常有两种尺寸:1 通道和 16 通道,其中 1 通道用于普通主板,16 通道用于显卡。
连接器
1 通道连接器有 36 个触点,排列成两排,每排 18 个触点。
这是俯视图。

在 36 个触点中,只有 6 个对数据传输有用,其余是电源引脚和其他辅助信号。 6 个功能触点以 3 对使用:
名为 REFCLK 的时钟对。
名为 PER 的接收对。
称为 PET 的传输对。

这些信号对通常被称为“差分对”,因为来自一对的每个信号都携带相同的信号,但一个信号与另一个信号相反。 使用差分对的原因主要是传输的可靠性,稍后将更详细地讨论。
在 PCI Express 第 1 代(或简称为“Gen1”)中,PET 和 PER 对的数据传输速度为 2.5Gbps。 Gen2 将这一数字翻了一番。
查看 Dragon-E 板,我们可以识别出 FPGA 下方的 PET 对。

为了正常工作,差分对中的线路需要电耦合并且没有阻抗不连续性,这在实践中意味着“保持紧密”和“没有锐角”。 这就是 Dragon-E 的 PET 对蛇形形状的原因。 板的另一侧显示了另外两对蛇形对 REFCLK 和 PER。
PCI Express x16 插槽
为了提高速度,可以使用多条车道。 不需要复制 REFCLK 对,例如,具有 2 个通道的 PCI Express 使用 5 个对(1 个 REFCLK + 2 个 PET + 2 个 PER)。
图形板通常使用 16 通道连接器,通常称为 PCI Express x16。
PCI Express 2 - 拓扑
点对点架构
在 2.5Gsps 时,PCI Express Gen1 线路速度比 75MHz 传统 PCI 速度快 33 倍。
这怎么可能?只是因为 PCI express 是点对点总线。
还记得PCI是共享总线吗?
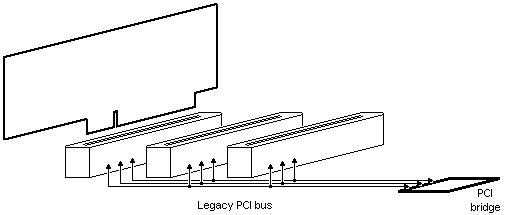
使用PCI时,必须指定足够的时间,让信号在每个时钟周期内稳定下来。 这是因为PCI总线的每条线路都在同一总线上的PCI连接器和板上共享。 使用PCI Express,每个信号都是点对点的,这意味着不再有建立时间,线路速度可以更高。
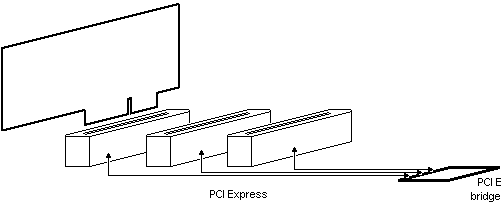
例如,如果主板有两个 1 通道连接器和一个 16 通道连接器,则需要桥接器上有 6+6+34=46 个引脚,仅用于 REFCLK、PER 和 PET(因为不允许共享)。
时钟恢复
在2.5GHz开始的速度下,点对点架构仍然是一个挑战,因为每个位的持续时间非常短,以至于时序抖动(围绕每个位到达的时间不确定性)成为一个问题。 即使每个信号对都有相关的时钟对同时传输,时钟对也会受到定时抖动的影响。 因此,使用了一种称为“时钟恢复”的新技术。
时钟恢复很简单。 基本上,对于每个信号对,接收器对都会查看信号转换(位 0 后跟位 1,反之亦然),从中可以推断出周围位的位置。 一个问题是,如果许多连续的位以相同的值传输(如许多0),则看不到信号转换。 因此,传输额外的位以确保信号转换不会相距太远(这会“重新同步”时钟恢复机制)。
额外的比特使用一种称为 8b/10b 编码的方案发送,因此对于每 8 位有用数据,实际上有 10 位以特定方式传输(开销为 20%),以保证足够的信号转换。 但这也意味着,在2.5GHz时,我们每对只能获得250MBps的有用带宽(而不是没有编码开销的312MBps)。
差分对
现在还记得信号是在差分对上发送的事实吗? 这有很多优点:
它更不受外部干扰。
它能够在低电压下工作(=更低的功耗)。
...最后但并非最不重要的一点是:这有助于时钟恢复获得精确的信号转换。
差分对有一个明显的缺点:传输信号需要两倍的导线。
PCI Express 3 - 数据包、堆栈和网络的故事
分组事务
PCI express 是串行总线。 或者是吗? 从计算机的角度来看,它是一种可以实现读写事务的传统总线。
诀窍是所有操作都已打包。 假设 CPU 想要将一些数据写入设备。 它将订单转发到 PCI Express 网桥,然后 PCI Express 网桥创建一个数据包。 数据包包含要写入的地址和数据,并串行转发到目标设备,目标设备将写入顺序解包并执行。
如果 CPU 想要读取怎么办? 同样,网桥将数据包转发到目标设备,目标设备现在必须执行读取,创建返回数据包并将其发送到网桥。
所有这一切都在实践中非常容易做到,感谢来自...
PCI Express 协议栈
让数据包沿着线路可靠地流动需要一些魔力。 由于数据包以非常高的速度串行传输,因此必须对它们进行反序列化/汇编、在目的地解码(删除 8b/10b 编码)、去交错(如果使用多个通道)并检查线路损坏(CRC 检查)。
听起来很复杂? 大概是这样。 问题是,我们并不真正关心,因为大部分复杂性都是在由三层组成的“PCI Express堆栈”中处理的。
物理层。
数据链路层。
事务层。
前两层是在PCI Express FPGA内核(通常是硬核和软核的组合)中为我们实现的,用于处理所有复杂性。 作为用户,我们只在交易层工作,那里的生活很轻松,天空很蓝,女孩很漂亮。
更多细节:
物理层:这是引脚切换的地方。8b/10b 编码/解码和通道拆卸/重组都在那里完成。
数据链路层:检查数据完整性 (CRC) 并在需要时重新传输数据包(希望这种情况很少发生)。
交易层:即用户级别。一旦数据包到达这里,它就可以保证是好数据。
好数据?太好了,这就是我们想要的!
让我们看看在事务层中工作是什么样的。
PCI Express 4 - 事务层
在交易层,我们接收“数据包”。 有一个 32 位总线,数据包到达总线(数据包长度始终是 32 位的倍数)。 也许一个数据包会说“在地址0xABCD写入数据1234x0”,另一个数据包会说“从地址0xDCBA读取(并返回响应数据包)”。
数据包有很多种类型:内存读取、内存写入、I/O 读取、I/O 写入、消息、完成等...... 我们在事务层的工作是接受数据包和发出数据包。 数据包以称为“事务层数据包”(TLP)的特定格式呈现给我们,到达总线的每个 32 位数据称为“双字”(或简称 DW)。
所以一个数据包(哎呀,对不起,一个 TLP)是一堆 DW。
TLP 的外观
TLP 的解释非常简单。 以下是其结构的一般视图。
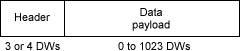
标头包含 3 或 4 个 DW,但最重要的字段是第一个 DW 的一部分。

“Fmt”字段表示标头的长度,以及是否存在数据有效负载。
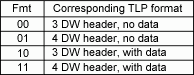
然后与“类型”一起描述TLP操作。 TLP 标头内容的其余部分取决于 TLP 操作。
例如,下面是一个 32 位内存写入 TLP 标头,您可以在其中看到写入地址位于标头的末尾(并且要写入的数据位于标头之后的有效负载中)。
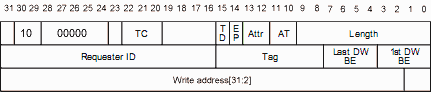
“Fmt”字段为“10”,表示“3 DW,有数据”。 这是有道理的,内存写入需要写入数据,因此在标头之后获得数据有效负载后,我们将该数据写入某个内存(或以某种方式使用它),然后我们就完成了它。 字段“长度”表示有效负载中有多少 DW(从 0 到 1023)。 通常,要写入的是单个 DW,在这种情况下,长度等于 1,总 TLP 长度为 4 DW(标头为 3,有效负载为 1)。
现在内存读取呢?不知何故,我们必须返回数据。
用数据完成
如果 TLP 是内存读取而不是写入,我们必须执行读取,然后做出响应。 该响应有一个特殊的 TLP,它称为 CplD(数据完成),其有效负载包含我们要返回的数据。
让我们仔细看看 32 位内存读取 TLP 标头 - 它与我们之前的 32 位内存写入非常相似。
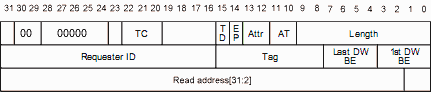
一个区别是 Fmt=00,这意味着“没有数据”。 有道理,我们不需要数据来读取,只需要一个地址。 但我们现在必须用数据来回应。 同样重要的是,响应需要路由回请求读取的人...... 你看到问题了吗?
好的,我们收到了一个读取请求。 它来自CPU吗? 还是来自中断控制器? 还是从显卡? 毕竟,许多设备都能够发出这样的请求。 答案在“请求者 ID”中给出 - 它显示谁请求读取。 因此,当我们创建 CplD TLP 时,我们必须重新复制其中的“请求者 ID”。 这样,它将通过PCI Express网桥路由到它所属的位置。 顺便说一句,我们还必须重新复制“标签”(这在多次读取待处理的情况下很有用)。
TLP 大小
典型的 32 位地址/数据存储器读取 TLP 由报头中的 3 个 DW 组成,没有有效载荷(因此总共 96 位),而类似的内存写入由 4 个 DW(3 个用于报头,1 个用于有效负载)组成。 由于 TLP 标头开销,这在带宽方面效率不高,因此最好尽可能使用更大的 TLP 有效负载。 TLP 有效负载理论上可以达到 1023 DW,这对于突发读取和写入非常方便,尽管 PC 可以将最大大小限制为较低的值(通常为 32 DW)。
有关更多信息,请通过谷歌搜索 PCI Express 规范来查看官方 PCI Express 规范,例如PCI_Express_Base_11.pdf
理论已经够多了,让我们玩得开心,玩玩 Xilinx PCI Express 向导。
PCI Express 5 - Xilinx 向导
Xilinx 使 PCI express 的使用变得简单 - 它们提供了一个免费的 PCI Express 内核(称为“Endpoint Block Plus”)和一个用于配置它的向导。 所有这些都在他们的免费版 ISE - ISE WebPack 中。
因此,让我们启动Xilinx CORE生成器,选择Endpoint Block Plus。
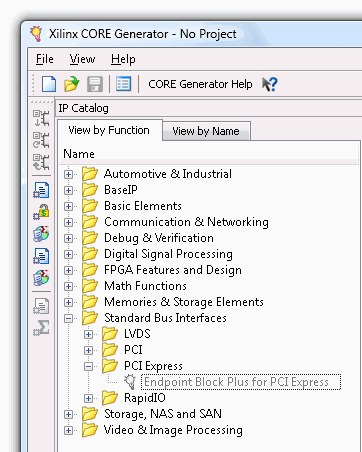
内核处于非活动状态,我们需要使用 File --> New Project 创建一个项目并选择一个 FPGA(这里我们使用的是 Dragon-E,所以我们选择 Virtex-5)...
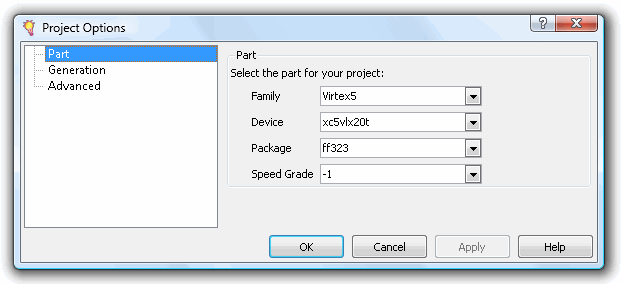
...,然后选择您喜欢的语言(在“生成”选项卡中)。
现在,Endpoint Block Plus内核变为活动状态,您可以双击它以启动向导。
在第一页上,为组件命名。在这里,我们选择了“my_endpoint_blk_plus”。 剩下的对 Dragon-E 来说没问题,所以点击“下一步>”。
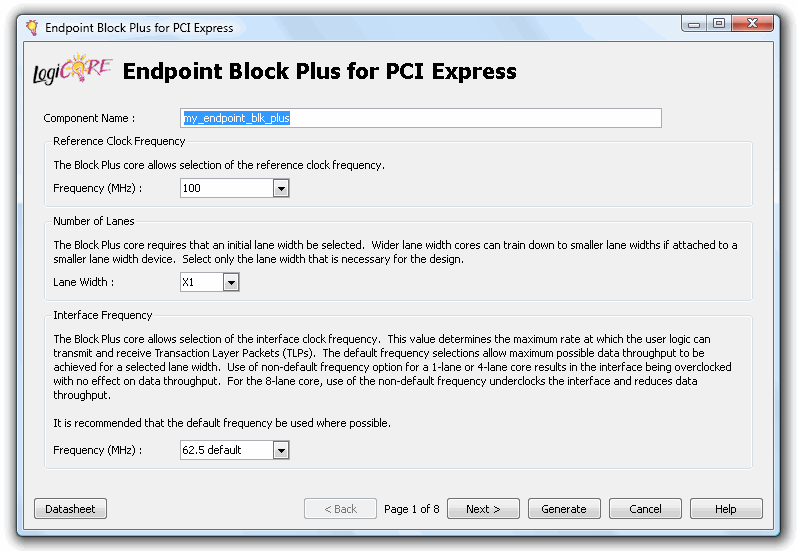
现在,您可以更改供应商/设备 ID...

...和地址空间。
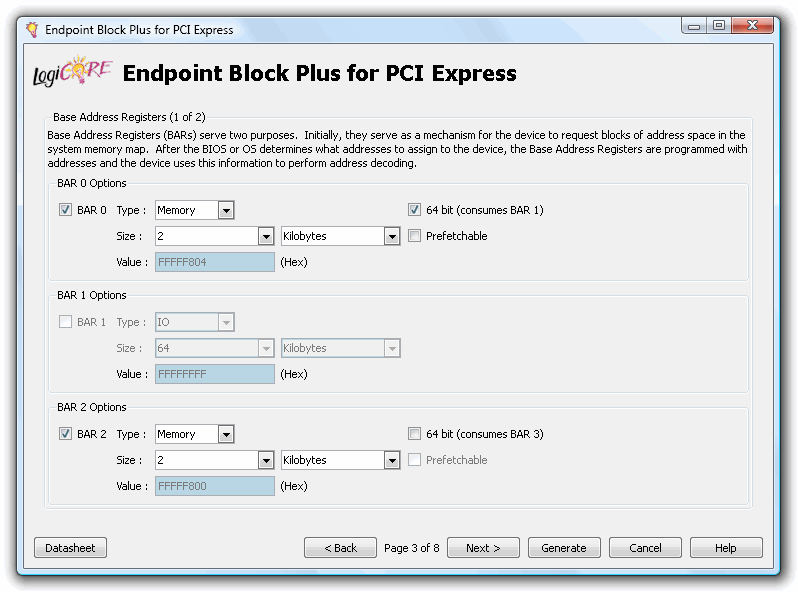
接下来的页面没有太多兴趣,所以点击“生成”来生成核心及其文档。
现在,我们已准备好创建第一个PCI Express FPGA位文件,在FPGA中对其进行编程,并生成真正的PCI Express流量。
PCI Express 6 - 简单事务
让我们尝试从 PCI Express 总线控制 LED。
Xilinx 的“Endpoint Block Plus”内核允许我们在事务层级别工作,因此只需几行代码即可。
“Endpoint Block Plus”不是在32位总线上提供数据,而是使用64位总线(因此我们在每个时钟周期获得的数据量是原来的两倍)。 这不是问题,一个简单的状态机将处理简单的内存读取和写入。
// we use signals from Xilinx's "Endpoint Block Plus"
// first we declare that we are always ready to get data
assign trn_rdst_rdy_n = 1'b0;
// then we create a state machine that triggers when we get a PCI Express memory read or write
reg RXstate;
reg [63:0] RXrd;always @(posedge clk)case(RXstate)
// we are going to handle simple memory reads & writes
// we know that with the "Endpoint Block Plus" core, such simple transactions always happens
// using two cycles so we just need a two-states state machine
// first, we wait for the beginning of a memory transaction with up to 32-bit data (i.e. with length=1)
1'b0: if(~trn_rsrc_rdy_n && ~trn_rsof_n && trn_rd[61:56]==6'b0_00000 && trn_rd[41:32]==10'h001) begin
RXstate <= 1'b1;
RXrd <= trn_rd;
end
// then the second state waits for the end of the transaction
1'b1: if(~trn_rsrc_rdy_n) RXstate <= 1'b0;
endcase
现在我们准备更新 LED。
wire [31:0] RXaddr = trn_rd[63:32];
// memory address (read or write) (valid during the second state of the state machine)
wire [31:0] RXdata = trn_rd[31:0];
// memory data (for a write) (valid during the second state of the state machine)
wire RXrdwr = RXrd[62];
// 0 for a read, 1 for a write
wire RXRead = ~trn_rsrc_rdy_n & RXstate & ~RXrdwr;
// true when a read is happeningwire RX
write = ~trn_rsrc_rdy_n & RXstate & RXrdwr;
// true when a write is happening
// update two LEDs using the two LSBs from the data written
reg [1:0] LEDs;
always @(posedge clk) if(RXwrite) LEDs <= RXdata[1:0];
对于内存写入,仅此而已。 对于内存读取,您需要使用要返回的数据创建响应数据包。 生成中断也非常容易 - 只需断言一个名为“cfg_interrupt_n”的信号即可。
想要更多?请查看 Dragon-E 的启动套件以获取更完整的示例,并查看 Xilinx 的 UG341 Endpoint Block Plus 规范文档,了解所有信号的描述。










评论