
用VPU带来全民AI能力|英特尔AI on PC技术解读
如今的AI技术的进步可以说是一日千里,也从前几年我们经常提到的判定式AI的基础上,产生了大量的生成式AI的应用,这些基于AI大模型的新应用,其实也给产业链上游的硬件厂商提出了新的要求。
本文引用地址:http://www.amcfsurvey.com/article/202306/447448.htm通过布局异构计算,蓝色巨人如何涉入AI这条河流
对于蓝色芯片巨头英特尔来说,目前已经通过OneAPI和OPENVINO为基础,形成了CPU、GPU、FPGA/ASIC 、神经网络计划、RISC-V一系列的异构计算的产品线,前两年,英特尔提出了XPU——超异构计算的概念,其实就是将不同计算构架下的计算能力统在一个通用计算的平台下生成,而且据说英特尔的RISC-V处理器也处理于即将推出的状态。

今天给大家聊的自然不是RISC-V,而是大家耳熟能悉的通用计算CPU平台的AI应用,是的,你没听错,在英特尔最新的CPU MapRoad(产品图线图)上,将整合进新的AI运算模块,让每一台PC都具备一定的AI能力。而实现这一能力的正是下半年即将面市的Meteor Lake,如果放在个人PC上,也就是大家所关注的Meteor Lake。
你如果仔细关注过英特尔酷睿处理器,就知道英特尔其实早在Alder Lake到Raptor Lake,也就是之前混合架构的12代和13代酷睿就集成了AI深度学习的能力,它是通过一块嵌入式芯片专门处理向量神经网络指今集(VNNI),其实也就向AVX-512中增加了新的深度学习的功能,诸如英特尔智音技术、语音唤醒、高质音频等以判定式AI为底层的技术都是通过它来实现的。而且英特尔通过向13代酷睿上加载Movidius Myriad X视觉处理单元,通过计算机视觉和深度神经网络推理让PC具备了生成式AI的能力。
对英特尔极为关键的Meteor Lake,会有哪些技术亮点
在日前英特尔的一场名为“AI on PC”技术交流会上,英特尔明确了Meteor Lake将在硬件能力上对AI的主要应用场景进行支持,而且细聊到了支持AI功能的具体构架,甚至还进一步聊到英特尔接下来IDM 2.0对芯片构架的影响。我们一步一步来给大家展开来聊。
从帕特·基辛格主导的产品路线图来看,英特尔会在四年时间里跨越5个制程工艺的节点,其中会有三个非常重要的飞跃,第一是intel 7的Alder Lake到Raptor Lake,通过混合构架,英特尔重塑了CPU的异构计算能力;第二便是今年下半年发布的intel 4工艺制程,它采用Foveros 3D封装技术,包含即将发布的到Meteor Lake和Arrow Lake,从英特尔代工步伐和面临的竞争环境来看,它甚至比下一步的Intel 20A更加重要;第三就是Intel 20A和18A的2nm和1.8nm工艺。就这样的节奏来看,英特尔必须在Meteor Lake上为新的工艺制程开一个好头,将AI能力集成在PC中自然就是一个非常有看点的技术路线。
我们都知道,目前用于AI计算的主要是GPU,英特尔的技术人员已经明确谈到,得益于前两年在锐炫(Arc)独立显卡上的布局,Meteor Lake的GPU能力将会更加强大,这一代的酷睿平台中集成的显卡将集成锐炫显卡技术同样的图形引擎——的确,英特尔过去两代沿用相同的集成显卡,让竞争对手在轻薄笔记本领域,甚至在英特尔过去一直很强势的商用笔记本领域中尝尽了甜头。Meteor Lake英特尔一定会利用强大的集显能力扳回一程,甚至会让集成显卡具备光线追踪、XeSS超级分辨率这样的独显才会拥有的技术。要知道,光追对硬件能力的要求其实是很高的,这也让我们对Meteor Lake即将展示的集显性能非常期待。
VPU,英特尔首次在CPU上放入独立的AI硬件单元
但是,但是,但是(重要的事说三遍),集成显卡并不是英特尔用来实现AI的关键硬件,我在文章开始时一再强调英特尔在异构计算上的整合能力,是因为英特尔用来实现AI能力的是一个CPU上首次出现的全新计算模式——VPU,而在完全掌控异构计算的底层技术之后,英特尔是随时有为新一波的科技浪潮添加相对应的硬件能力的。
之前,Movidius视觉处理器就被命名为VPU,不必意外,集成入Meteor Lake的就是这样一个基于神经网络计算的独立运算模块,与以往的通过CPU和GPU的人工智能加速指令集去实现人工智能服务不同,这是一个独立的处理单元,在针对人工智能进行加速处理模式中,采用的也是“CPU+GPU+VPU“的混合处理方式,通过各个计算单元的特点,将AI处理效率最大化。这件事之所以是英特尔率先落地,是因为英特尔通过OneAPI和OPENVINO对不同构架的算力已经形成了”归一化“的统筹,换其他人,还真不一定干得这么利索。
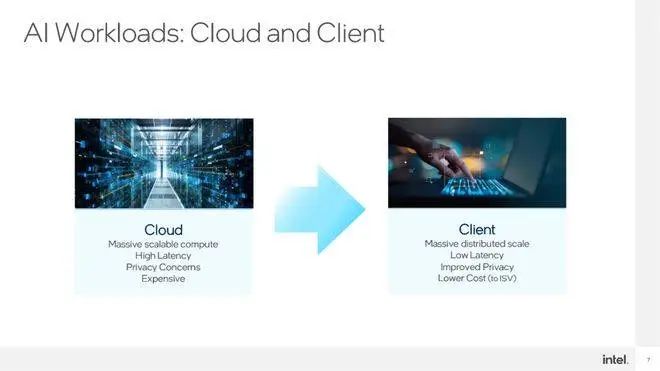
我们再来看看这块VPU究竟有何优势?按英特尔技术人员的介绍,它最大的优势就是在消费端PC上用最快速、最便宜、最低成本的方式实现AI功能。其实,英特尔的Movidius视觉处理器已经在非常宽泛的领域得到应用,它以非常优秀的每瓦性能比实现了高性能的深度学习功能,特别在视觉判别上拥有支持ISP、高兼容性,以及边缘端易于布署等优势,适于在边缘端部署,从某种意义上来说它很容易移植在“端”上,事实上,过去Movidius也有很多“端”上部署的案例。
放在一台酷睿PC上行不行?答案自然是肯定的。Meteor Lake上的这个VPU计算单元便拥有端侧上非常优秀的延时表现、数据安全性和较低的运营成本。目前,大规模的AI运算都是通过云端来提供支持的,自然就有延时和数据安全等问题,而且云端需要有大量的服务器设备来支持,从目前的用于AI运算的超算设备来看(比如英伟达才发布的DGX GH200),AI运营方需要支付非常巨大的成本,相应,消费者也需要为AI成果支付巨额的费用,之所以止前GPT和各个运营方都没有收费,只是大模型还在发展阶段,能够开源免费使用的也是大语言模型等一些基础服务,那些没开源的项目未来都是非常昂贵的,不是每个项目都能玩得起的。

英特尔在酷睿平台上集成AI能力,这无疑为AI应用打开了一个新的天窗。如果每一台消费级PC都具有本地化的AI能力,那么未来很可能会诞生无数多的新商业模式,所以如今图片生成式AI除了云端支持的Midjourney之外,还有端侧支持的Stable Diffusion,我相信未来更多富有想象力的AI画作将出自Stable Diffusion,而不是Midjourney。未来,还有可能会有统筹每台电脑AI算力的网络平台或拓扑构架出现,用于支撑大型的AI应用,当然,这种商业模式就不是本文的探讨范围之内了。
英特尔如何推进AI技术,VPN在未来PC构架上承担怎样的角色
再回到英特尔VPU的讨论之上。英特尔一直在推进AI方面的应用,过去我们看到的大多是判定式AI,比如像噪音抑制、图像分割等,比如英特尔今年在网络会议的背景处理上就采用非常完善的分割模型,能够将头部和背景非常细致地区分,相比两年前模型有了10倍复杂度的提升;另外,噪音抑制的复杂度也有50倍的提升。而在生成式AI上,大语言模型、Stable Diffusion同样也对硬件提出了较高的要求。

所以英特尔在Meteor Lake和接下来的产品路线上明确加入了VPU这样的独立IP,并且也在和众多ISV合作,目前已经与超过100家的ISV开展AI方面的合作。与其他厂商不同,英特尔提供的AI服务基于整个处理器算力,也就是CPU+GPU+VPU,他们可以处理不同使用场景、不同负载、不同延时下的AI需求。比如CPU处理AI 的延时很低,不需要长时间装载,适合敏感的AI负载;GPU延时高,但算力强,适于AI大模型;而VPU则是专门为AI设计的一套架构,能够非常高效地完成一些矩阵运算,而且对稀疏化的处理非常擅长。之前英特尔在无人机避障上便强入了这个嵌入式IP,它的功耗非常低,对流媒体的AI处理,比如手势控制 、背景虚化等需要长时间运行的AI负载,是非常高耗且省电的。
之所以要将VPU引入到PC之上,是因为作为通用计算平台,如今PC上会并行很多运算任务,如果将AI负载过多加载在CPU和GPU之上,那么在占用率高的情况下就会挤占渲染等实时任务,造成游戏等应用场景的卡顿,而交给能耗较低的VPU,那么就会让CPU和GPU随时保持较为空载的状态,留给其他通用计算的任务。
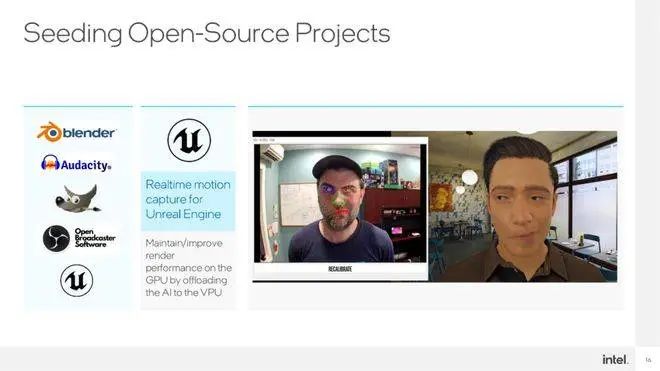
在Meteor Lake发布之后,哪些任务可以交给VPU来做呢?以Adobe的一些软件为例 ,自动化的处理、智能化抠图都可以交由VPU执行,另外,Blender(3D创作)、Audacity(音频剪辑)、OBS(直播推流)、GIMP(对标 Photoshop的一个开源软件)等软件会做VPU的资源调用。另外,英特尔与跟Unreal Engine做的数字人,以及其他引擎级别的插件,也会由VPU来支撑AI方面的负载。另外,基于Stable Diffusion做的生成式AI,同样可以交由英特尔的这套CPU+GPU+VPU的执行逻辑高效的完成。

现场,英特尔为我们展示了一个在Stable Diffusion完成的Diffusion的模型生成,就是跑在了Meteor Lake的开发机之上,上边没有独立GPU,是通过不同的IP协作完成的。比如VPU上承载了VNET模块运行,GPU上承载了encoder模块的运行。就VPU的具体AI性能,英特尔技术人员并没有直接回答,最终指标会留在Meteor Lake正式发布时才会公布。不过经过我再三向英特尔技术人员确认,Meteor Lake中的这块VPU性能,将比在13代酷睿上加载的那块Movidius Myriad X视觉处理单元在性能和功耗上均更为强大!
可以明确的是,在上述演示的仅需20秒完成的DEMO中,明确基于VPU的方案是INT8精度,与GPU上常用的FP32或BF16相比,的确在精度上有一定差别,但大部分消费类场景上,用户的感知差别都不会太明显。
英特尔硬件布局上更多的话题,非常重要!
对于VPU的前生过往,今天都给大家谈到了,最终只剩下一个问题,英特尔为什么要推VPU?其实我在上谈解读中已经解构得非常清晰——之所以要推VPU这个新IP,还是基于解决AI门槛的出发点,英特尔希望未来每一台笔记本上都能运行Stable Diffusion这样的生成式AI大模型。更何况,VPU本身是一个低功耗的IP,在实现AI能力同时,不会给整块芯片带来更大负载压力,也符合行业越来越看重“每瓦性能比”的趋势。

VPU本身并不是一个解决所有AI应用场景的硬件,但英特尔,却是一个拥有解决AI所有场景、负载的芯片厂商。而且,英特尔在整合能力上,拥有比NVIDIA更强的能力,比如英伟达最近推出的DGX GH200上首次采用了拓扑结构,而英特尔去年构架日推出Xe HPC的GPU——Ponte Vecchio,就已经在SoC里将这个结构玩得非常溜了。
在这个技术沟通会上,我和英特尔技术人员还聊到一个关于Meteor Lake的重要的话题。这个全新处理器将采用Foveros 3D封装技术,也就意味着英特尔在整合整个SoC的连接能力上将更强。更为重要的是,在这个封装中,英特尔的芯片将全面启用分离式的模块构架,这意味着芯片中的每一个IP都可以作为独立模块设计,根据计算和功用,甚至会采用不同的制程工艺。大家可以留意到,AMD早就采用了Chiplet技术对SoC内不同IP采用不同制程工艺节点来降低成本,从ZEN 2开始就把逻辑运算模块和I/O模块分用不同制程工艺,这样的需求远不止AMD一家,而英特尔这样做的目的更多是为了服务其代工业务(IDM2.0),满足的客户按需采购要求。
VPU在DIE上的面积不大,功耗也低,但却从硬件端解决了AI功能的入门问题,让未来所有的PC用户都能够使用本地端的AI功能。在芯片行业,制程工艺的进步是芯片厂商能力的重要标志,异构计算的整合能力则是另一方面的能力体现,所以未来英特尔在AI方面的布局会持续加强,从VPU到独立GPU,再到Xe HPC GPU产品上都会看到具体AI能力的落地。









评论