
为什么GPT-4不开源?OpenAI联合创始人:过去的做法是“错误的”
OpenAI 发布了其自称为“迄今为止最强大、对齐最好的模型”GPT-4,但人工智能社区的一部分人对‘缺乏公共信息’感到失望。他们的抱怨,凸显了人工智能世界中关于安全问题的日益紧张的形势。
昨天,OpenAI 发布了强大的 GPT-4,它是人们期待已久的下一代人工智能语言模型。该模型的强大能力仍在评估中,但随着研究人员和专家对其相关材料的仔细研究,一部分人对一个明显的事实表示失望:OpenAI 发布的 GPT-4,不是一个开放的人工智能模型(not an open AI model)。
本文引用地址:http://www.amcfsurvey.com/article/202303/444569.htm尽管 OpenAI 已经分享了大量 GPT-4 的基准和测试结果,以及一些有趣的演示,但基本上没有提供用于训练该模型的数据、能源成本,或用于创建该模型的具体硬件或方法的信息。
人工智能社区的一部分人批评了这一决定,认为它破坏了该公司作为一个研究机构的创始精神,并使其他人更难以复制其工作。也许更重要的是,一些人说,这也使人们难以制定保障措施来应对像 GPT-4 这样的人工智能系统所带来的威胁,而这些抱怨是在人工智能世界日益紧张和快速发展时显现的。
“我认为这一做法关闭了 'Open' AI 的大门:他们在介绍 GPT-4 的 98 页论文中自豪地宣称,没有透露任何有关训练集的内容,” Nomic AI 信息设计副总裁 Ben Schmidt 在推特上表示。
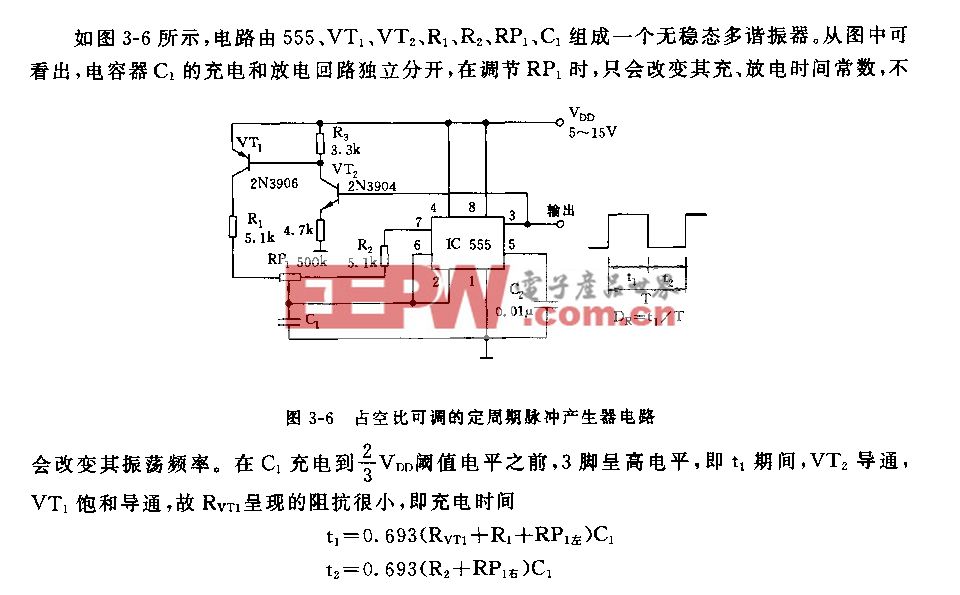
关于这一说法,Schmidt 指的是 GPT-4 技术报告中的一段内容,如下:
鉴于像 GPT-4 这样的大型模型的竞争状况和安全影响,本报告没有包含关于架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等方面的进一步细节。

在接受采访时,OpenAI 首席科学家、联合创始人 Ilya Sutskever 对这一做法进行了说明。他表示,OpenAI 不分享关于 GPT-4 的更多信息的原因是“不言而喻的”——害怕竞争和对安全的担忧。
“在竞争格局方面--外面的竞争很激烈,” Sutskever 说,“GPT-4 的开发并不容易。几乎 OpenAI 的所有人在一起花了很长时间才做出了这个东西,而且(目前)有很多很多公司都想做同样的事情。”
“安全方面,我想说,还没有竞争方面那么突出。但它将会改变,基本上是这样的。这些模型非常强大,而且会变得越来越强大。在某种程度上,如果有人想的话,很容易用这些模型造成很大的伤害。随着(模型)能力的增强,你不想透露它们是有道理的。”
OpenAI 于 2015 年成立,创始人包括 Sutskever、现任首席执行官 Sam Altman、现已离开 OpenAI 的马斯克。在一篇介绍性博客文章中,Sutskever 等人表示,该组织的目标是 “为每个人而不是股东创造价值”,并将与该领域的其他人 “自由合作”。OpenAI 成立之初是一个非营利组织,但后来为了获得数十亿美元的投资(主要来自微软)而变成了“利润上限”。
当被问及为什么 OpenAI 改变了分享其研究的方法时,Sutskever 简单地回答:“我们错了。坦率地说,我们错了。如果你像我们一样相信,在某个时候,人工智能/通用人工智能将变得极其强大,令人难以置信,那么,开源就是没有意义的。这是一个坏主意...... 可以预料的是,在几年内,每个人都会完全明白,开源人工智能是不明智的。”
然而,人工智能社区对此事的看法各不相同。值得注意的是,在 GPT-4 发布的几周前,Meta 开发的另一个名为 LLaMA 的人工智能语言模型在网上遭泄露,引发了关于开源研究的威胁和好处的类似讨论。不过,大多数人对 GPT-4 的“封闭”模型的最初反应是负面的。
对此,Schmidt 表示,由于无法看到 GPT-4 是在什么数据上训练的,人们很难知道该系统在什么地方可以安全使用并提出修正。
“对于人们来说,要想对这个模型在什么地方不起作用做出明智的决定,他们需要对它的作用以及其中的假设有一个更好的认识,” Schmidt 说,“我不会相信在没有雪天气候经验的情况下训练出来的自动驾驶汽车;一些漏洞或其他问题,很可能会在真实情况下使用时浮现出来。”
Lightning AI 首席执行官、开源工具 PyTorch Lightning 创建者 William Falcon 表示,人们可以从商业角度上理解这一决定。“作为一家公司,它完全有权利这样做。” 但 Falcon 也认为,这一做法为更广泛的社区树立了一个 “坏先例”,并可能产生有害影响。
“如果这个模型出错了,而且会出错的,你已经看到它出现了幻觉,给你提供了错误的信息,那么社会应该如何反应?” Falcon 说,“伦理研究人员应该如何应对并提出解决方案,并说‘这种方式不起作用,也许可以调整它来做这个其他事情?’”
一些人建议 OpenAI 隐藏 GPT-4 的构建细节的另一个原因是法律责任。人工智能语言模型是在巨大的文本数据集上进行训练的,其中很多数据是从网络上直接获取的,可能包括受版权保护的材料。同样以互联网内容为基础训练数据的人工智能 “文生图”模型,正是因为这个原因而面临法律挑战,目前有几家公司正被人类艺术家和图片库网站 Getty Images 起诉。
当被问及这是否是 OpenAI 没有分享其训练数据的一个原因时,Sutskever 表示:“我对此的看法是,训练数据就是技术(training data is technology)。它可能看起来不是这样的,但它是。我们不披露训练数据的原因与我们不披露参数数量的原因基本相同。” 当被问及 OpenAI 是否可以明确表示其训练数据不包括盗版材料时,Sutskever 没有回答。
Sutskever 确实同意批评者们的观点,即开源模型有助于开发安全措施的想法是有 “价值” 的。他说:“如果有更多人研究这些模型,我们就能了解更多,那就太好了。” 出于这些原因,OpenAI 向某些学术和研究机构提供了访问其系统的权限。
关于共享研究的讨论是在人工智能世界发生狂热变化的时候进行的,压力在多个方面都在增加。在企业方面,像谷歌和微软这样的科技巨头正急于将人工智能功能添加到他们的产品中,往往将以前的道德问题搁置一边。(微软最近解雇了一个专门负责确保其人工智能产品遵循道德准则的团队)。在研究方面,技术本身似乎正在迅速改善,引发了人们对人工智能正在成为一个严重和迫在眉睫的威胁的担忧。
The Centre for Long-Term Resilience 人工智能政策负责人 Jess Whittlestone 说,平衡这些不同的压力带来了严重的治理挑战——可能需要第三方监管机构参与。
“我们看到这些人工智能能力发展得非常快,我总体上担心这些能力的发展速度超过了我们的适应能力。” 她表示,OpenAI 不分享关于 GPT-4 的更多细节的理由是好的,但也可能导致人工智能世界的权力集中化。
“不应该由个别公司来做这些决定,” Whittlestone 说,“理想的情况是,我们需要把这里的做法编纂成册,然后让独立的第三方在审查与某些模型相关的风险以及向世界发布它们是否有意义方面发挥更大的作用。”
one more thing
在不满 OpenAI 越来越“封闭”的人群中,自然少不了因“利益冲突”而离开 OpenAI 的马斯克。这一次,他表达了自己的困惑:
“我仍然困惑的是,我捐献了 1 亿美元的非营利组织是如何成为市值 300 亿美元的营利组织的。如果这是合法的,为什么不是每个人都这样做?”

原文链接:
https://www.theverge.com/2023/3/15/23640180/openai-gpt-4-launch-closed-research-ilya-sutskever-interview














评论