
AI计算时代,25年工龄的RRAM渐入佳境

RRAM,一个非易失性新型存储器,突然火了。
该新型存储器是以非导性材料的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换为原理制造而成的存储器。由于结构简单、集成度高、低功耗等优点,一直被认为是最有可能突破传统器件限制的新型器件。
而RRAM一路走来,却万分坎坷。从开始“上班”到不被看好,再到小有名气,RRAM花了25年:
2008年,惠普公司提出一种被称为忆阻器(memristor)的 RRAM,将其用在面向未来的系统“The Machine”上。但惠普在这项技术上努力多年之后却转向了一种更加传统的内存方案,退出了忆阻器的道路。
对于一项新型技术来说,大厂长时间坚持后未果并抛弃,最为致命,更何况是两个:
2014年前后,自2011年开始与索尼一同开发RRAM的美光退出项目,转而开始与英特尔合作重点开发另一种存储技术 3D XPoint。
从1990s到2010s,RRAM走过了功能机时代,跨过了智能终端时代,一直被研究,从未被大规模应用,几乎被时代遗忘。
而现如今,RRAM又被大厂“相中”,同时多了一大批坚定的拥护者:
2022年11月,英飞凌和台积电宣布,两家公司正准备将台积电的电阻式RAM(RRAM)非易失性存储器(NVM)技术引入英飞凌的下一代AURIX™微控制器(MCU)。
国内外多个半导体初创公司一心扑在RRAM上:
● 成立于2015年的Weebit Nano,试图利用RRAM,满足物联网(IoT)设备、机器人、5G通信和人工智能等一系列新电子产品中对更高性能和更低功耗内存解决方案日益增长的需求。
● 成立于2019年的昕原半导体,打造基于RRAM技术的新型存储产品及相关衍生品,服务于AIoT、人工智能、数据中心、智能汽车等新兴应用。
● 成立于2020年的亿铸科技,研发基于RRAM的全数字存算一体大算力AI芯片,服务于云端数据中心、智能驾驶等对算力密度、能效比需求很高的应用场景。
······
本文想要探讨的是:RRAM为何在现在让大厂回心转意?RRAM要如何完成自己的逆袭之路?
“团宠”RRAM
逆袭始于2021年。
过去业内对于RRAM最大的质疑,无外乎“工艺不成熟、商业化迟迟不能落地”。
而在2021年,晶圆代工厂台积电现身,为RRAM站台:宣布40nmRRAM进入量产,28nm和22nmRRAM准备量产。
随后,国内同样传来利好消息:2022年2月,昕原半导体主导建设的RRAM 12寸中试生产线顺利完成了自主研发装备的装机验收工作,实现中试线工艺流程的通线,并成功流片(试生产)。
质疑被一步步打破,RRAM正式迎来自己的逆袭之路。
首先是在学界,RRAM存在感直线上升,从探讨其潜力、可行性转变到证明其可靠性。
在2008-2016年前后,学界的文章关于RRAM的描述大多是“有潜能”,团队大多是提出解决方案:
● 2009年,惠普实验室论证了利用 Crosslatch 系统可以较为简单的实现堆栈,形成立体的内存结构,RRAM在速度、密度等方面均具有极大的潜能,能有效替代目前的存储单元。
● 2016年,在VLSI(超大规模集成电路)国际研讨会上,中国科学院微电子研究所刘明院士的团队提出了自对准高性能自选通RRAM结构,为高密度、低成本三维垂直交叉阵列的制备提供解决方案。
······
而在2022年,大多文章是在推动RRAM的快速落地,通过设计、实验证明其有着足够的优势:
● 在2022年度ISSCC会议上,台积电发表六篇关于存内计算存储器IP的论文,大力推进基于RRAM的存内计算方案。
● 在中国半导体十大研究进展候选推荐(2022-025)中,有着RRAM的身影:
以中国科学院微电子研究所微电子刘明院士、张锋研究员为主导的团队,首次设计实现了基于三维垂直结构阻变存储器的存算一体宏单元芯片,实验表明三维阻变存储器不但可以完整的实现存算一体技术,同时证明了其在低功耗以及高算力、高密度方面的优势。
其次是在产界,芯片设计、制造厂商纷纷将RRAM纳入到自己的规划之中:
在代工厂方面,台积电、Crossbar、联电、中芯国际以及昕原半导体等均已建立了可量产的商业化RRAM产线:
例如2022年6月,昕原半导体宣布其RRAM新型存储技术通过严苛测试,“昕·山文”安全存储系列RRAM产品成功交付工控领域头部企业禾川科技,实现在工业自动化控制核心部件的商用量产。
在商业化方面,RRAM在市面上主要有两大应用方向,分别是存储应用与存算应用。
在存储应用上,目前有英特尔、松下等大厂将RRAM用于MCU领域:
● 2013年7月,松下推出了8位MCU,该MCU集成了0.18微米RRAM技术,成为第一个将RRAM技术商业化的大厂;
● 2022年11月,英特尔宣布,将非易失性存储器RRAM引入英飞凌的下一代 AURIX ™微控制器 (MCU)
除此之外,在去年的各大展会、论坛上,也有多家初创企业认可了RRAM的发展潜力,提出计划使用或者转向RRAM作为其未来发展AI芯片的存储介质。
在存算应用上,目前仅有国内的亿铸科技,试图基于RRAM通过存算一体架构实现AI大算力芯片,将其应用在中心侧与边缘侧的应用场景中,着眼于解决目前AI芯片“能效比不理想、算力密度不满足市场要求、软件部署成本高及效率低”等痛点。
学界、产界正将RRAM推向“C位”,视为团宠,这背后是AI市场的驱动。
现阶段,自动驾驶、智算中心、AR/VR元宇宙、ChatGPT等高密度计算场景的蓬勃发展,带动了以AI芯片为首的一大批新型半导体技术的爆发。
机会与挑战并存,随着AI算力需求走向100Tops、1000Tops甚至更高水平,以及对于能效比需求走向10TOPS/W、甚至100TOPS/W以上,传统冯·诺伊曼架构“招架不住”了。
这是因为在冯·诺伊曼架构之下,芯片的存储、计算区域是分离的。计算时,数据需要在两个区域之间来回搬运,而随着神经网络模型层数、规模以及数据处理量的不断增长,数据已经面临“跑不过来”的境况,成为高效能计算性能和功耗的瓶颈,也就是业内俗称的“存储墙”。
存储墙相应地也带来了能耗墙、编译墙(生态墙)的问题。例如编译墙问题,是由于大量的数据搬运容易发生拥塞,编译器无法在静态可预测的情况下对算子、函数、程序或者网络做整体的优化,只能手动、一个个或者一层层对程序进行优化,耗费了大量时间。
这“三堵墙”导致算力无谓浪费:据统计,在大算力的AI应用中,数据搬运操作消耗90%的时间和功耗,数据搬运的功耗是运算的650倍。
于是,能够打破这三堵墙的“存算一体架构”渐入人们的视野。该架构将存储和计算的融合,彻底消除了访存延迟,并极大降低了功耗。同时,由于计算完全耦合于存储,因此可以开发更细粒度的并行性,获得更高的性能和能效。
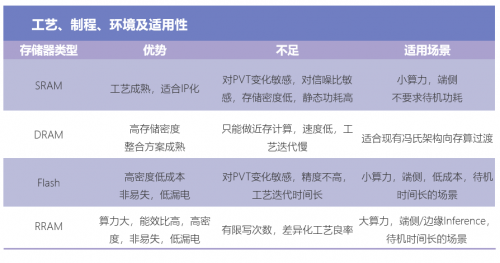
目前,实现存算一体有两种存储器件的选择:
● 第一种是基于易失性存储器,例如DRAM和SRAM,但由于DRAM制造工艺和逻辑计算单元的制造工艺不同,无法实现良好的片上融合,而SRAM难以进行片上大规模集成,同时,因为SRAM和DRAM是易失性存储器,需要持续供电来保存数据,仍存在功耗的问题。
● 第二种是结合非易失性新型存储器。新型存储器通过阻值变化来存储数据,而存储器加载的电压等于电阻和电流的乘积,相当于每个单元可以实现一个乘法运算,再汇总相加便可以实现矩阵乘法。在这种情况下,同一单元就可以完成数据存储和计算,消除了数据访存带来的延迟和功耗,是真正意义上的存算一体。
另外,传统存储器所具有的易失性、微缩性差等问题可以被新型非易失性存储器很好地解决。RRAM在AI大算力场景下似乎更具优势:
目前可用于存算一体的成熟存储器有NOR FLASH、SRAM、DRAM、RRAM、MRAM等。相比之下,RRAM具备低功耗、高计算精度、高能效比和制造兼容CMOS工艺等优势:
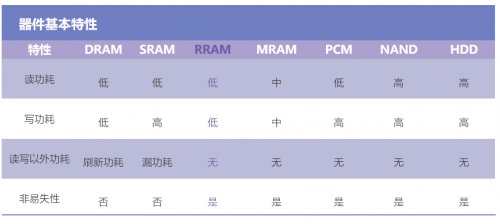
也就是说,AI计算整体市场的驱动,引发了RRAM在存算一体这一方向的爆发。随着人工智能市场规模不断扩大,属于RRAM的市场爆发很快就会到来,学界、产界难免要“蜂拥而至”。
AI大算力,RRAM的“用武之地”
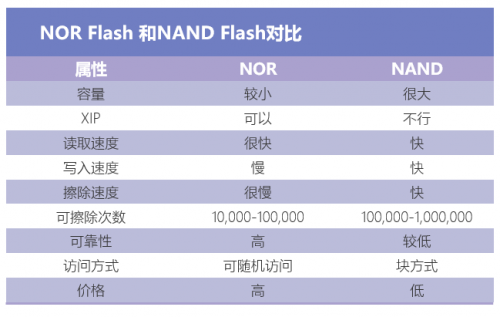
当我们回顾存储器的发展时发现,目前主流的存储介质NOR FLASH,同样经历了不被看好阶段:
2000年前后的功能机时代,手机对内存的要求不高,NOR Flash凭借着NOR+PSRAM的XIP架构,更快的读取速度、可随机访问等特点,得到快速发展。
好景不长,没过几年NOR Flash市场便不断萎缩:
2009—2016 年 NOR Flash 市场规模一路下降至低于20亿美元,存储大厂三星、美光等公司都逐步退出NOR市场。这是因为,到了智能机时代,大量吃内存的APP涌现,NOR的容量小、成本高的缺点无法被掩盖,逐渐被容量充足、成本更低的NAND给取代。
但就在各大厂商关停NOR产线的同时,NOR Flash喜迎“第二春”。最主要的原因是,下游需求旺盛的AMOLED急需NOR Flash来“救场”。
随着手机厂商苹果选择了AMOLED屏幕,AMOLED的渗透率得到了大幅提升,AMOLED相较于LCD而言,优点众多,但亮度不均匀、存在残像仍是它面临的两个主要难题,也就需要用到补偿技术。
业内纷纷选择外部补偿模式(内部补偿模式成本过高,技术难以达到):挂一个存储器随时解决AMOLED面板的蓝色光会随时间消退的问题。
此时,NOR Flash的高可靠性、快速读取使其比NAND Flash更为合适,且在外部补偿模式下,屏幕对于容量的要求并不高。
于是,NOR Flash的需求又被快速带动起来,华邦、兆易创新(目前国内NOR Flash龙头)迅速崛起。
可以看到,找到合适的赛道,是以往存储器大放光彩的转折点。
RRAM与AI大算力赛道,也同样如此。
原先,大家对RRAM的期望是纯存储应用,希望其成为下一代主流存储技术。但其容量和闪存相比,差别还很大,故在存储应用领域,RRAM并不是最佳的选择,也就一直“被耽误”。
如今,在AI大算力时代,由于存算一体架构解决了存储墙等问题,可以极大降低功耗,提升运算能效比。同时,RRAM工艺逐渐成熟,可以支持大算力芯片的量产。此时,RRAM具备的“低功耗、低延迟性、高密度”等优势愈发凸显,通过将RRAM存储技术与存算一体架构结合,无疑会产生1+1>2的效果,从而打造高算力、高能效比的AI芯片。
而在AI时代的多个应用中,RRAM更适用于AI大算力赛道。
AI大算力赛道,正面临着“井喷”的需求:
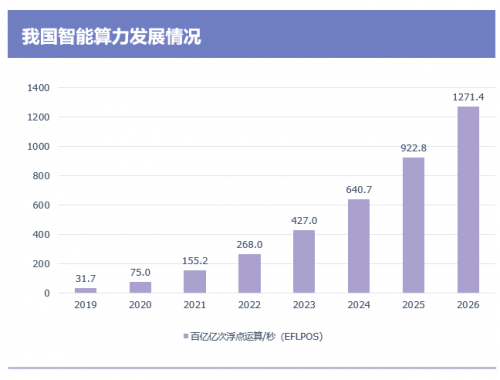
根据IDC、浪潮信息联合发布的《2022-2023中国人工智能计算力发展评估报告》显示,2021年中国智能算力规模达到155.2EFLOPS,预计2026年将达到127.4EFLOPS,年复合增长率达到52.3%。
这是因为,随着技术的突破、模型规模的不断增长,需要消化更大规模的数据,也意味着更高的算力需求。据OpenAI统计,从2012年到2020年,人工智能模型训练消耗的算力增长了30万倍,平均每3.4个月翻一番超过了摩尔定律的每18个月翻番的增速。
故,为满足对算力的要求,各行各业各地都在建设智算中心:
1月11日,由国家信息中心联合浪潮信息发布的《智能计算中心创新发展指南》显示,当前全国范围形成智算中心建设的热潮:全国目前有超过30个城市正在建设或提出建设智算中心,整体布局以东部地区为主,并逐渐向中西部地区拓展。
AI大算力的下游市场“嗷嗷待哺”,基础设施正快马加鞭地建设,RRAM“大显身手”指日可待:
据国内基于RRAM设计存算一体AI大算力芯片的亿铸科技创始人、董事长兼CEO熊大鹏博士介绍,基于RRAM的存算一体AI大算力芯片可以在不增加物理空间的前提下,大大提升算力密度,大幅度降低能耗,减少采购和运维成本。
假以时日,RRAM将在AI大算力赛道上造就下一个里程碑。














评论