
移动算法 而非巨量数据
机器学习神经网络进步使我们能够处理越来越大量储存资料。传统方法是将数据传输到算法设备,但是这种移动巨量数据(高达 1 PB)以供可能只有几十兆位元算法来进行处理真的有意义吗?因此,在靠近数据储存位置处理数据的想法引起了很多关注。本文研究了计算储存理论和实践,以及如何使用计算储存处理器 (CSP) 为许多计算密集型任务提供硬件加速和更高性能,而不会给主机处理器带来大量负担。
数据集崛起
近年来,神经网络算法在汽车、工业、安全和消费等应用中使用显著增加。基于边缘物联网传感器通常只处理少量数据,因此所使用算法占用很少代码空间。然而,伴随微控制器处理能力提高和功耗降低,机器学习算法在边缘应用中使用开始呈指数级增长。卷积神经网络用于视觉处理以及工业和汽车应用中对象检测。例如,视觉处理系统可用于检测标签是否正确贴在高速工业生产线的瓶子上。
视觉系统还适用于更复杂任务,例如根据对象类型、条件和大小对物体进行分类。在汽车应用中,使用实时视觉系统进行多物体分类和识别能够更充分利用神经网络。除了具体市场应用外,神经网络也可用于科学研究。例如,它可广泛用于处理由分布在全球各地遥感卫星和地震监测传感器收集的大量资料。
在大多数应用中,机器学习用于增加正确观察和分类对象概率。然而,为此目的的训练算法需要大型数据集(高达 PB),这些数据集移动、处理和储存都具有非常大挑战性。
计算储存
近年来,基于NAND闪存普及程度快速增长,这种技术不再局限于高端储存,还可用于一般商品固态储存,一个典型用例是正在取代笔记本电脑和桌面计算机中的磁盘驱动器。固态储存普及,加上NVMe协议兴起(支持更高带宽、更低延迟和更高储存密度)以及 PCIe 连接带来的更高数据速率,为我们提供了重新思考如何使用储存和计算资源方法的机会。
图一 : 具有计算和储存平面的传统计算架构。(source:BittWare)
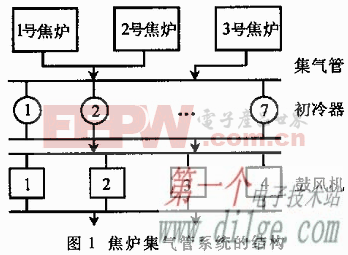
图一所示传统方法可在计算平面和储存平面之间移动数据。计算资源用于数据传输、处理、压缩和解压缩以及许多其他系统相关任务。所有这些任务的组合对可用资源造成沉重负担。
图二 : 计算储存架构。(source:BittWare)
图二所示计算储存架构是一种更有效方法。它透过使用硬件加速器(通常在FPGA 上)来执行计算密集型任务。将 NVMe 闪存靠近并连接到硬件加速器,CPU 不再需要将数据从其储存位置移动到处理位置附近,从而显著降低运行负担。如图三所示,FPGA在其中扮演计算储存处理器角色,从而能够减轻 CPU 处理压缩、加密或神经网络推理等计算密集型任务负担。
图三 : 计算储存处理器 (CSP)。(source:BittWare)
基于 FPGA 的计算储存处理器
计算储存处理器的一个例子是 BittWare IA-220-U2,它采用 Intel Agilex FPGA(具有多达 140 万个逻辑组件、多达 16GB DDR4 内存和四个 PCIe Gen4 接口)。 DDR4 SDRAM 能够以高达 2,400 MT/s 速率传输数据,它使用符合 SFF-8639 标准的 2.5 英寸 U.2 封装和对流冷却散热器,能够整合到 U.2 NVMe 储存数组,如图 4 所示。
图四 : BittWare IA220-U2。(source: BittWare)
BittWare IA-220-U2通常消耗 20W功率,并支持热插入,它具有板载 NVMe-MI且兼容 SMBus 控制器、SMBus FPGA 闪存控制功能以及 SMBus 访问板载电压和温度监测传感器,可理想适用于企业 IT 和数据中心等应用。BittWare IA-220-U2 功能方块图和主要特性如图 5 所示。
图五 : BittWare IA-220-U2 功能方块图和特性。(source:BittWare)
IA-220-U2 设计用于在大容量应用中执行各种加速任务,包括算法推理、压缩、加密和散列(hashing)、影像搜索和数据库分类以及重复数据删除等。
使用 BittWare IA-220-U2 实现 CSP
BittWare IA -220-U2 可以使用 Eideticom 的 NoLoad IP 作为预配置解决方案提供。或者,它可以为客制化应用进行使用者程序设计。
透过提供包含 PCIe 驱动器、电路板监控设备以及电路板库的 SDK,BittWare可用来支持客制开发。可以使用Intel Quartus Prime Pro 和高级综合工具链以及设计流程来执行 FPGA 应用开发。

图六 : Eideticom NoLoad IP 硬件特性。(来源:BittWare)
Eideticom 的 NoLoad IP 包括一个预配置即插即用解决方案,该解决方案采用基于 BittWare U.2 模块的整合软件堆栈,还提供一组硬件加速计算储存服务 (CSS),在图 6 中以橙色突出显示。
图七 : Eideticom 的 NoLoad IP 软件堆栈。(source:BittWare)
图七 展示了 NoLoad IP 软件组件,其中包括内核空间堆栈文件系统和使用 NoLoad CSS 的 NVMe 驱动器,以及面向具体应用的使用者空间 Libnoload。
Eideticom NoLoad CPU 不可知解决方案卸除功能将服务质量 (QoS) 提高了 40 倍,并还有较低拥有成本和更低功耗优势。
卸除计算密集型任务可提高通量
使用基于 NVMe 计算储存架构可在大型数据处理应用中提供更高性能并使用更少功率。这种架构透过使用基于 FPGA 的计算储存处理器来执行计算密集型任务,降低了将资料从储存点传输到处理器(并返回)的要求。在 NVMe NAND 闪存数组上处理点附近储存数据可以节省能源,同时还可以减少延迟和所需带宽。




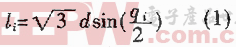

评论