
无需「域外」文本,微软:NLP就应该针对性预训练
在生物医学这样的专业领域训练NLP模型,除了特定数据集,「域外」文本也被认为是有用的。但最近,微软的研究人员「大呼」:我不这么觉得!
本文引用地址:http://www.amcfsurvey.com/article/202008/416905.htm什么是预训练?这是一个拷问人工智能「门外汉」的灵魂问题。生而为人,我们不需要一切从零开始学习。但是,我们会「以旧学新」,用过去所学的旧知识,来理解新知识和处理各种新任务。在人工智能中,预训练就是模仿人类这个过程。
预训练(pre-training)这个词经常在论文中见到,指的是用一个任务去训练一个模型,帮助它形成可以在其他任务中使用的参数。
用已学习任务的模型参数初始化新任务的模型参数。通过这种方式,旧的知识可以帮助新模型从旧的经验中成功地执行新任务,而不是从零开始。
以前的研究已经表明,在像生物医学这样的专业领域,当训练一个NLP模型时,特定领域的数据集可以提高准确性。不过,还有一个普遍的认识是,「域外」文本也有用。但是!微软研究人员对这一假设提出了质疑。
近日,微软研究人员提出一种人工智能技术,针对生物医学NLP的领域特定语言模型预训练。并自信地说,通过从公开的数据集中编译一个「全面的」生物医学NLP基准,在包括命名实体识别、基于证据的医学信息提取、文档分类等任务上取得了最先进的成果。
他们认为,「混合领域」预训练?不就是迁移学习的另一种形式吗?源领域是一般文本(如新闻),目标领域是专门文本(如生物医学论文)。
在此基础上,针对特定领域的生物医学NLP模型的预训练总是优于通用语言模型的预训练,说明「混合领域」预训练并不完美。
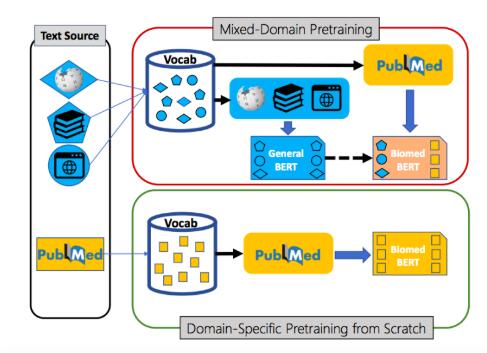
神经语言模型预训练的两种范式。「混合领域」预训练(上);只使用域内文本预训练(下)
如此自信,研究人员是有证据的。他们通过对生物医学NLP应用的影响,比较了训练前的建模和特定任务的微调。
第一步,他们创建了一个名为生物医学语言理解和推理基准(BLURB)的基准,该基准侧重于PubMed(一个生物医学相关的数据库)提供的出版物,涵盖了诸如关系提取、句子相似度和问题回答等任务,以及诸如是/否问题回答等分类任务。为了计算总结性分数,BLURB中的语料库按任务类型分组,并分别打分,之后计算所有的平均值。

为了评估,他们又在最新的PubMed文档中生成了一个词汇表并训练了一个模型:1400万篇摘要和32亿个单词,总计21GB。在一台拥有16个V100显卡的Nvidia DGX-2机器上,培训了大约5天时间。这个模型具有62,500步长和批量大小,可与以前生物医学预训练实验中使用的计算量相媲美。
又一个自信,研究人员说他们的模型——PubMedBERT,是建立在谷歌的BERT之上。
那个牛掰掰的BERT?Google 在 2018 年提出的一种 NLP 模型,成为最近几年 NLP 领域最具有突破性的一项技术。

但有趣的是,将PubMed的全文添加到预训练文本(168亿字)中会让性能略有下降,直到预训练时间延长。但研究人员将这部分归因于数据中的噪声。
“在本文中,我们挑战了神经语言预训练模型中普遍存在的假设(就是前面说的「混合领域」预训练),并证明了从「无」开始对特定领域进行预训练可以显著优于「混合领域」预训练。「为生物医学NLP的应用带来了新的、最先进的结果,」研究人员写道,「我们未来会进一步探索特定领域的预培训策略,将BLURB基准扩展到临床或其他高价值领域。」
为了鼓励生物医学NLP的研究,研究人员创建了一个以BLURB基准为特色的排行榜。他们还以开源的方式发布了预先训练过的特定任务模型。
研究已发布于预印论文网站arxiv上。








评论