
用PCA还是LDA?特征抽取经典算法PK
在之前的格物汇文章中,我们介绍了特征抽取的经典算法——主成分分析(PCA),了解了PCA算法实质上是进行了一次坐标轴旋转,尽可能让数据映射在新坐标轴方向上的方差尽可能大,并且让原数据与新映射的数据在距离的变化上尽可能小。方差较大的方向代表数据含有的信息量较大,建议保留。方差较小的方向代表数据含有的信息量较少,建议舍弃。今天我们就来看一下PCA的具体应用案例和特征映射的另一种方法:线性判别分析(LDA)。
本文引用地址:http://www.amcfsurvey.com/article/201901/396508.htmPCA案例
在机器学习中,所使用的数据往往维数很大,我们需要使用降维的方法来突显信息含量较大的数据,PCA就是一个很好的降维方法。下面我们来看一个具体的应用案例,为了简单起见,我们使用一个较小的数据集来展示:
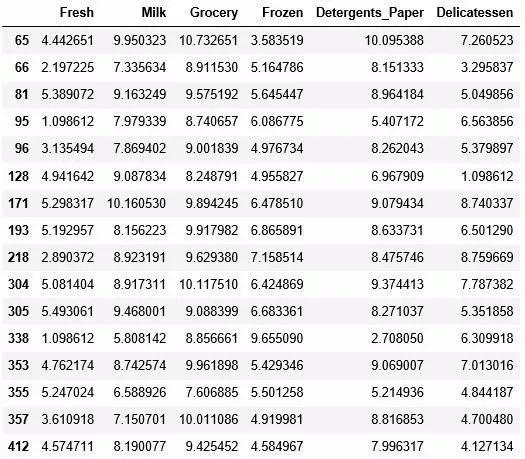
显而易见,我们数据有6维,维数虽然不是很多但不一定代表数据不可以降维。我们使用sklearn中的PCA算法拟合数据集得到如下的结果:
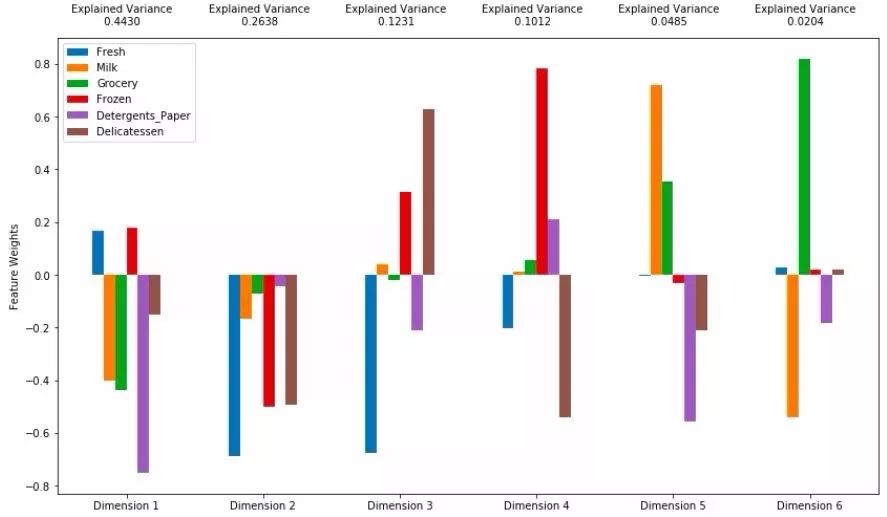
我们可以看到经过PCA降维后依然生成了新的6个维度,但是数据映射在每一个维度上的方差大小不一样。我们会对每一个维度上的方差进行归一化,每一个维度上的方差量我们称为可解释的方差量(Explained Variance)。由图可知,每一个维度上可解释方差占比为:0.4430,0.2638,0.1231,0.1012,0.0485,0.0204。根据经验来说我们期望可解释的方差量累计值在80%以上较好,因此我们可以选择降维降到3维(82.99%)或者4维(93.11%),括号中的数字为累计可解释的方差量,最后两维方差解释只有7%不到,建议舍去。图中的柱状图表示原维度在新坐标轴上的映射向量大小。在前两维度上表现如下图所示:

PCA虽然能实现很好的降维效果,但是它却是一种无监督的方法。实际上我们更加希望对于有类别标签的数据(有监督),也能实现降维,并且降维后能更好的区分每一个类。此时,特征抽取的另一种经典算法——线性判别分析(LDA)就闪亮登场了。
LDA简介
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
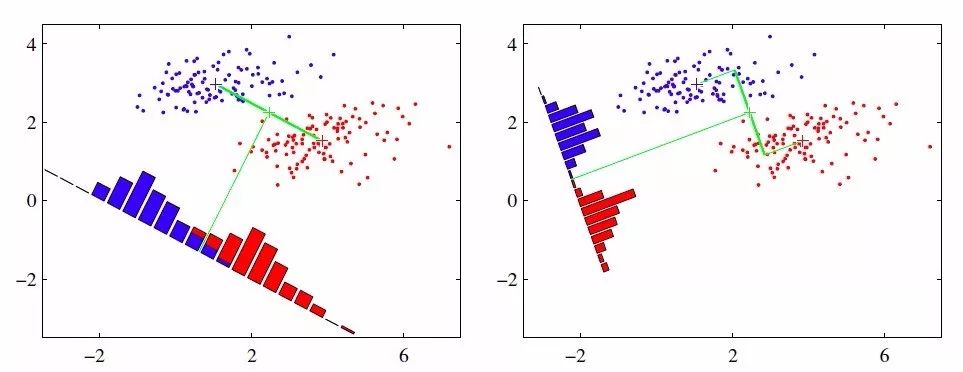
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。LDA的降维效果更像右图,它能在新坐标轴上优先区分出两个类别,它是如何实现的呢?
LDA的原理
LDA的主要思想是“投影后类内方差最小,类间方差最大”。实质上就是很好的区分出两个类的分布。我们知道衡量数据分布的两个重要指标是均值和方差,对于每一个类,他们的定义如下:
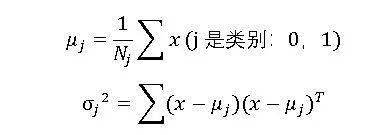
与PCA一样,LDA也是对数据的坐标轴进行一次旋转,假设旋转的转移矩阵是w,那么新的旋转数据可以表示为:
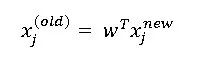
同理,两个类别的中心点也转换成了:
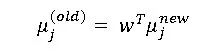

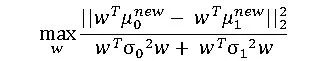
我们求解这个最优化问题,即可求出转移变换矩阵w,即LDA的最终结果。
PCA vs LDA
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。首先我们看看相同点:
1、两者均可以对数据进行降维
2、两者在降维时均使用了矩阵特征分解的思想
3、两者都假设数据符合高斯分布
我们接着看看不同点:
1、LDA是有监督的降维方法,而PCA是无监督的降维方法
2、LDA降维最多降到类别数k-1的维数,而PCA没有这个限制
3、LDA除了可以用于降维,还可以用于分类
4、LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向
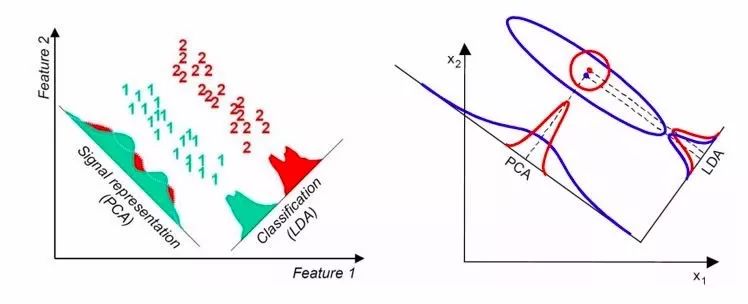
在某些数据分布下LDA比PCA降维较优(左图),在某些数据分布下,PCA比LDA降维较优。
好了,以上就是本期格物汇的内容,我们下期见。



评论