
人工智能入门基础
对人工智能领域来说,2016年是值得纪念的一年。不仅计算机「学」得更多更快了,我们也 懂得了如何改进计算机系统。一切都在步入正轨,因此,我们正目睹着前所未有的重大进步:我们有了能用图片来讲故事的程序,有了无人驾驶汽车,甚至有了能够 创作艺术的程序。如果你想要了解2016年的更多进展,请一定要读一读这篇文章。AI技术已逐步成为许多技术的核心,所以,理解一些常用术语和工作原理成为了一件很重要的事。
本文引用地址:http://www.amcfsurvey.com/article/201710/367893.htm人工智能是什么?
人工智能的很多进步都是新的统计模型,其中绝大多数来自于一项称作「人工神经网络」(artificial neural networks)的技术,简称ANN。这种技术十分粗略地模拟了人脑的结构。值得注意的是,人工神经网络和神经网络是不同的。很多人为了方便起见而把 「人工神经网络」中的人工二字省略掉,这是不准确的,因为使用「人工」这个词正是为了与计算神经生物学中的神经网络相区别。以下便是真实的神经元和神经突 触。
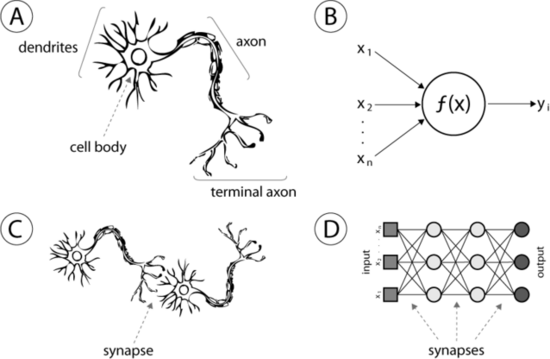
我 们的ANN中有称作「神经元」的计算单元。这些人工神经元通过「突触」连接,这里的「突触」指的是权重值。这意味着,给定一个数字,一个神经元将执行某种 计算(例如一个sigmoid函数),然后计算结果会被乘上一个权重。如果你的神经网络只有一层,那么加权后的结果就是该神经网络的输出值。或者,你也可 以配置多层神经元,这就是深度学习的基础概念。
它们起源何处?
人工神经网络不是一个新概念。事实上,它们过去的名字不叫神经网络,它们最早的状态和我们今天所看到的也完全不一样。20世纪60年代,我们把它称之为感知 机(perceptron),是由McCulloch-Pitts神经元组成。我们甚至还有了偏差感知机。最后,人们开始创造多层感知机,也就是我们今天 通常听到的人工神经网络。
如果神经网络开始于20世纪60年代,那为什么它们直到今天才流行起来?这是个很长的故事,简单来说,有一些原因阻碍了ANN的发展。比如,我们过去的计算 能力不够,没有足够多的数据去训练这些模型。使用神经网络会很不舒服,因为它们的表现似乎很随意。但上面所说的每一个因素都在变化。如今,我们的计算机变 得更快更强大,并且由于互联网的发展,我们可使用的数据多种多样。
它们是如何工作的?
上面我提到了运行计算的神经元和神经突触。你可能会问:「它们如何学习要执行何种计算?」从本质上说,答案就是我们需要问它们大量的问题,并提供给它们答 案。这叫做有监督学习。借助于足够多的「问题-答案」案例,储存在每个神经元和神经突触中的计算和权值就能慢慢进行调整。通常,这是通过一个叫做反向传播 (backpropagation)的过程实现的。
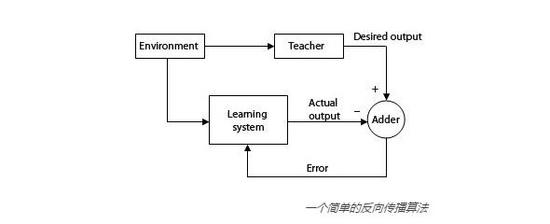
想象一下,你在沿着人行道行走时看到了一个灯柱,但你以前从未见过它,因此你可能会不慎撞到它并「哎呦」惨叫一声。下一次,你会在这个灯柱旁边几英寸的距离 匆匆而过,你的肩膀可能会碰到它,你再次「哎呦」一声。直到第三次看到这个灯柱,你会远远地躲开它,以确保完全不会碰到它。但此时意外发生了,你在躲开灯 柱的同时却撞到了一个邮箱,但你以前从未见过这个邮箱,你径直撞向它——「灯柱悲剧」的全过程又重现了。这个例子有些过度简化,但这实际上就是反向传播的 工作原理。一个人工神经网络被赋予多个类似案例,然后它试着得出与案例答案相同的答案。当它的输出结果错误时,这个错误会被重新计算,每个神经元和神经突 触的值会通过人工神经网络反向传播,以备下次计算。此过程需要大量案例。为了实际应用,所需案例的数目可能达到数百万。
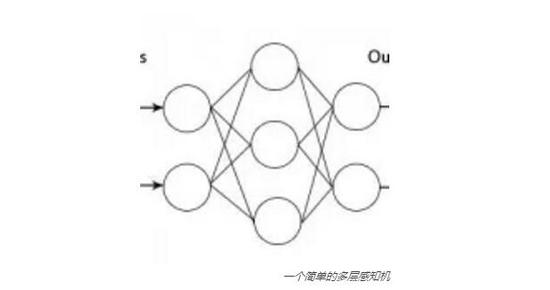
既然我们理解了人工神经网络以及它们的部分工作原理,我们可能会想到另外一个问题:我们怎么知道我们需要多少神经元?为什么前文要用粗体标出「多层」一词? 其实,每层人工神经网络就是一个神经元的集合。在为ANN输入数据时我们有输入层,同时还有许多隐藏层,这正是魔法诞生之地。最后,我们还有输出 层,ANN最终的计算结果放置于此供我们使用。
一 个层级本身是神经元的集合。在多层感知机的年代,我们起初认为一个输入层、一个隐藏层和一个输出层就够用了。那时是行得通的。输入几个数字,你仅需要一组 计算,就能得到结果。如果ANN的计算结果不正确,你再往隐藏层上加上更多的神经元就可以了。最后我们终于明白,这么做其实只是在为每个输入和输出创造一 个线性映射。换句话说,我们了解了,一个特定的输入一定对应着一个特定的输出。我们只能处理那些此前见过的输入值,没有任何灵活性。这绝对不是我们想要 的。
如今,深度学习为我们带来了更多的隐藏层,这是我们如今获得了更好的ANN的原因之一,因为我们需要数百个节点和至少几十个层级,这带来了亟需实时追踪的大 量变量。并行程序的进步也使我们能够运行更大的ANN批量计算。我们的人工神经网络正变得如此之大,使我们不能再在整个网络中同时运行一次迭代。我们需要 对整个网络中的子集合进行批量计算,只有完成了一次迭代,才可以应用反向传播。
有几种类型?
在今天所使用的深度学习中,人工神经网络有很多种不同的结构。典型的ANN中,每个神经元都与下一层的每个神经元相连接。这叫做前馈人工神经网络(尽管如 此,ANN通常来说都是前馈的)。我们已经知道,通过将神经元与其他神经元按特定模式相连接,在处理一些特定情景的问题时,我们就会得出更好的结论。
1、递归神经网络
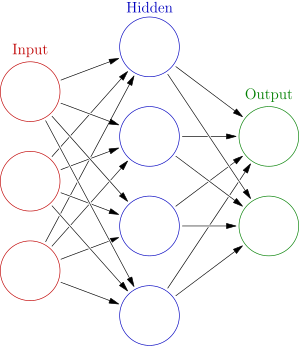
递归神经网络(RNN)的设计初衷是为了解决神经网络不能基于过去知识做出决策的缺陷。典型的ANN已经在训练中学会了基于文本做出决策,但是一旦它开始为实用做决策,这些决定之间就是彼此独立的。
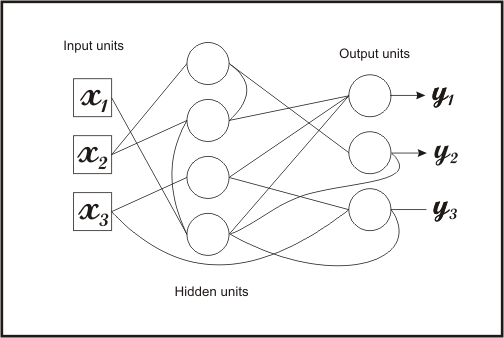
一个递归神经网络
为什么我们会想要这样的东西?好吧,想一想玩21点游戏。如果一开始你得到4和5,你就会知道2以下的牌都不在牌堆中。这种信息会帮助你决定是否要拿牌。 RNN在自然语言处理中十分有用,因为前文的字词有助于理解文中其他词语的含义。虽然有不同类型的实现方式,但是目的都是一样的。我们想要保留信息。为了 达到这一目的,我们可以通过双向递归神经网络( bi-directional RNN)或执行一个能根据每次前馈来进行调整的递归隐藏层。如果你想学习更多有关RNN的知识,可以查阅这篇博 客:http://karpathy.github.io/2015/05/21/rnn-effectiveness/。
说到这里,就不得不提到记忆网络( Memory Networks),这一概念是说,如果我们想要理解诸如电影或者书中那些构筑于彼此之上的事件时,就必须记住比一个RNN或LSTM(长短期记忆人工神经网络,一种时间递归神经网络)更多的信息。
Sam走进厨房。
Sam拿起苹果。
Sam走进卧室。
苹果掉到了地上。
问:苹果在哪儿?
答:卧室里。
这是这篇论文(http://arxiv.org/pdf/1503.08895v5.pdf)中的例子。
2、卷积神经网络
卷积神经网络(CNN)有时被称为LeNets(以Yann LeCun命名),是层间随机相连的人工神经网络。然而,以这样的方式设置突触是为了有助于减少需要优化的参数量。通过标记神经元连接的某种对称性,你能 「重新使用」神经元以得到完全相同的副本,而不需要同等数量的突触。由于CNN能识别出周围像素的模式,因此它通常用于图像处理。当你将某一像素与其周围 的像素进行比较时,会包含冗余信息。由于存在对称性,你可以压缩类似信息。这听起来像是CNN的完美情况,Christopher Olah也有一篇关于理解 CNNs和其他类型的ANNs的优质博客(http://colah.github.io/posts/2014-07-Conv-Nets- Modular/ )。还有一篇关于CNN的博客:http://www.wildml.com/2015/11/understanding- convolutional-neural-networks-for-nlp/ 。
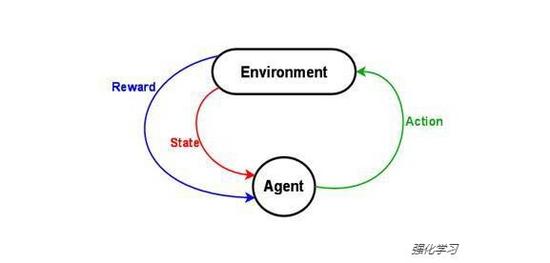
3、强化学习
我想要探讨的最后一种 ANN的类型是强化学习(Reinforcement Learning)。强化学习是一个专业术语,用来描述计算机在尝试将某种回报最大化时所表现出来的行为,这意味着它本身不是一个人工神经网络的结构。然 而,你能用强化学习或遗传算法来构建你以前从没想过要用的人工神经网络结构。 YouTube用户SethBling上传的用强化学习系统来构建可以自己玩Mario游戏的人工神经网络的视频就是个很好的例子。
另一个强化学习的例子是DeepMind公司的视频中展示的能教程序玩各种Atari游戏。
结论
现在,你应该对目前最先进的人工智能有了一定的了解。神经网络正在驱动你能想到的几乎所有事情,包括语言翻译、动物识别、图片捕捉、文本摘要等等。在未来,你将越来越多地听到它的名字。











评论