
浅谈存储器体系结构的未来发展趋势
对存储器带宽的追求成为系统设计最突出的主题。SoC设计人员无论是使用ASIC还是FPGA技术,其思考的核心都是必须规划、设计并实现存储器。系统设计人员必须清楚的理解存储器数据流模式,以及芯片设计人员建立的端口。即使是存储器供应商也面临DDR的退出,要理解系统行为,以便找到持续发展的新方法。
本文引用地址:http://www.amcfsurvey.com/article/201710/367190.htm曾经在斯坦福大学举办的热点芯片大会上,寻求带宽成为论文讨论的主题,设计人员介绍了很多方法来解决所面临的挑战。从这些文章中,以及从现场工作的设计人员的经验中,可以大概看出存储器系统体系结构今后会怎样发展。
存储器壁垒
基本问题很明显:现代SoC时钟频率高达吉赫兹,并且具有多个内核,与单通道DDR DRAM相比,每秒会发出更多的存储器申请。仅仅如此的话,会有很显然的方案来解决这一问题。但是,这背后还有重要的精细结构,使得这一问题非常复杂,导致有各种各样的解决办法。
SoC开发人员关注的重点从高速时钟转向多个内核 , 这从根本上改变了存储器问题。不再是要求一个 CPU每秒有更高的兆字节(MBps) ,现在,我们面临很多不同的处理器——经常是很多不同类型的处理器,都要求同时进行访问。而且,存储器访问的主要模式发生了变化。科学和商业数据处理任务通常涉及到大量的局部访问,或者更糟糕的是采用相对紧凑的算法很慢的传送大量的数据。配置适度规模的本地SRAM或者高速缓存,这类任务的一个CPU对主存储器的需求并不高。
DRAM芯片设计人员利用了这种易用性,以便实现更高的密度和能效。相应的,以可预测的顺序申请大块数据时,DRAM实现了最佳比特率——它允许块间插。如果SoC不采用这种常用模式,存储器系统的有效带宽会降低一个数量级。
新的访问模式
不好的是,SoC的发展使得DRAM设计人员的假设难以实现。多线程以及软件设计新出现的趋势改变了每一内核访问存储器的方式。多核处理以及越来越重要的硬件加速意味着很多硬件要竞争使用主存储器。这些趋势使得简单的局部访问变得复杂,DRAM带宽与此有关。
多线程意味着,当一个存储器申请错过其高速缓存时,CPU不会等待:它开始执行不同的线程,其指令和数据区会在与前面线程完全不同的物理存储区中。仔细的多路高速缓存设计有助于解决这一问题,但是最终,连续DRAM申请仍然很有可能去访问不相关的存储区,即使每一线程都仔细的优化了其存储器组织。相似的,竞争同一DRAM通道的多个内核也会扰乱DRAM访问顺序。
软件中的变化也会产生影响。表查找和链接表处理会对大数据结构产生随机分散存储器访问。数据包处理和大数据算法将这些任务从控制代码转移到大批量数据处理流程,系统设计人员不得不专门考虑怎样高效的处理它们。虚拟化把很多虚拟机放到同一物理内核中,使得存储器数据流更加复杂。
传统的解决方案
这些问题并不是什么新问题——只是变复杂了。因此,芯片和系统设计人员有很多成熟的方法来满足越来越高的基带带宽需求,提高DRAM的访问效率。这些方法包括软件优化、高速缓存以及部署DRAM多个通道等。
大部分嵌入式系统设计人员习惯于首先会想到软件优化。在单线程系统中,软件在很大程度上过度使用了存储器通道,能耗较高。但是在多线程、多核系统中,软件开发人员对DRAM控制器上的实际事件顺序的影响很小。一些经验表明,他们很难改变实际运行时数据流模式。DRAM控制器可以使用重新排序和公平算法,编程人员对此并不清楚。
高速缓存的效率会更高——如果高速缓存足够大 ,能够显著减少DRAM数据流。例如,在嵌入式多核实现中,相对较小的L1指令高速缓存与规模适度的L2一同工作,能够完全容纳所有线程的热点代码,有效的减少了对主存储器的指令获取数据流。相似的,在信号处理应用中,把相对较少的数据适配到L2或者本地SRAM中,可以去掉滤波器内核负载。要产生较大的影响,高速缓存不一定要实际减少DRAM申请总数量——只需要保护主要申请源不被其他任务中断,因此,编程人员能够优化主要任务。
当芯片设计人员无法确定将要运行在SoC中的各种任务时,则倾向于只要成本允许,提供尽可能多的高速缓存:所有CPU内核和加速器的L1高速缓存、大规模共享L2,以及越来越大的管芯L3。在热点芯片大会上,从平板电脑级应用处理器到大量的服务器SoC,有很多高速缓存的实例。
在低端,AMD的Kabini SoC (图1) 就是很有趣的研究。AMD资深研究员Dan Bouvier介绍了这一芯片,它包括四个Jaguar CPU内核,共享了2兆字节(MB) L2高速缓存,而每个Jaguars有32千字节(KB)指令和数据高速缓存——并不是非传统的协议。更惊奇的是芯片的图形处理器,除了常用的颜色高速缓存以及用于渲染引擎的Z缓冲,还有它自己的L1指令高速缓存和128 KB L2。
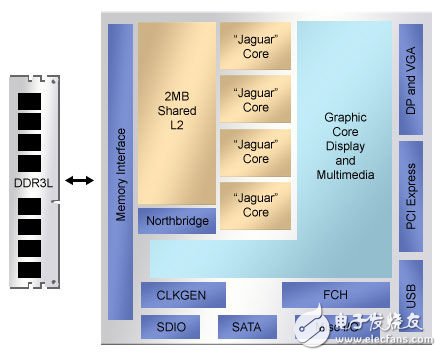
图1.AMD的Kabini SoC目标应用是平板电脑,但是仍然采用了大规模高速缓存,显著提高了存储器带宽。
而在高端则是IBM的POWER8微处理器(图2),IBM首席网络设计师Jeff Stuecheli介绍了这一款芯片。这一650 mm2、22 nm芯片包括12个POWER体系结构CPU内核,每个都有32 KB指令和64 KB数据高速缓存。每个内核还有自己512 KB的SRAM L2高速缓存,12 L2共享大容量96 MB的嵌入式DRAM L3。Stuecheli介绍说,三级连续高速缓存支持每秒230吉字节(GBps)的存储器总带宽。有趣的是,芯片还含有一个小容量会话存储器。
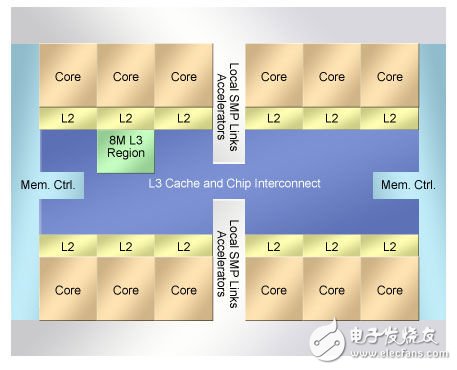
图2.IBM的POWER8体系结构在SoC管芯上实现了三级高速缓存。
在这两个SoC之间是为微软的XBOX One提供的多管芯模块(图3),微软的John Snell在大会上对此进行了介绍。模块含有一个SoC管芯,提供了丰富的存储器资源。SoC有8个AMD Jaguar内核,分成两组,每组4个。每一内核有32 KB的L1指令和数据高速缓存。每4个一组的CPU内核共享一个2 MB L2。此外,管芯上还有4个8 MB共享SRAM,它们至少为CPU提供了109 GBps的带宽。

图3.微软的XBOX One结合了大容量高速缓存、本地SRAM以及模块内DRAM,以低成本实现了更大的带宽。
使用DRAM
而XBOX One SoC还揭示了更多的信息。无论您有多大的管芯高速缓存,都无法替代巨大的DRAM带宽。SoC管芯包括四通道DDR3 DRAM控制器,为模块中的8 GB DRAM提供了68 GBps峰值带宽。
DRAM多通道的概念并不限于游戏系统。几年前,数据包处理SoC就开始提供多个完全独立的DRAM控制器。但是这种策略带来了挑战。存储器优化会更加复杂,系统设计人员必须决定哪种数据结构映射哪一通道或者控制器。当然,还有可能要求自己的DRAM控制器完成某些高要求任务,在一些嵌入式应用中,这些控制器是非常宝贵的。而DRAM多通道会很快用完引脚,用尽I/O功耗预算。
即使在FPGA设计中,引脚数量也是一个问题,设计人员应能够非常灵活的重新组织逻辑,选择较大的封装。Altera的高级系统开发套件(图4)电路板主要用于原型开发,实现宽带设计,应用领域包括HD视频处理、7层数据包检查,或者科学计算等,这是非常有用的套件。
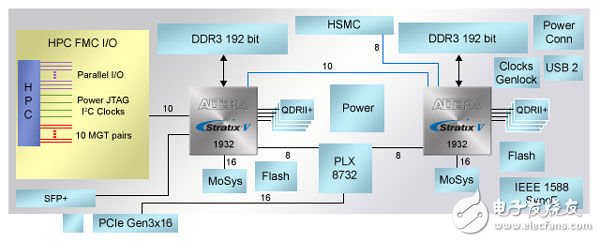
图4.Altera的高级系统开发套件极大的满足了两片大规模FPGA的存储器需求。
Mark Hoopes是Altera广播应用专家,解释了电路板应提供很大的存储器带宽,不需要详细的知道用户在两片大规模FPGA中实现的某些设计。因此,设计电路板时,Hoopes检查了现有Altera视频知识产权(IP)的存储器使用模式,调研了外部设计团队的需求。
结果让人清醒。Hoopes说:“当您查看每一项功能时,看起来都需要存储器。但是,当您把功能结合起来后,其需求非常大。在一个例子中,应用程序开发人员要求为每一片FPGA提供全256位宽DDR3接口以及四通道QDR II SRAM。即使是1932引脚封装,这也无法实现。因此,设计人员最终采用了四个SRAM块以及一个192位DDR3接口。
Hoopes指出了多个存储器控制器对于SoC非常重要。他说,IP开发人员通常能够熟练的在子系统级优化存储器,甚至能够提供他们自己经过优化的DRAM控制器。还可以让一个DRAM通道专门用于子系统,让其他IP模块运行子系统设计人员的优化措施。
未来发展
在开发板上还有另一个有趣的模块:每片FPGA连接了一个MoSys带宽引擎。这一芯片含有72 MB的DRAM,组织成256块来仿真SRAM时序,调整用于表存储等局部访问应用。非常独特的是,芯片使用了一个高速串行接口,而不是常用的DDR或者QDR并行接口。Hoopes强调说:“接口是我们包含这些组成的一个原因。我们在FPGA中有未使用的收发器。”实际是,MoSys先使用了它们。
三种理念——我们都已经分别了解了,能够融合来定义今后的存储器体系结构。这些理念是大规模嵌入式存储器阵列、使用了容错协议的高速串行接口,以及会话存储器。
MoSys芯片和IBM POWER8体系结构很好的体现了前两种理念。CPU SoC通过第二个芯片与DRAM通信:Centaur存储器缓冲。一个POWER8能够连接8个Centaurs,每个都通过一个专用每秒9.6吉比特(Gbps)的串行通道进行连接。每个Centaur含有16 MB存储器——用于高速缓存和调度缓冲,以及四个DDR4 DRAM接口,还有一个非常智能的控制器。IBM将Centaur芯片放在DRAM DIMM上,避免了在系统中跨过8个DDR4连接器。这样,设计集中了大量的存储器,最终明智的采用了快速串行链接,由重试协议进行保护。
另一热点芯片实例来自MoSys,在大会上,他们介绍了其下一代Bandwidth Engine 2。根据所采用的模式,Bandwidth Engine 2通过16个15 Gbps的串行I/O通路连接处理子系统。芯片含有四个存储器分区,每个包括64块32K 72位字:在第一代,总共72 MB。很多块通过智能的重新排序控制器以及大容量片内SRAM高速缓存,隐藏了每一比特单元的动态特性。
除了Centaur芯片所宣布的特性,Bandwidth Engine 2还在管芯上提供了会话功能。各种版本的芯片提供板上算术逻辑单元,因此,统计采集、计量,以及原子算法和索引操作等都可以在存储器中进行,不需要将数据实际移出到外部串行链路上。内部算术逻辑单元(ALU)很显然可以用于旗语和链接表应用。而其他的硬件使得芯片有些专用的特性。MoSys技术副总裁Michael Miller介绍了四种不同版本的Bandwidth Engine 2,它们具有不同的特性。
今后的篇章可能不是由CPU设计师撰写的,而是取决于低成本商用DRAM供应商。Micron技术公司具体实现了混合立方存储器(HMC)规范,开发原型,宣布了他们的接口合作伙伴。 HMC是一组DRAM块,堆叠成逻辑管芯,通过一组高速串行通路连接系统的其他部分。 Micron并没有公开讨论逻辑管芯的功能,据推测,可能含有DRAM控制和缓冲,以仿真SRAM功能,还有可能包括专用会话功能。
逻辑嵌入在存储器子系统中这一理念包括了很有趣的含义。能够访问大量的逻辑栅极和高速缓存的本地DRAM控制器实际上可以虚拟化去除劣化存储器带宽的所有DRAM芯片特性。IBM还在热点芯片大会上介绍了zEC12大型机体系结构,它在硬盘驱动直至它所控制的DRAM DIMM上应用了RAID 5协议,实际上将DRAM块用作多块、并行冗余存储器系统。相同的原理也可以用于将大块NAND闪存集成到存储器系统中,提供了RAID管理分层存储,可以用作虚拟大容量SRAM。
毫无疑问对SoC的需求越来越大。因此,串行链路和本地存储器,特别是本地智能化会完全改变我们怎样思考存储器体系结构。







评论