
Xilinx 16nm UltraScale+实现2至5倍的性能功耗比优势
台积公司的16nm FinFET工艺与赛灵思最新UltraRAM和SmartConnect技术相结合,使赛灵思能够继续为市场提供超越摩尔定律的价值优势。
本文引用地址:http://www.amcfsurvey.com/article/201610/308338.htm赛灵思凭借其28nm 7系列全可编程系列以及率先上市的20nm UltraScale™系列,获得了领先竞争对手整整一代优势,在此基础上,赛灵思刚刚又推出了其16nm UltraScale+™系列器件。客户采用该器件系列构建的系统相比采用赛灵思28nm器件所设计的类似系统的性能功耗比可提升2至5倍。这些性能功耗比优势主要取决于三大方面:采用台积电公司16FF+(即16nm FinFET Plus)工艺的器件实现方案、赛灵思的片上UltraRAM存储器以及SmartConnect创新型系统级互联-优化技术。
此外,赛灵思还推出了其第二代Zynq®全可编程SoC。Zynq UltraScale多处理SoC (MPSoC) 在单个器件中完美集成了四核64位ARM® Cortex™-A53应用处理器、32位ARM Cortex-R5实时处理器、ARM Mali-400MP图形处理器、16nm FPGA逻辑(带UltraRAM)、众多外设、安全性与可靠性特性、以及创新型电源控制技术。该新型Zynq UltraScale+ MPSoC为用户提供了系统创建所需的一切,而且利用其打造出来的系统相比采用28nm Zynq SoC所设计的系统的性能功耗比提升5倍。
FINFET进一步扩展 ULTRASCALE系列,使其具有额外的节点价值优势
赛灵思公司芯片产品管理与营销高级总监Dave Myron指出:“采用16nm UltraScale+系列,我们能够创建出比摩尔定律通常提供给用户的更高的额外节点价值优势。我们能满足LTE Advanced与早期 5G无线、Tb级有线通信、汽车高级驾驶员辅助系统以及工业物联网应用等各种下一代应用需求。UltraScale+系列使用户能够实现更大的创新,同时在各自的市场中保持领先竞争对手。”
凭借其UltraScale系列产品,赛灵思能够同时通过两个工艺节点提供器件,即台积公司的20nm平面工艺(已经发货)和现在台积公司的16FF+工艺(赛灵思预计将于2015年第四季度开始发货)。赛灵思将推出16nm UltraScale+系列的Virtex® FPGA与3D IC、Kintex® FPGA以及新型Zynq UltraScale+ MPSoC。
赛灵思公司新产品推出与解决方案市场营销总监Mark Moran表示,赛灵思决定于2013年开始推出其20nm UltraScale系列,而不是等台积公司的16FF+工艺问世后才发布。这是因为在一些应用领域,早在一年半就迫切需要20nm器件——其比28nm具有更高的性能和容量。
Moran表示:“我们的整个产品系列在设计时充分考虑到市场需求。采用20nm UltraScale架构的器件的功能更适用于那些无需UltraScale+提供的额外性能功耗比优势的市场和最终应用中的新一代产品。既然知道16nm紧跟其后,所以我先构建了20nm FinFET。同时我们在20nm上进了大量的架构修改(我们知道这是16nm的基础),可以根据市场需要提高性能和价值水平。我们有客户已经着手在我们目前提供的20nm器件上进行开发,这样只要16nm Ultra-Scale+器件一问世,他们就可以快速进行设计移植,进而加速设计上市进程。”
Myron补充说,众多Virtex UltraScale+器件会与20nm Virtex Ultra-Scale器件实现引脚兼容,这样,对需要额外性能功耗比优势的设计来说易于升级。
Myron说:“从工具角度来说,20nm UltraScale和16nm UltraScale+器件看起来几乎一样。因此使用16nm UltraScale+器件还有一大优势,那就是提升性能功耗比使其很容易达到性能和功耗目标要求。”
Myron说UltraScale+ FPGA以及3D IC相比28nm 7 系列FPGA,性能功耗比提升2倍。同时,Zynq UltraScale+ MPSoC凭借其额外的集成异构处理功能,相比采用28nm Zynq SoC构建的类似系统,性能功耗比提升5倍(如图1所示)。

图1 – 赛灵思16nm UltraScale+ FPGA和Zynq UltraScale+ MPSoC可为设计团队提供额外的节点价值优势。
源于台积公司16FF+工艺的性能功耗比优势
仅通过向16nm FinFET的工艺移植,赛灵思已推出了比28nm 7 系列器件的性能功耗比高出2倍的器件。Myron指出:“台积公司的16FF+是一种极其高效的工艺技术,这是因为其基本消除了此前采用平面晶体管实现的芯片工艺相关的晶体管电源泄漏情况。此外,我们还与台积公司通力合作,共同优化UltraScale+器件,以充分利用该新工艺技术。至少(仅从该新工艺技术的创新角度来说),UltraScale+设计相比采用28nm 7系列器件实现的设计,性能功耗比提升两倍以上。
如需了解有关赛灵思20nm UltraScale架构,以及FinFET相比平面晶体管工艺的优势的详细说明,敬请访问:《赛灵思中国通讯第84期》。
在UltraScale+系列中,赛灵思还将提供业界首款3D-on-3D器件——其采用台积公司16FF+ 3D晶体管技术实现的第三代堆叠硅片互联3D IC。
Myron指出,屡获殊荣的7系列3D IC通过在单个集成芯片上提供多个芯片,突破了摩尔定律的性能和容量极限。
Myron指出:“凭借我们的同质3D IC,我们能够突破摩尔定律的容量极限,从而可提供容量是28nm最大型单芯片FPGA容量2倍的器件。然后利用我们的首款异构器件,我们能够将FPGA芯片与高速收发器芯片组合在一起,提供28nm单芯片器件无法实现的高系统性能与带宽。利用UltraScale+ 3D IC,我们将继续提供超越摩尔定律极限的高容量与性能。”
源于ULTRARAM的性能功耗比优势
Myron说通过采用最新大型片上存储器UltraRAM,众多UltraScale+设计相对28nm将获得更多的性能功耗比提升。赛灵思将在大部分UltraScale+器件中新增UltraRAM。
Myron指出:“从根本上来说,片上存储器(如LUT RAM 或分布式RAM和Block RAM)和片外存储器(DDR或片外SRAM等)之间的差距越来越大。有很多处理器密集型应用需要不同类型存储器。尤其是当您设计更大型更复杂的设计时,就更需要较快速的片上存储器。Block RAM太细太少。而如果您将存储器放在片外,不仅会增加功耗,让I/O变得复杂,而且还会增加材料清单(BOM)成本。
这就是赛灵思开发UltraRAM的原因。Myron 指出:“我们所做的就是增加片上存储器分层结构的层数,以及能够在设计中轻松实现大型存储器模块。我们不仅帮助设计人员轻松放置恰当尺寸的片上存储器,而且时序也有保障。”
通过LUT或分布式RAM,设计人员可以添加1b和kb级大小的RAM,而BRAM可让他们添加10Mb大小的存储器模块。UltraRAM允许采用UltraScale+器件的设计人员用100Mb级的存储器块实现片上SRAM(如图2所示)。这样做,设计人员只需较少量的片外RAM (SRAM、RLDRAM和TCAM)就能够打造出性能/能效更高的系统。同时还会降低材料清单(BOM)成本。最大型的UltraScale+ 器件VU13P具有432 Mb的UltraRAM。
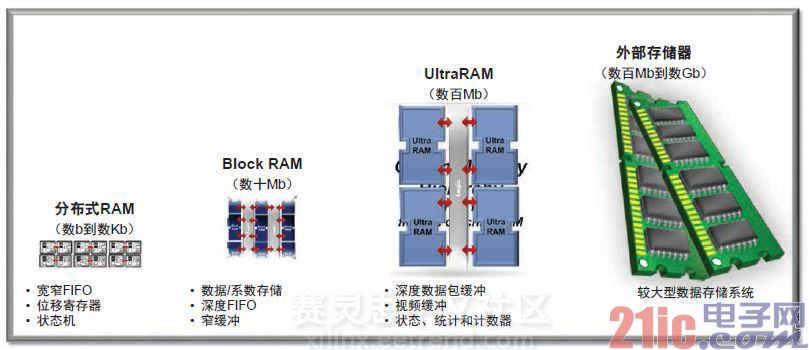
图2 – UltraRAM可填补片上存储器和片外存储器之间的存储器空白,从而使设计人员能够利用较大型的本地存储器模块创建性能更高、功耗更低的系统。
源于SmartConnect的性能功耗比优势
另一项新技术SmartConnect,可进一步提升UltraScale+设计的性能功耗比优势。
Myron说:“SmartConnect是工具和硬件协同优化的结晶,也是一种智能方法,即便设计越来越复杂,也可轻松实现。”
传统上,当工程师在设计中填充的IP模块越多,开销(功耗和占用面积需求)就越大。Myron说借助SmartConnect,赛灵思已向Vivado®设计套件增加了一些优化功能,从而可以从系统级层面考虑整个设计。SmartConnect具有最有效的互联拓扑结构,可实现最小的占位面积和最高的性能,从而充分发挥AXI互联的一些最新增强功能以及16nm UltraScale+芯片的优势。
Myron指出:“16nm UltraScale+器件在这个更高的协议层而不仅仅是在路由层上具有更高的效率。这意味着在16nm FinFET优势的基础上进一步提高性能功耗比优势。”
图3展示了一个真实的设计,其含有8个视频处理引擎,所有这些引擎均与处理器和储存器相连。Myron说:也许奇怪,像这样的一个真实世界的设计,互连逻辑竟然差不多占用了设计总面积的一半。这不仅影响功耗,而且还会限制频率。而SmartConnect可以自动重组互连模块并在不影响性能的情况下将功耗降低20%。
16nm ULTRASCALE FPGA标准测试
举例说明FPGA设计方案的性能功耗比优势,在28nm Virtex-7 FPGA中实现的48端口无线CPRI压缩与基带硬件加速器的功耗为56W(如图4)。在同一性能水平下运行的同一设计实现在16nmVirtex UltraScale+ FPGA中,功耗仅为27W,相比28nm设计功耗降低了55%,性能功耗比提升了2.1倍。加上UltraRAM和SmartConnect提供的额外性能功耗比优势,实现在VirtexUltraScale+中的设计相比28 nm Virtex-7 FPGA实现方案,性能功耗比提升了2.7倍,功耗降低了63%。
同样,在FPGA功耗预算为15W的图像处理PCI模块中,28 nmVirtex-7可实现每秒525次操作的性能。相比之下,实现在16 nm UltraScale中的同一设计则可实现每秒1255次操作的高性能,性能功耗比提升了2.4倍。加上UltraRAM和SmartConnect提供的额外性能功耗比优势,Virtex UltraScale +实现方案相比28 nm Virtex-7 FPGA实现方案,性能功耗飙升3.6倍。
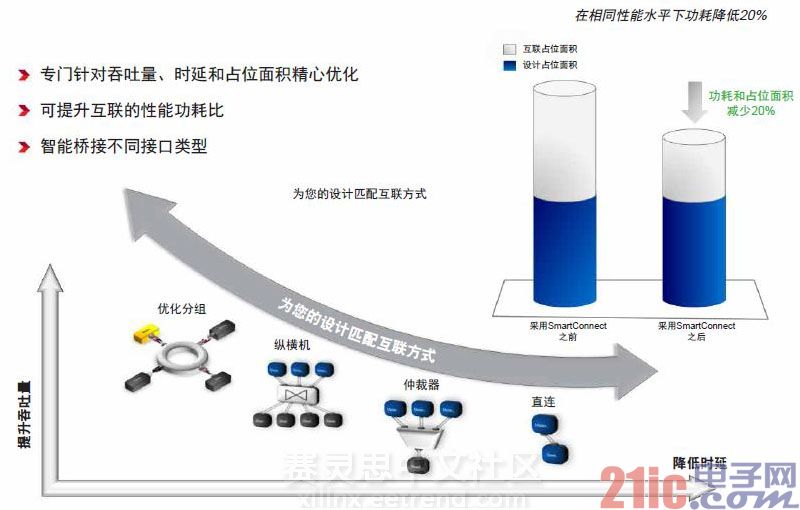
图3 – SmartConnect技术将互联所占用的面积削减达20%,这样在相同性能水平下,功耗可降低20%。
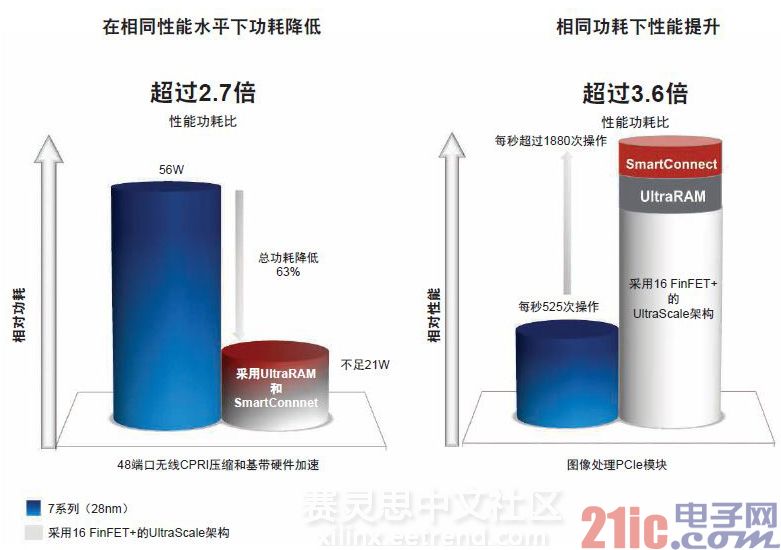
图4 – 16nm UltraScale+可为那些设法在相同功耗预算范围内更快速实现设计以及试图在相同性能水平下大幅降低功耗的设计人员保持其显著的性能功耗比优势
ZYNQ ULTRASCALE MPSOC可提供超过5倍的性能功耗比优势
尽管赛灵思原本可以采用台积公司20 nm工艺实现其第二代全可编程SoC,但公司仍会选择等待采用台积公司的16 nm FinFET工艺来实现该器件。该器件的异构多处理特性集结合16nm UltraScale架构的性能功耗比优势,可以将16nm Zynq UltraScale+ MPSoC打造成更高效的中央处理系统控制器。该器件可提供超过28 nm Zynq SoC 5倍的性能。
去年,赛灵思针对UltraScale MPSoC架构推出了其“为合适任务提供合适引擎”的使用模型,但保留了有关Zynq UltraScale+MPSoC器件应有的特定内核的细节。目前公司正发布全特性集Zynq UltraScale+ MPSoC(如图5所示)。
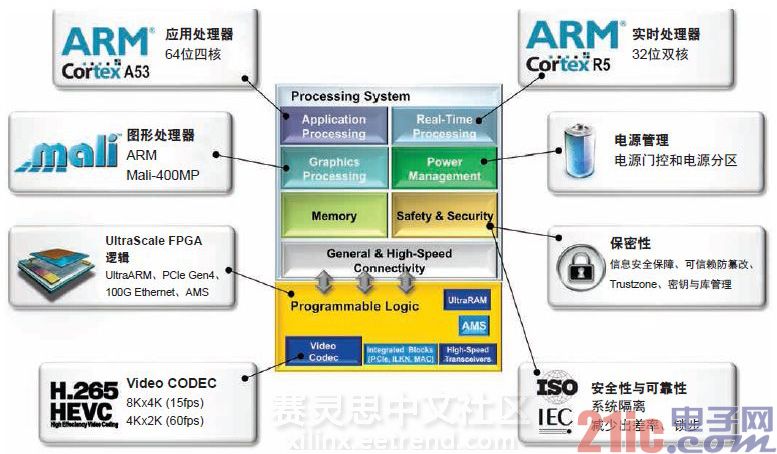
图5 – 16nm Zynq UltraScale+ MPSoC采用了一组丰富的处理引擎,设计团队能够为各项任务量身定制处理引擎,从而实现无与伦比的系统性能,进而显著提升其系统价值。
当然,初始28nm Zynq SoC的最大增值是在单个器件中完美集成了ARM处理系统和可编程逻辑。 Zynq SoC的处理系统(PS)和可编程逻辑(PL)模块通过超过3000多个互联(峰值带宽运行速率约为84 Gbps)连接在一起。PS和PL之间的紧密相连所提供的吞吐量和性能不是一个包含FPGA和独立ASSP的双芯片系统架构能简简单单实现的。
目前借助16nm UltraScale+ MPSoC,赛灵思显著提高了处理系统和可编程逻辑之间的性能,为器件提供了超过6,000次互联(峰值带宽运行速率为500Gbps)。赛灵思公司全可编程SoC产品市场营销与管理总监Barrie Mullins指出:“这使得Zynq UltraScale+ MPSoC处理系统与逻辑系统之间的连接速率比采用28nm Zynq SoC可能实现的连接速率快6倍。而且双芯片(ASSP +FPGA)架构的系统性能远远落后于此。”
Mullins说Zynq UltraScale+ MPSoC的核心是64位四核ARM Cortex-A53处理器,其可提供2倍于28nmZynq SoC的双核Cortex-A9处理系统的性能。应用处理系统具有硬件虚拟化和非对称处理功能,可全面支持ARM的TrustZone®套件的安全特性。
赛灵思还为Zynq UltraScale+MPSoC提供了一个双核ARM Cortex-R5实时处理子系统,可帮助用户向其系统添加确定性操作。实时处理器可确保为需要最高级别吞吐量、安全性和可靠性的应用提供即时系统响应。
为进一步提升处理性能,Zynq UltraScale+ MPSoC还内置了一系列的专用图形引擎。ARM Mali™-400MP专用图形加速内核可帮助主CPU分担图形密集型任务。为协助GPU,赛灵思向用于视频压缩/解压缩(支持8Kx4K (15fps)和4Kx2K (60fps)的H.265视频标准)的可编程逻辑块添加了一个硬化的视频编解码器内核。DisplayPort源内核可帮助用户加速视频数据分组,同时还避免其系统使用外部DisplayPort TX发送器芯片。
Zynq UltraScale+ MPSoC还具有一系列片上存储器增强功能。该产品系列中的最大型器件,其可编程逻辑中除Block RAM外,还包含UltraRAM。同时Zynq UltraScale+ MPSoC的处理内核共享L1和L2高速缓存。
Zynq UltraScale+ MPSoC还采用具备ECC功能的位数更宽的72位DDR接口内核(64位+ECC的8位)。该接口能提供用于DDR4的2,400Mbps速率,可支持32GB容量的更大内存深度DRAM。
Zynq UltraScale+ MPSoC上的专用安全单元可提供军事级安全性,诸如安全启动、密钥与库管理,以及防纂改功能等——这些都是设备间通信以及互联控制应用的标准需求。此外,Zynq UltraScale+MPSoC的可编程逻辑系统还采用了针对150G Interlaken、100GEthernet MAC和PCIe® Gen4的集成连接功能块。板载模拟混合信号(AMS) 内核有助于设计团队利用系统监控器(System Monitor)测试其系统。
借助所有这些功能,不是任何应用都会用到MPSoC中的每个引擎。因此,赛灵思为Zynq UltraScale+MPSoC提供了一个极其灵活的专用电源管理单元(PMU)。该内核使用户能够控制电源域和分区(粗/细精度),仅为系统正使用的处理单元供电。而且,设计团队能够对该内核进行编程,以实现动态操作,从而确保系统仅运行执行给定任务所需的功能,进而降低功耗。PMU还可实现众多安全性和可靠性,比如信号和误差的检测与缓解、安全状态模式,以及系统隔离与保护。
Myron表示,归功于上述探讨的16nm新增的所有这些处理功能,采用Zynq Ultra-Scale+ MPSoC构建的设计相比采用28nm Zynq SoC实现的设计,性能功耗比优势平均提升5倍。
16nm ZYNQ ULTRASCALEMPSOC测试标准
为了说明Zynq UltraScale+ MPSoC的性能功耗比优势,让我们来看一下该器件服务的众多应用中的3个应用的标准测试结果,不同颜色用于演示处理引擎的多样性(如图6所示)。

图6 – Zynq UltraScale+ MPSoC拥有丰富的处理模块、外设集和16nm逻辑块,可帮助设计团队创建出比采用28nm Zynq SoC实现的设计高出5倍性能功耗比优势的创新型系统。
为创建一个运行全1080p视频的视频会议系统,设计人员采用一个带有独立H.264 ASSP的Zynq SoC。利用Zynq UltraScale+ MPSoC的优势,设计人员现在能够在单个Zynq UltraScale+ MPSoC中实现4Kx2K UHD系统,而且在相同功耗预算条件下,该系统相比双芯片系统而言,性能功耗比提高了5倍。
赛灵思公司高级SoC产品线经理Sumit Shah表示:“在需求使用Zynq SoC和两个ASSP的公共安全无线电应用中,现在您只需使用一个Zynq UltraScale+ MPSoC就可实现整个设计,而且相对此前的配置,系统功耗降低了47%,性能提升了2.5倍,从而实现了4.8倍的性能功耗比优势。”
Shah说,同样的,此前实现在两个28nm Zynq SoC上的汽车多摄像头驾驶员辅助系统,现在可以缩小到一个Zynq UltraScale+ MPSoC上。单芯片系统比双芯片设计的性能提升2.5倍,功耗降低50%。相对此前实现方案而言,这可将性能功耗比净提升5倍。
针对所有UltraScale Plus产品系列的早期客户参与计划正在如火如荼进行。首个流片和设计工具的早期试用版本预计将于2015年第二季度推出。公司有望在2015年第四季度开始向客户出货UltraScale+器件。












评论