
运用SAD算法降低FPGA资源利用率
基于FPGA的设计,需要仔细检查设计所占用的面积以及实施后的时序性能,以确保设计适合目标器件,并满足其时序或吞吐力要求。在基于FPGA的商用设计中,设计师通常会将查找表(LUT)的资源占用率上限设置为80%左右,以便为未来升级和功能改进留有资源,并可让时序收敛更容易。余下约20%的空闲LUT留下了空余的布线资源,有助于满足严格的时序约束。
本文引用地址:http://www.amcfsurvey.com/article/191037.htm 在设计中,FPGA结构里嵌入的逻辑越多,占用的布线资源就会越多。综合工具或许能将更多逻辑成功地映射到LUT和其它资源,但很可能无法在二者之间布线。因为现有的逻辑已经显著提高了互连使用率,已经没有端到端路径来路由更多连接的信号。即使可能存在布线空间,布线器也无法对其建立端到端连接。因此,虽然有可用的LUT资源,但设计受到了“互连限制”,所以有可能无法进行扩展。
减少设计面积还具有经济意义。在符合应用要求的情况下,FPGA器件越小,设计和生产成本则越低。当然,如果有以太网模块、嵌入式处理器或收发器等特殊需求,就需要选择能通过硬IP或软IP支持这些模块的FPGA。不过在设计中,减少其它部件的使用面积,仍有助于从支持这类特殊模块的FPGA系列中进行选择。
资源共享
资源共享是一种在保持功能性的同时减少面积或资源占用率的传统方法。其中包括通过将一个以上的运算映射到一个运算器,实现算术运算器(如加法器、乘法器等)的共享。例如,共享后3个加法器可执行6个而不是3个加运算,使用的加法器数量减少了一半,从而减少了资源占用率。通过Xilinx ISE软件,可以在合成属性对话框中开启相应开关(resource sharing)后进行资源共享。当在一个if-else程序块(图1)或case-endcase程序块(图2)中描述互斥的任务后,这些工具能检测并实施资源共享。

图1:if-else程序块

图2:case-endcase程序块
如图所示,这些任务都是互斥的。因此,启用资源共享后,8个加运算可以共享两个加号。这类资源共享依赖于鉴别寄存器传输级(RTL)设计中可能存在的互斥任务。然而,如果不存在互斥任务,资源应该如何共享?这样做又有何利弊?为了回答这个问题,下面将从更高层次的抽象概念对资源共享进行深入研究。
比RTL更胜一筹
“更高层次的抽象概念”是指比RTL更高级别的设计描述,可在RTL准备好前对要实施的应用进行分析。如果可以通过分析应用来了解其内在并行性,则在RTL设计中也可以这样做。此外,对应用的数据流程图进行分析有助于设计资源共享的实施。
数据流程图能提供关于应用数据流的信息。数据从一个运算流向另一个运算,因此在运算之间可能存在着数据依赖关系。不相互依赖的运算可以并行执行。不过并行执行几乎总是造成很高的资源占用率,而目标是降低资源占用率,所以暂不讨论并行执行这种模式。
SAD是MPEG-4解码器动作估计部分中的一种重要算法,也能用于物体识别。在这种以像素为基础的方法中,图像区块中每个像素的值都与另一幅图像中相应像素的值相减,以确定该图像的哪些部分从一帧移到了另一帧。如果图像区块大小为4x4,则最后会将全部16个绝对差值相加。在开源xvid解码器的sad.c文件末尾有代码示例。
图3显示了用这一算法处理一个4x4图像区块时的数据流图(DFG)。这些减法运算可以并行,因为其中的减法运算不依赖于其它任何减法运算。但由于目的在于降低资源占用率,所以并不采用并行执行模式。而是采用一种称为基于扩展兼容路径(ECPB)硬件绑定的资源分配和绑定算法。

图3:SAD算法的数据流图
资源的分配和绑定主要是指为DFG中的运算分配加号、乘号等资源,然后将这些资源绑定到运算,以便降低器件的资源占用率、提高最大时钟频率,或同时实现两者。原则是在最终设计符合功能限制的前提下缩小面积。此算法可以检测已调度的DFG(即其运算已在不同步骤或时钟周期中进行了调度)中各运算间流程的依存关系,并分析出运算内部(intra-operation)流程的依存关系。
此算法将可并行的运算调度在同一时间步骤中,并将需要依赖于其它运算数据的运算调度到不同的时间步骤中。它为已调度DFG中的每种运算都建立了一个加权的有序相容图(WOCG)。因此,减法运算有一个WOCG,加法运算则有另外一个WOCG。这种方法使用了加权关系Wij =1+α×Fij +β×Nij +y ×Rij来为WOCG中的各边(edges)分配权重。在这里,Wij即同类型的i和j运算之间的权重值。Fij是流程依存关系的权重值,而Nij是运算i和j之间的共模输入数量。如果运算i和j的输出结果可以存入同一个寄存器,则Rji的值为1,否则即为0。在本例中,将调整参数数α、β和γ的值分别设为1、1和2。
接下来的步骤是用最长路径算法找出WOCG中使用的最长路径。该最长路径中的全部运算都被映射到同一运算器。将绑定运算从WOCG中移除后,重复最长路径和映射流程,直到处理完所有WOCG。由于这种算法会将多个运算映射到同一资源或运算器,所以运算器的容量相当大,足以满足最大规模的运算。在实施SAD方法的例子中,8位数据(灰度图像)处理了全部减法运算,因此,减法运算器的输入宽度是8位。我们将负责迭代计算SAD和的累加运算器位宽设定为23位和8位。
图4显示了实施的SAD算法的数据路径。在这个设计中只使用了一个减法器和一个加法器/累加器。各个运算之间有着非常多的资源共享。如果直接在RTL行为层描述设计,这种资源共享将不可能实现,因为SAD算法中不存在互斥的任务。生成这个数据路径后,可用加法器、减法器和乘法器模块分层实施设计。这一包含模块实例化的实施方法比行为化的方法结构更为明晰,并且与后者的数据路径非常相似。
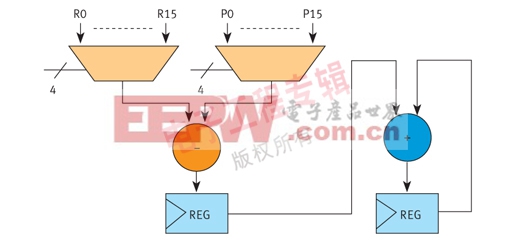
图4:采用SAD算法的数据路径
在以数据为主导的大型应用中,在更高层次进行此类预处理有助于降低资源占用率。此外,这种方法也很容易实现自动化。
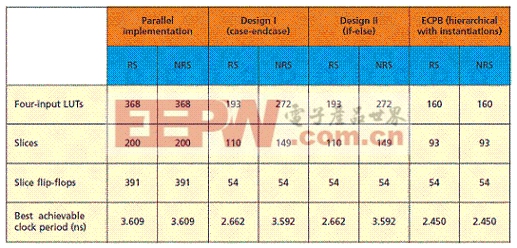
为了比较ECPB算法生成的数据路径获得的物理综合结果,我们还进行了一次完全并行的实施,两次与图4中的数据路径相同的实施。后两次是无层次的行为设计,最终RTL描述没有分层,包含引起复用的“强制”互斥任务。“强制”是指实施与图4中相同的数据路径,但采用了包含互斥任务的行为描述。其中一种设计具有if-else结构,另一种具有case-endcase结构。表1展示了使用Xilinx ISE 12.2(M.63C)软件默认设置、以Virtex-4XC4VFX140-11FF1517为目标器件,且没有时间限制的情况下获得的后时序(post-place-and-route)结果。内部寄存器也进行了相应的初始化,所有实施过程中都没有重置。
在这个表格中,RS和NRS分别表示在Xilinx ISE已启用或禁用资源共享的情况。设计方案I和II是因为不同的综合工具可以从不同格式的HDL代码(if-else、case-end-case)中推论出不同的复用类型。时钟周期没有考虑抖动的情况,所以应该根据时钟源规范降低一定数量。同时,任何方案都未使用预处理寄存器进行输入。
资源节省
如表所示, LUT消耗显著降低,最高可达56%,最少也有20%。不过,资源共享与完全并行的实施方法不同,后者的数据样本大体上在每个时钟周期都可用,而资源共享使用数据样本处理的过程会有一些限制。由于资源被共享,只有在前一份数据样本部分或完全处理后,才能处理新的数据样本。在ECPB实施中,新的P和R系列值至少要在16个时钟周期后才能使用。
虽然这一技术不是任何地方都适用,但它非常适合运用在类似采样率(sample rate)的应用中。例如,ECPB设计能够轻松地在1.016毫秒内处理一个尺寸为720x576的DV-PAL帧,而不会对25帧/秒的PAL帧速率产生任何影响。
表1:结果对比(RS和NRS分别表示已启用或禁用资源共享的情况)











评论