
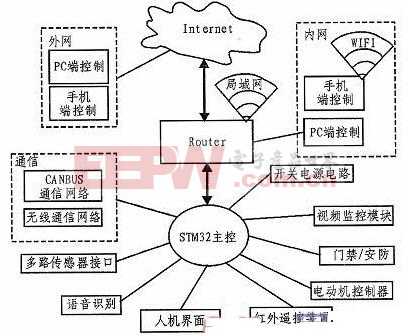
基于片上系统SoC的孤立词语音识别算法设计
1. 引言
本文引用地址:http://www.amcfsurvey.com/article/190560.htm目前,嵌入式语音识别系统的实现主要通过单片机MCU和数字信号处理器DSP来实现[1]。但是单片机运算速度慢,处理能力不高;虽然DSP处理速度很快,但是产品的成本很高,电源能量消耗也很大。因此,为了满足嵌入式交互系统的体积越来越小、功能越来越强的苛刻需求,语音识别片上系统SoC(System on Chip)应运而生。
语音识别片上系统SoC本身就是一块芯片,在单一芯片上集成了模拟语音模数转换器ADC、数模转换器DAC、信号采集和转换、处理器、存储器和I/O接口等,只要加上极少的电源就可以具有语音识别的功能,集成了声音信息的采集、取样、处理、分析和记忆。SoC具有片内处理器和片内总线,有着更灵活的应用方式。它具有速度快,体积小,成本低,可扩展性强等优点,有着广泛的应用前景,已经成为语音识别技术应用发展的一个重要方向[2-3]。研究和开发应用于片上系统SoC芯片的语音识别算法有着非常重要的意义。
2. 孤立词语音识别系统
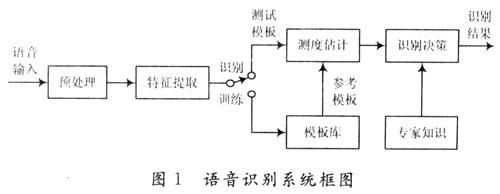
孤立词语音识别系统应用于嵌入式控制领域,例如数字家庭控制、车载语音控制和智能语音可控玩具等。在训练阶段,用户将每一个词依次说一遍,并将计算得到的每一个词所对应的特征矢量序列作为模板存入模板库中。在识别阶段,将输入语音的特征矢量序列依次与模板库中的每一模板进行相似度比较,将相似度最高者作为识别结果输出。
3. 针对片上系统SOC的孤立词语音识别算法设计
在SoC芯片中实现孤立词语音识别系统,就要根据语音识别片上系统的特点,来进行SoC的语音识别算法的选择和设计。
首先是特征提取算法的选择。MFCC算法考虑到了人的听觉效果,能很好的表征语音信号,而且在噪声环境下能取得很好的识别效果。而LPC系数主要是模拟人的发声模型,对元音有较好的的描述能力,对辅音描述能力较差,抗噪声性能也相对差一些。但是从算法的计算量来考虑,MFCC提取特征参数是LPCC 的10倍左右,通常在嵌入式系统下较难实现实时性。因此,选用LPCC算法。
模式匹配技术的选择。隐马尔柯夫模型HMM方法是用概率及统计学理论来对语音信号进行分析与处理的,适用于大词汇量、非特定人的语音识别系统。该算法对系统资源的要求较多。而动态时间规整技术DTW采用模板匹配法进行相似度计算,是一个最为小巧的语音识别算法,系统开销小,识别速度快,可有效节约系统资源,降低系统成本开支。由于嵌入式系统资源有限,语音命令识别系统所需要的词汇量有限,所需识别的语音都是简短的命令,模式匹配算法选择DTW。
3.1 端点检测算法设计
一个好的端点检测算法可以在一定程度上提高系统的识别率。在双门限端点检测原理的基础上,进行语音端点检测算法的设计。为了提高端点检测的精度,采用短时能量E和短时过零率ZCR。
语音采样频率为8KHz,量化精度为16位,数字PCM码首先经过预加重滤波器H(z)=2-0.95z-1,再进行分帧和加窗处理,每帧30ms,240点为一帧,帧移为80,窗函数采用Hamming窗。然后对每帧语音进行归一化处理,即把每点的值都除以所有语音帧中数值绝对值的最大值,把值的范围从[-32767,32767]转换到[-1,1]。
在实验中发现,双门限端点检测算法对于两个汉字和三个汉字的语音命令端点检测效果不好。以语音“开灯”为例,如图1所示语音波形图中,端点检测只能检测到第一个字。
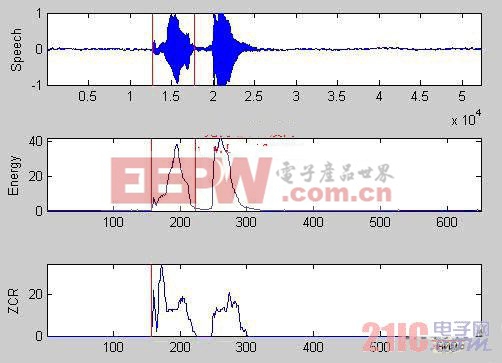
图1 改进前对语音“开灯”的端点检测
Fig2. the endpointing detection of speech “kaideng” before ameliorate
如果语音命令中两个字的间隔过长,使用双门限端点检测方法会发生只检测到第一个字的情况,在实际中“开灯”和“开门”等命令只提取了“开”字的语音,从而可能造成语音匹配的错误。
为避免该错误,采用的办法是,把可容忍的静音区间扩大到15帧 (约150ms)。在双门限的后一门限往后推迟15帧,如15帧内一直没有energy和ZCR超过最低门限,则认为语音结束;如发现仍然有语音,则继续算入在内。
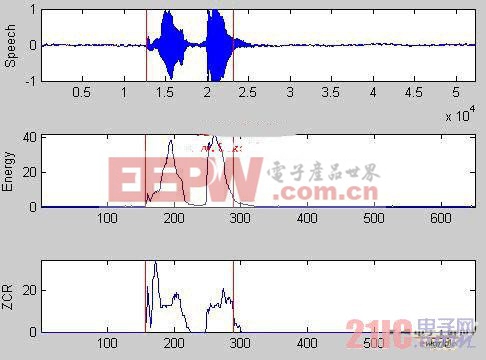
图2 改进后对语音“开灯”的端点检测
Fig3. the endpointing detection of speech “kaideng” after ameliorate
改进后,整个语音信号的端点检测流程设计为四个阶段:静音、过渡段、语音段和语音结束。在静音段,如果能量或过零率超越了低门限,就应该开始标记起始点,进入过渡段。在过渡段中,由于参数的数值比较小,不能确信是否处于真正的语音段,因此只要两个参数的数值都回落到低门限以下,就将当前状态恢复到静音状态。而如果在过渡段中两个参数中的任一个超过了高门限,就可以确信进入语音段。在语音段,如果两个参数的数值降低到低门限以下,并且一直持续15帧,那么语音进入停止。如果两个参数的数值降低到低门限以下,但是并没有持续到 15帧,后续又有语音段越过低门限,那么认为语音还没有结束。最后,如果检测出的这段语音总长度小于可接受的最小的语音帧数(设为15帧),则认为是一段噪音而放弃。
采用改进后的端点检测算法,对于单个汉字或多个汉字的语音命令均识别常。图2为语音“开灯”的端点检测图(两条红线以内的部分为检测出来的语音部分)。







评论