
基于Altera浮点IP核实现浮点矩阵相乘运算的改进设
嵌入式计算作为新一代计算系统的高效运行方式,应用于多个高性能领域,如阵列信号处理、核武器模拟、计算流体动力学等。在这些科学计算中,需要大量的浮点矩阵运算。而目前已实现的浮点矩阵运算是直接使用VHDL语言编写的浮点矩阵相乘处理单元[1],其关键技术是乘累加单元的设计,这样设计的硬件,其性能依赖于设计者的编程水平。此外,FPGA厂商也推出了一定规模的浮点矩阵运算IP核[2],虽然此IP核应用了本厂家的器件,并经过专业调试和硬件实测,性能稳定且优于手写代码,但仍可对其进行改进,以进一步提高运算速度。
本文引用地址:http://www.amcfsurvey.com/article/189645.htmAltera公司推出的浮点矩阵相乘IP核ALTFP_MATRIX_MULT,是在Quartus软件9.1版本以上的环境中使用,能够进行一定规模的浮点矩阵相乘运算,包含A、B矩阵数据输入,数据浮点乘加,数据缓存及相加输出四大部分。其中最能体现浮点计算性能的是浮点乘加部分,而周围的控制电路及输出则影响到系统的最高时钟频率,间接地影响系统整体性能。
整个矩阵相乘电路原理是将输入的单路数据(A、B矩阵共用数据线),通过控制器产生A、B矩阵地址信号,控制着A矩阵数据输出和B矩阵数据输出,并将数据并行分段输出到浮点乘加模块进行乘加运算,之后串行输出到一个缓存器模块中,再以并行方式输出到浮点相加模块,最后获得计算结果。从其原理可以看出,在数据输入输出方面仍有许多可改进的地方。
2 IP核存在的缺陷及改进
2.1 存在缺陷
(1)输入数据带宽的不均衡性。在矩阵A、B的数据输入时,Altera的IP核将A矩阵数据存于M144K的Block RAM中,而将B矩阵数据存于M9K的Block RAM中,导致IP核中A矩阵数据的带宽小于B矩阵数据的带宽,并需要一定数量的寄存器组使A矩阵数据带宽能够匹配于B矩阵数据带宽。由此可见,A、B矩阵数据的存储受到器件限制和存储约束,同时由于在浮点乘加模块的输入端(A、B矩阵数据)带宽不同,造成A矩阵数据的输入需要额外的处理时间。
(2)加载数据的不连贯性。在矩阵数据加载时,IP核通过将数据分段成等分的几部分,用于向量相乘。由于矩阵A存储带宽窄需要4步寄存(由Blocks决定),在第3个周期时才加载数据B用于计算,送到一个FIFO中存储;在第6个时钟周期时加载矩阵A分段的第二部分进行各自的第二部分计算,最后当计算到第15个周期时,才可通过浮点相加,计算出矩阵C的第一个值,之后计算出矩阵C的其他值C11。从上述结构可见,在分段相乘之后,采用先对一个FIFO进行存储,存满后再对下一个数据FIFO进行存储,造成时间上浪费过多。
2.2 设计改进
鉴于上述缺陷,在输入A、B矩阵的存储方式上,进行串行输入到并行输入的改进,使得两个矩阵能同步输入到浮点乘加模块。在数据加载方式上,将A矩阵用3个周期加载完毕,再处理相乘运算;将分段相乘结果进行直接存储相加,获得C矩阵的第一个值,缩减运算时间。设计的改进框图如图1所示。
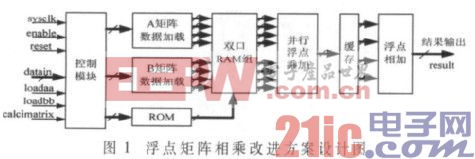
将A、B矩阵数据加载模块设计成同步加载的方式,即在loadaa为高电平时,对A的第一组数据进行初始化,加载到双口RAM模块存储;在loadbb为高电平时,加载B矩阵的数据,也进行双口RAM存储。然后依据ROM存储的地址信号表,在控制模块的控制下输出A、B矩阵地址相对应的数据,进行浮点乘加运算,之后串行缓存,并行输出到浮点相加模块,进行输出。计算时序如图2所示。

在时序上要求初始化加载A矩阵的第一行数据A1、A2、A3之后,加载B矩阵的第一列数据,当分段E1加载后立即进行分段第一组数据相乘A1×E1。以此类推,当加载A的第二行数据时,即可立即与B矩阵的第一列数据相乘。总体而言,只需要在ROM模块中存储一定的地址信号,即可使浮点乘加模块的输入端具有并行连贯的数据输入,缩短了运算时间。
3 浮点矩阵相乘实现
3.1 模块总体实现
按照上述改进方案,ROM地址表在控制模块的控制下产生一组地址信号控制双口RAM组进行并行输出,保证了浮点乘加模块计算的准确性。其中控制模块为设计的关键部分,用于产生所有模块的控制信号,实现同步计算。分为a_cntrl、b_cntrl、cache、outcntrl四部分控制信号以及一路计数信号用于ROM地址查询,内部由一个状态机和逻辑单元组成,状态机用于产生矩阵A、B的read开始、latch锁存、地址叠加信号的转换。控制模块的时序仿真如图3所示。
图3在全局同步信号时钟sysclk、复位reset、使能enable的作用下,当calcmatrix信号为‘1’时,开始计算并生成输出控制信号。其中a_cntrl部分用于控制矩阵A数据加载模块,主要包含地址信号readaa和锁存信号latchaa,来一个锁存高电平则存储A矩阵数据readaa;b_cntrl部分则对应于矩阵B的控制,输入B矩阵数据readbb;cache部分用于控制数据缓存部分串行输入并行输出,包含着相应的读地址信号cacherdadd、写地址信号cachewradd、cache选择信号cachemesel,三者同步控制并行输出;outcntrl部分是整个系统的输出控制部分,在准备信号ready之后,出现outvalid高电平,表示输出数据有效,同时完成信号done为低电平。为使矩阵A、B数据能同时加载到浮点乘加模块上,需要使一个readaa值对应于readbb的columnsbb个数据。在本设计中使用的是A9×16数据与B16×8数据进行计算,生成的outvalid有9个脉冲,每个脉冲包含8个矩阵输出数据。
对于A、B矩阵的数据加载,采用的是串行输入并行输出的控制器,由移位寄存器组成,当计数器计数到端口输出值时(如端口并行输出8个数则计数到8),并行输出数据。
浮点乘加模块采用并行相乘、并行相加的方式。由于考虑到精度问题,采用浮点位数转换,将32 bit的输入数据进行浮点扩展为42 bit,再进行乘加运算,最后再将42 bit数据转换为32 bit数据。采用三级流水线的方式,进行并行乘加运算,提高设计系统性能。
在双口RAM组的实现上,是将一组simple dualport ram[3]并列成一个RAM组。输入由矩阵A、B的数据信号和ROM输出的地址信号组成;输出就是一路矩阵A数据和一路矩阵B数据,数据深度与vectorsize等同。其中每一个RAM的深度为rowsaa×columnsbb/vectorsize,保证数据的可重用性,同时相对应的ROM中存储的地址信号分别为:
A:1 2 1 2 3 3 1 2 3 4 4 4 1 2 3 4 5 5 5 5 1 2 3 4 5 6 6 6 6 6 ……
B:1 1 2 2 1 2 3 3 3 1 2 3 4 4 4 4 1 2 3 4 5 5 5 5 5 1 2 3 4 5 ……
以此类推即可得到相应的地址信号查找表。
在数据缓存模块的设计上也采用串行输入并行输出的方式。使用移位寄存器的方式实现,在并行浮点相加部分类似于上述的并行乘加[4]计算,采用多级流水线并行相加的方式完成。
尘埃粒子计数器相关文章:尘埃粒子计数器原理







评论