
说话人语音特征子空间分离及识别应用
随着电话银行等网络电子消费的普及,说话人识别作为一种有效的身份认证手段,其技术特点和优越性越来越明显,在国防安全、司法和金融等各应用领域的价值越来越显得重要。目前说话人识别的主要方法一般通过在语音特征观察空间建立说话人模型进行,如基于VQ的码本模型识别方法、基于GMM模型的识别方法以及其他一些方法,这些方法大都利用了说话人语音特征的统计特性。但是,说话人识别应用中存在的两个主要问题是:(1)由于语音特征的时变性,模型训练时期和实际识别时期语音特征发生变化而导致识别性能的下降,而目前这些方法只能在一定程度上处理这种变化;(2)实际应用中往往需要能通过较短的语音及时识别说话人身份,但目前这些方法一般需要输入3秒以上的语音才能得到较高的识别率。
语音信号中包含语义和说话人个性这两大特征,如果能够较好地将这两类特征进行分离,并依据个性特征建立说话人模型,则说话人识别性能将会得到提高并大大增强识别系统的鲁棒性,但两类特征的完全分离非常困难。统计方法建立的模型不可避免地需要较大的数据量进行训练和识别,在短时测试语音下识别性能下降是必然的。如果能够建立一种非纯粹统计模型或在统计模型的基础上结合结构性模型则可能会提高短时测试语音条件下的识别性能。
本文依据主元分析(PCA:Principal Component Analysis)原理和说话人语音特征在观察空间的分布散度提取主要散度向量构造说话人语音特征子空间,将说话人语音特征子空间从观察空间分离出来。实验分析了基于特征子空间的说话人识别性能,结果证明了这种方法的有效性,特别是在小于3秒的短时测试语音情况下识别性能明显优于VQ和GMM等方法。
2 特征子空间分离
基于语音特征子空间分离的说话人识别系统中,说话人模型由特征子空间表示,模式匹配部分则通过计算输入测试语音特征矢量与子空间的距离进行。特征子空间根据说话人训练语音提取的特征矢量在观察空间的统计分布特性,依据PCA原理选取具有较大权值的散度向量构成。
设一个说话人训练语音集合为{S1,S2,…,SN},每一个训练语音样本经过特征提取后形成特征矢量序列,即![]() 如果特征矢量具有P个参数,则特征矢量Vij表示P维观察空间的一个点,所有的特征矢量
如果特征矢量具有P个参数,则特征矢量Vij表示P维观察空间的一个点,所有的特征矢量![]() 在观察空间形成具有一定统计分布特性的点集{V1,V2,…,VM},其中M是说话人所有训练语音特征矢量的总数。描述说话人语音特征矢量在观察空间分布的一个主要统计指标是分布散度,它可以由平均特征矢量和自协方差矩阵表示,如下:
在观察空间形成具有一定统计分布特性的点集{V1,V2,…,VM},其中M是说话人所有训练语音特征矢量的总数。描述说话人语音特征矢量在观察空间分布的一个主要统计指标是分布散度,它可以由平均特征矢量和自协方差矩阵表示,如下:
![]()
公式(1)中平均特征矢量V反映说话人所有特征矢量在观察空问的中心点。公式(2)中自协方差矩阵R是一个P×P正定对称矩阵,它反映了说话人特征矢量各参数的平均偏离值,因此可以衡量特征矢量在观察空间的分布散度。
求自协方差矩阵R的本征值{λ1,λ2,…,λP}和相应的本征向量{e1,e2,…,eP},则它们之间的关系如下式(3)~(5)所示。其中φ是由本征向量作为每一列构成的P×P矩阵,A是由本征值构成的对角矩阵。

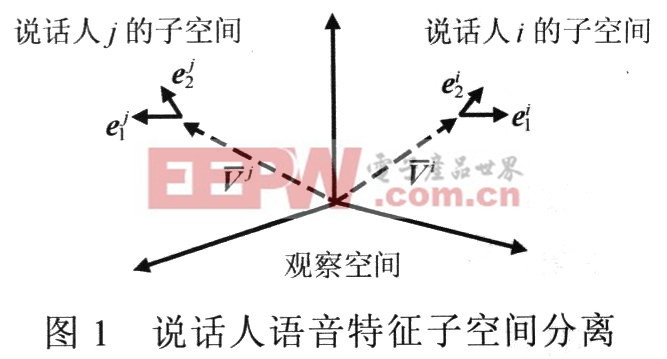
因为本征向量ei,i=1~P是从描述说话人语音特征矢量分布散度的自协方差矩阵计算得到,所以,从空间的角度看,说话人的语音特征分布完全可以由以平均特征矢量V为中心,本征向量ei,i=l~P为正交归一化基底的子空间描述,如图1所示。这样,就从语音特征观察空问将说话人语音特征子空间分离了出来,不同的说话人具有不同的特征子空间。
虽然计算得到的本征向量个数与观察空间维数相同,但有些本征向量对应的本征值较小,在表示语音特征分布散度时影响较小。因此,实际应用中可以选择具有较大散度权值(本征值)的向量构成子空间的基向量。图1显示了一个三维观察空间中分离出的两个二维说话人特征子空问例子,这些子空间的基底对应前两个较大的散度权值。第4小节分析了选取不同散度权值本征向量构成子空间情况下的识别性能,结果表明子空间维数并非越多越好。
说话人语音特征子空间本质上是根据训练语音特征矢量在观察空间的统计分布特性分析得到的一种结构性说话人模型,各子空间的基底描述了说话人语音特征分布的框架结构。因此,可以认为子空间融合了说话人语音特征的统计特性和结构特性,可由下式(6)表示:
![]()
3 子空间距离测度与模式匹配
系统模式匹配对输入测试语音与各说话人子空间的相关度进行分析,提供说话人身份的判别依据。设输入测试语音St相应的特征矢量序列为![]() 则通过计算该特征矢量序列与说话人特征子空间的距离来分析测试语音与子空间的相关度,距离越小,相关度越大。最终的说话人识别判决可以依据最小距离准则进行,即测试语音说话人所对应的子空间应该与测试语音之间的距离最小,即相关度最大。
则通过计算该特征矢量序列与说话人特征子空间的距离来分析测试语音与子空间的相关度,距离越小,相关度越大。最终的说话人识别判决可以依据最小距离准则进行,即测试语音说话人所对应的子空间应该与测试语音之间的距离最小,即相关度最大。
输入语音特征矢量Vt与子空间的距离测度采用子空问投影距离计算,如下式(7)所示。其中Q是子空间的维数,Q≤P。
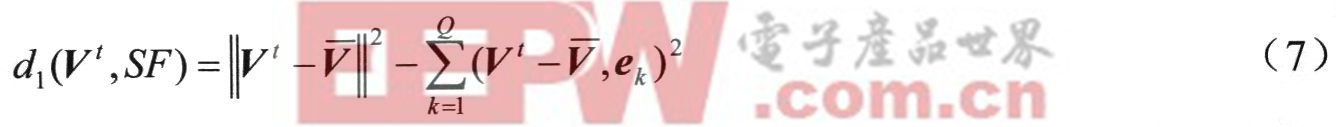
上式第一项是观察空间特征矢量Vt与说话人语音特征子空间中心矢量V之差向量Vt一V的平方模;第二项是这个差向量Vt一V在子空间各维投影的平方和,代表了这个差向量在子空间上的投影长度的平方。两项相减就是输入测试语音特征矢量Vt与子空间的距离。
以上距离测度中采用了训练语音的平均特征矢量V,使观察空间特征矢量转换为适合子空间处理的差向量形式。实际应用中,说话人语音特征是时变的,并引起特征矢量统计分布特性的变化,其表现之一是平均特征矢量随时问的漂移。从子空间角度看,这个平均特征矢量的变化代表了说话人语音特征子空间的一种整体时变漂移,在计算子空间距离时如果不能及时反映这种变化,将可能引起一定程度的失真,为此,定义第二种距离测度如下:
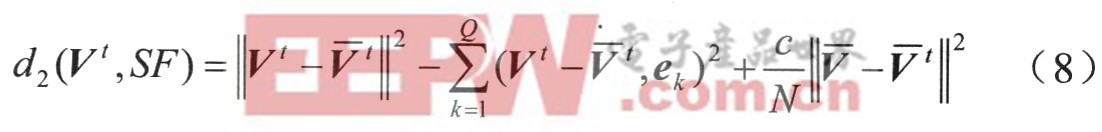
前面两项的含义与第一种测度d1(Vt,SF)是一致的,但差向量不是根据训练语音的平均特征矢量V形成,而是由输入测试语音的平均特征矢量Vt形成。这样,不仅使观察空间特征矢量转换为适合子空间处理的差向量形式,并且使形成差向量的两个特征矢量在时间上一致起来。但是,子空间是根据训练语音构造的,其中心特征矢量是训练语音的平均特征矢量,距离测度中必须反映这一差异。所以,在第二种距离测度中增加第三项描述训练语音和测试语音特征矢量的平均差异,两者通过加权系数c结合,其中N是测试语音短时帧个数。因此,这一距离测度不仅描述了特征矢量与说话人特征子空间的距离,而且描述了测试语音特征与子空间所表示的说话人语音特征的平均距离,同时考虑了语音特征的结构性和统计特性差异。加权系数c的选择使两类距离对整个测度的影响保持平衡,可以通过各自的统计方差之比计算。
模式匹配通过计算整个输入测试语音特征矢量序列与子空间的距离进行。利用以上距离测度,输入测试语音St与说话人语音特征子空问的总距离如下:
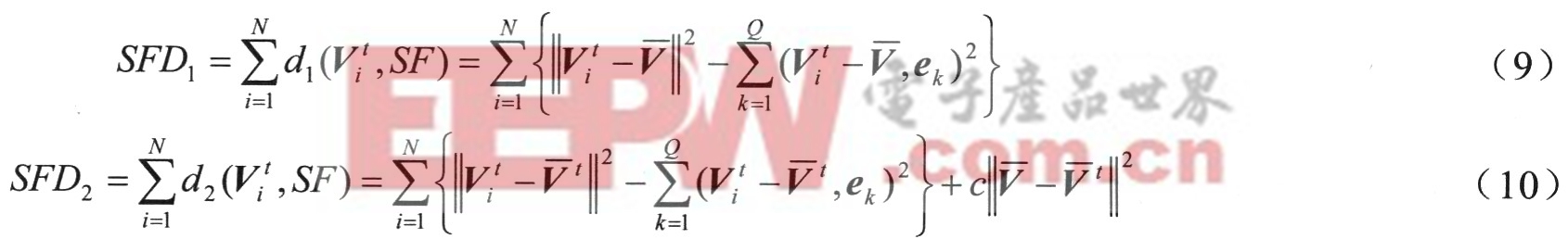







评论