
H.264解码器中CAVLC码表查找算法的分析与优化
近年来,随着信息技术飞速发展和互联网的日益普及,尤其是以视频为信息主要来源的多媒体领域越来越受到人们的关注。H.264是ITU-T的视频编码专家组(VCEG)和ISO/IEC的活动图像编码专家组(MPEG)的联合视频组(Joint Video Tearn,JVT)开发的一个新的数字视频编码标准,它既是ITU-T的H.264,又是ISO/IEC的MPEG-4的一部分。H.264和以前的标准一样,也是DPCM加变换编码的混合编码模式。H.264标准可分为三档:基本档次(其简单版本,应用面广);主要档次(采用了多项提高图像质量和增加压缩比的技术措施,可用于SDTV、HDTV和DVD等);扩展档次(可用于各种网络的视频流传输)。
H.264/AVC的编解码框架的基本结构与早期的编码标准(H.263、MPEG4等)相似,都是由运动估计、变换、量化、熵编码、环路去块效应滤波器等功能单元组成的。H.264视频编码框架的主要变化包括:引入了环内去块效应滤波器,去块效应处理后的宏块被保存在内存中用于对后续宏块的预侧;采用了多参考帧运动估计,需要在内存中保留多个参考视频帧;引入了帧内预测机制,可以通过同一帧内的宏块进行预测;采用了新的整型变换方式,取代了以前的离散余弦变换(DCT);H.264与以前视频标准在运动估计的模式上也有了较大的变化,H.264支持7种模式的可变块运动估计。此外,在熵编码中还引入了上下文自适应的变长编码(CAVLC)和二进制算术编码(CABAC)。
在熵编码方面,H.264使用了CABAC和CAVLC两种不同的编码方式。CABAC熵编码是一种基于区间划分的算术编码方式。这种编码方式的效率很高,接近信息熵值,但算法相对复杂,编解码速度较慢。CAVLC是一种可变长编码,它根据已编码语法元素的情况动态调整编码中使用的码表,在编码过程中有些语法元素是组合编码的,当对这些元素进行查找时就会耗费很长的时间。因此对CAVLC的优化显得格外重要。
1 原码表查找算法
原码表的存储结构为二维表结构。存储的内容为码字,二维坐标分别代表解码后的两个语法元素。对于二维表结构。若通过坐标查找内容是很容易的;而通过内容查找坐标,就需要对整个表进行遍历。JM中的码表查找算法就是通过遍历整个码表实现的,步骤如下:
(1)取码表的中的一个码字;
(2)根据码字长度从码流中取出相应长度的bit;
(3)比较此码字和bit串,若相同则查找成功,否则若码表中还有码字,回步骤(1),否则查找失败。
2 算法的优化分析
2.1 基于前缀零分组子表搜索算法
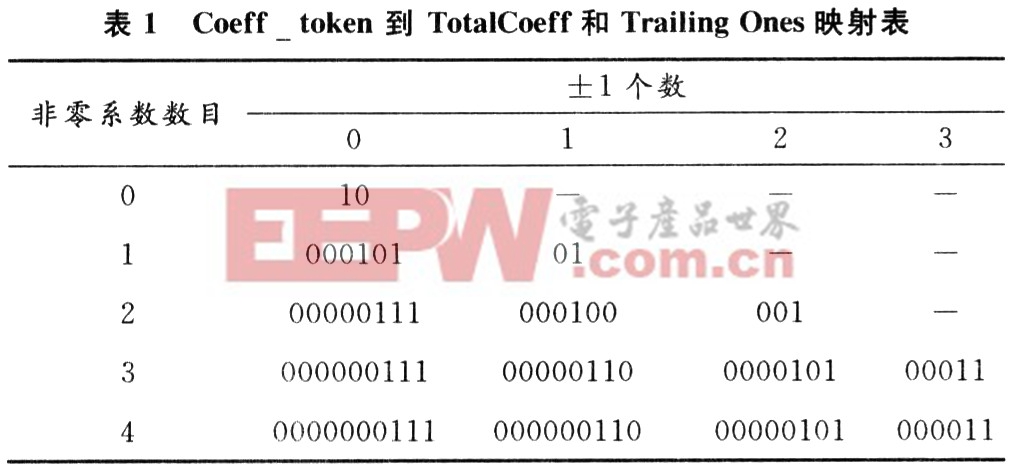
基于上下文自适应的变长编码的解码算法需要不断的读取码流,判断,直到在码表中找到该码字,如此反复,直至解码整个块。由此可见该过程的时间空间复杂度都是相当高的。由于变长码为霍夫曼前缀码,所以可以根据码表的特性,按照码字长度将原来的一个码表,按照码字长度对原码表进行分割,以Coeff_token码表为例,原码表如表1所示,表中NC=-1。
在参考模型中,搜索码表算法过程如下:
(1)从最短码长开始,读出该长度二进制数据流对应的码字;
(2)遍历码表,如找到该码字进行步骤(4),否则进入(3);
(3)码字长度加1,重定位指针位置,重复步骤(2);
(4)读取该码字对应值,更新指针位置。
从上面过程中不难发现,码字长度的不确定性使得在读取字节流时只能一次次的试探,导致了效率的下降。如果可以将变长码的读取采取固定的策略,一次读取固定的长度,之后再做判断,再读取一定长度,这样将判断的次数也固定,从理论上可以降低不断搜索和重定位指针带来的时间和空间复杂性。利用可以利用码表中码字前缀零数目的不同,将表1拆分为两个子表,如表2,表3所示NC为-1。

改进后的码表搜索算法如下:
(1)读取最大码字长度的二进制流;
(2)根据不同的前缀零位数、右移位、判零以确定码字所在子表;
(3)直接根据码值读取对应值,更新指针位置。
新的搜索过程不但避免了不确定性,而且无需遍历码表,这样可以在一定程度上提高变长解码的效率。
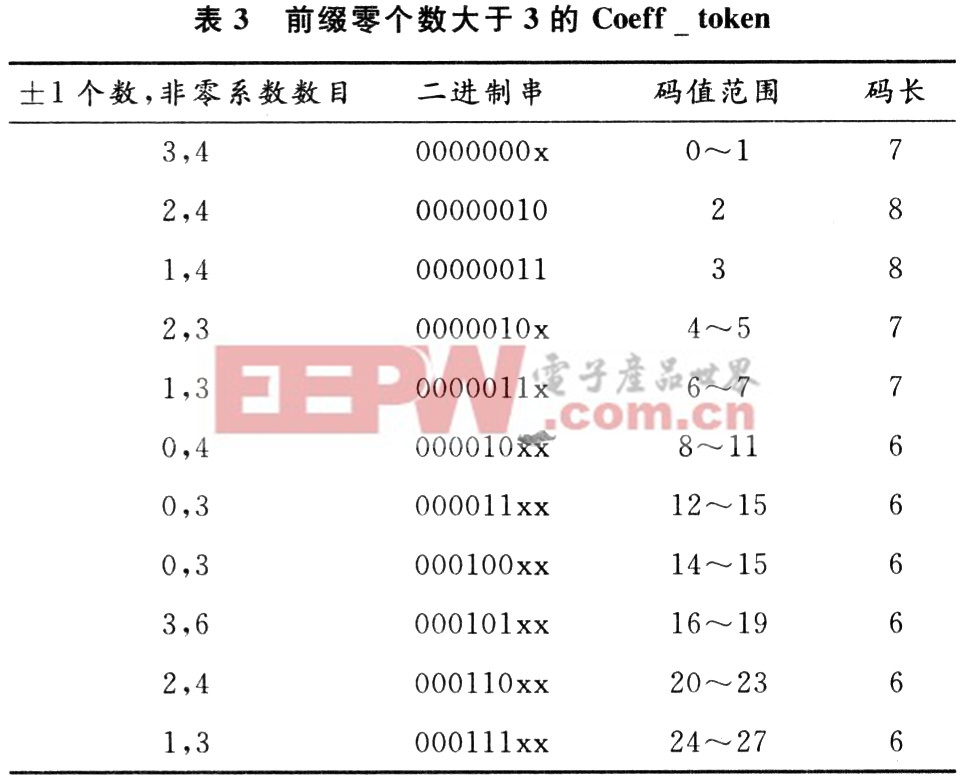
按照改进的算法步骤,解码时,首先从字节流中读取8位码字,由于前缀零个数分为大于3和小于3的两种情形,所以右移5位,若为零,则查找表2,否则查找表1,根据码值直接解码出±1个数,非零系数数目。此外在设计代码时,还可利用二叉搜索树的特性,设计搜索过程,提高解码效率。





评论