
使用赛灵思Vivado设计套件的九大理由
您的开发团队是否需要在极短的时间内打造出既复杂又富有竞争力的新一代系统?赛灵思All Programmable器件可助您一臂之力,它相对传统可编程逻辑和I/O,新增了软件可编程ARM®处理系统、可编程模拟混合信号(AMS)子系统和不断丰富的高复杂度的IP,支持开发团队突破原有的种种设计限制。赛灵思有多种All Programmable器件可供用户选择,构成这些器件的各种硅片组合使用赛灵思独特的高性能3D堆叠硅片互联技术彼此互联。这些领先一代的All Programmable器件为用户提供的功能,远超常规可编程逻辑所能及,为用户开启了一个全面可编程系统集成的新时代。
本文引用地址:http://www.amcfsurvey.com/article/185311.htmAll Programmable抽象化与自动化

All Programmable抽象化与自动化有何意义?
其意义在于采用赛灵思All Programmable器件,用户的开发团队可以用更少的部件实现更多系统功能,提升系统性能,降低系统功耗,减少材料清单(BOM)成本,同时满足严格的产品上市时间要求。但如果不借助强大的硬件、软件、系统设计工具和设计流程,则无法将这些优势交到您的设计团队的手中,您也不可能实现这些优势。赛灵思把所需的这些硬件、软件和系统设计开发流程统称为“All Programmable 抽象化 (All Programmable Abstraction)”。
在这种使用All Programmable抽象化进行先进的领先一代的硬件、软件和系统开发过程中,起着核心作用的是赛灵思Vivado®设计套件。Vivado设计套件是一种以IP和系统为中心的、领先一代的全新SoC增强型综合开发环境,可解决用户在系统级集成和实现过程中常见的生产力瓶颈问题。
就在同类竞争解决方案还在试图通过扩展过时且松散连接的分立工具来跟上片上集成的高速发展的时候,Vivado设计套件凭借业界最先进的SoC增强型设计方法和算法,提供了独特、高度集成的开发环境,为设计者带来了设计生产力的极大提升。Vivado设计套件将硬件、软件和系统工程师的生产力提升到了一个全新的水平。
以下九大理由,将让您了解到Vivado设计套件为何能够提供领先一代的设计生产力、简便易用性, 以及强大的系统级集成能力:
加快系统实现
理由一:突破器件密度极限:在单个器件中更快速集成更多功能。
如果设计工具能够让All Programmable器件集成更多功能,用户就能够在系统设计中选择尽可能小的器件,从而直接带来系统成本和功耗的下降。Vivado设计套件提供一种集成环境,能够让架构、软件和硬件开发人员在通用设计环境中协作工作,从而最大程度地提升设计效率,充分发挥All Programmable器件的可编程逻辑架构及其专用片上功能模块的潜力。
以OpenCores.org的以太网MAC(媒体访问控制器)模块设计为例。作为实验,赛灵思反复原样复制OpenCores以太网MAC,直至它们填充带有693,120个逻辑单元的Virtex®-7 690T FPGA。赛灵思又以类似的方法填充带有622,000个逻辑单元的同类竞争器件。下图显示的是实验结果。
按逻辑单元数量来衡量(一个“标准”的逻辑单元由一个4输入LUT(查找表)和一个触发器组成),赛灵思Virtex-7 690T器件的原始容量比同类竞争器件(带有622,000个逻辑单元)高出11%。但如图1所示,如果用Vivado设计套件将所有这些以太网MAC模块实例填充到赛灵思Virtex-7 690T器件中,赛灵思Virtex-7 690T器件要比同类竞争器件容纳的实例数多出36%。这个实验表明,Vivado设计套件与赛灵思7系列FPGA架构结合使用所产生的效率,要远高于同类竞争工具/器件组合所产生的效率。
(注:图1根据LUT和Slice计数结果,对赛灵思7系列All Programmable器件和同类竞争可编程逻辑器件进行比较。赛灵思7系列All Programmable器件slice含四个6输入LUT、八个触发器以及相关的多路复用器和算术进位逻辑,相当于1.6个逻辑单元。)
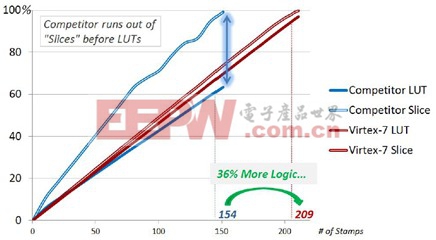
图1:复制次数与架构资源利用率的对比
Vivado设计套件如何最大化器件利用率
Vivado设计套件之所以能够实现更高的器件利用率,是因为它采用高级拟合算法,而且赛灵思7系列可编程逻辑架构在每个Slice内采用真正独立的LUT。值得注意的是,图1详尽地体现了赛灵思7系列的LUT和Slice拟合结果,两者均实现了近100%的利用率。而同类竞争的可编程逻辑器件在器件利用率仅达到63%就用尽了可用的Slice。产生这种低利用率的根源归咎于该竞争器件的可编程逻辑架构,这种架构在许多情况下不允许把两个LUT捆绑成一个物理集群。在完整的设计中,这显然会产生大量未充分利用的集群。这是由于为了满足架构的引脚共享要求,只有一个LUT得到使用,而另一个LUT则不能再用于设计中其余的逻辑。这项实验清楚地表明,用户可以使用更小的7系列All Programmable来实现更大的系统设计。
在这个IP模块拟合实验中,Vivado设计套件与同类可编程器件形成了鲜明的对:Vivado设计套件实现了99%的LUT利用率,而且即便在如此高利用率水平下,它还能在完成设计布局布线的同时,满足时序约束。Vivado布局布线算法旨在处理高密度、高难度设计,便于用户将更多逻辑置于该器件中,从而降低用户的系统材料清单(BOM)成本和系统功耗。
理由二:Vivado以可预测的结果提供稳健可靠的性能和低功耗
出于纳米级IC设计的物理原因,互联已经成为28nm及更高工艺节点的可编程逻辑器件架构的性能瓶颈。Vivado设计套件采用先进的布局布线算法,可突破该性能瓶颈,而且点击鼠标即可得到高性能结果。
Vivado设计套件的分析型布局布线算法能够同步优化包括时序、互联使用和走线长度在内的多重变量,提供可预测的设计收敛。同时,Vivado的实现引擎可保证在逻辑利用率高的大型器件上得到的结果和在器件利用率较低的设计上得到的结果一样优异。此外,在系统设计规模随着系统功能的增加而逐步增大的情况下,Vivado既能保持高性能结果,还能提高各次运行结果间的一致性。
如图2所示,与同类竞争工具相比,Vivado设计套件可随着利用率的提升提供更出色的性能,同时还能处理更大规模的设计。

c++相关文章:c++教程










评论