
语音识别及其定点DSP实现
语音识别研究的根本目的是研究出一种具有听觉功能的机器,能直接接受人的口呼命令,理解人的意图并做出相应的反映。语音识别系统的研究涉及微机技术、人工智能、数字信号处理、模式识别、声学、语言学和认知科学等许多学科领域,是一个多学科综合性研究领域。近年来,高性能数字信号处理芯片DSP(Digital Signal Process)技术的迅速发展,为语音识别的实时实现提供了可能,其中,AD公司的数字信号处理芯片以其良好的性价比和代码的可移植性被广泛地应用于各个领域。因此,我们采用AD公司的定点DSP处理芯片ADSP2181实现了语音信号的识别。
1 语音识别的基本过程
根据实际中的应用不同,语音识别系统可以分为:特定人与非特定人的识别、独立词与连续词的识别、小词汇量与大词汇量以及无限词汇量的识别。但无论那种语音识别系统,其基本原理和处理方法都大体类似。一个典型的语音识别系统的原理图如图1所示。
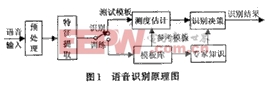
语音识别过程主要包括语音信号的预处理、特征提取、模式匹配几个部分。预处理包括预滤波、采样和量化、加窗、端点检测、预加重等过程。语音信号识别最重要的一环就是特征参数提取。提取的特征参数必须满足以下的要求:
(1)提取的特征参数能有效地代表语音特征,具有很好的区分性;
(2)各阶参数之间有良好的独立性;
(3)特征参数要计算方便,最好有高效的算法,以保证语音识别的实时实现。
在训练阶段,将特征参数进行一定的处理后,为每个词条建立一个模型,保存为模板库。在识别阶段,语音信号经过相同的通道得到语音特征参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。同时,还可以在很多先验知识的帮助下,提高识别的准确率。
2 系统的硬件结构
2.1 ADSP2181的特点
AD公司的DSP处理芯片ADSP2181是一种16b的定点DSP芯片,他内部存储空间大、运算功能强、接口能力强。有以下的主要特点:
(1)采用哈佛结构,外接16.67MHz晶振,指令周期为30ns,指令速度为33MI/s,所有指令单周期执行;
(2)片内集成了80 kB的存储器:16 kB字的(24b)的程序存储器和16kB字(16b)的数据存储器;
(3)内部有3个独立的计算单元:算术逻辑单元(ALU)、乘累加器(MAC)和桶形移位器(SHIFT),其中乘累加器支持多精度和自动无偏差舍人;
(4)一个16b的内部DMA端口(1DMA),供片内存储器的高速存取;一个8b自举DMA(BDMA)口,用于从自举程序存储器中装载数据和程序;
(5)6个外部中断,并且可以设置优先级或屏蔽等。
由于ADSP2181以上的特点,使得该芯片构成的系统体积小、性能高、成本和功耗低,能较好地实现语音识别算法。













评论