
改进遗传算法的支持向量机特征选择解决方案介绍
支持向量机是一种在统计学习理论的基础上发展而来的机器学习方法[1],通过学习类别之间分界面附近的精确信息,可以自动寻找那些对分类有较好区分能力的支持向量,由此构造出的分类器可以使类与类之间的间隔最大化,因而有较好的泛化性能和较高的分类准确率。由于支持向量机具有小样本、非线性、高维数、避免局部最小点以及过学习现象等优点,所以被广泛运用于故障诊断、图像识别、回归预测等领域。但是如果缺少了对样本进行有效地特征选择,支持向量机在分类时往往会出现训练时间过长以及较低的分类准确率,这恰恰是由于支持向量机无法利用混乱的样本分类信息而引起的,因此特征选择是分类问题中的一个重要环节。特征选择的任务是从原始的特征集合中去除对分类无用的冗余特征以及那些具有相似分类信息的重复特征,因而可以有效降低特征维数,缩短训练时间,提高分类准确率。
本文引用地址:http://www.amcfsurvey.com/article/155439.htm目前特征选择的方法主要有主成分分析法、最大熵原理、粗糙集理论等。然而由于这些方法主要依据繁复的数学理论,在计算过程中可能存在求导和函数连续性等客观限定条件,在必要时还需要设定用来指导寻优搜索方向的搜索规则。遗传算法作为一种鲁棒性极强的智能识别方法,直接对寻优对象进行操作,不存在特定数学条件的限定,具有极好的全局寻优能力和并行性;而由于遗传算法采用概率化的寻优方法,所以在自动搜索的过程中可以自主获取与寻优有关的线索,并在加以学习之后可以自适应地调整搜索方向,不需要确定搜索的规则。因此遗传算法被广泛应用在知识发现、组合优化、机器学习、信号处理、自适应控制和人工生命等领域。
基于改进遗传算法的特征选择
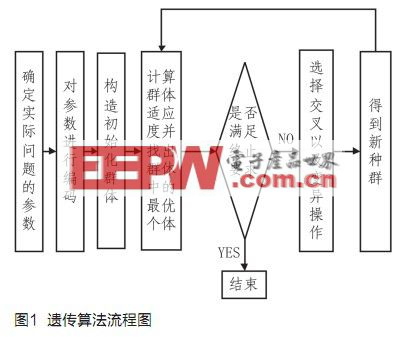
遗传算法是一种新近发展起来的搜索最优化算法[2~5]。遗传算法从任意一个的初始生物种群开始,通过随机的选择、交叉和变异操作,产生一群拥有更适应自然界的新个体的新一代种群,使得种群的进化趋势向着最优的方向发展。图1中所示的是标准的遗传算法的流程框图。
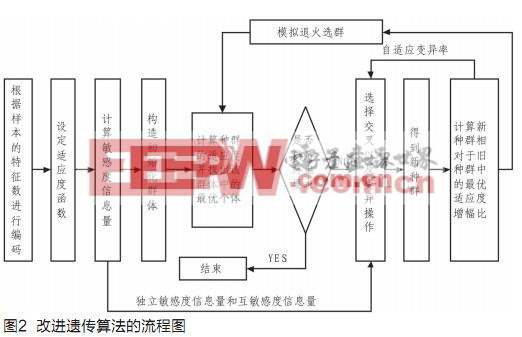
传统的遗传算法存在早熟收敛、非全局收敛以及后期收敛速度慢的缺点,为此本文提出了一种能够在进化过程中自适应调节变异率,以及利用模拟退火防止早熟的改进遗传算法,同时该算法利用敏感度信息可以有效地控制遗传操作。图2是改进遗传算法的流程框图。
染色体编码和适应度函数
所谓编码是指将问题的解空间转换成遗传算法所能处理的搜索空间。在特征选择问题中,常常使用二进制的编码形式,使得每个二进制就是一个染色体,其位数长度等于特征的个数。每一位代表一个特征,每位上的1表示选中该特征,0则表示不选中。每一代种群都由若干个染色体组成。
适应度函数是整个遗传算法中极为重要的部分[6],好的适应度函数能使染色体进化到最优个体,它决定了在整个寻优过程中是否能够合理地协调好过早收敛和过慢结束这对矛盾。由于本文针对的是支持向量机的特征选择问题,所以考虑以分类正确率和未选择的特征个数这两个参数作为函数的自变量,将分类正确率作为主要衡量标准,未选择的特征个数为次要标准。由此建立以下的适应度函数:
![]()
式中C为分类正确率,为未选择的特征个数,a是调节系数,用来平衡分类正确率和未选择的特征个数对适应度函数的影响程度,同时该系数也体现了用最少的特征得到较大分类正确率的原则,在本文中a取0.00077。由上式可知,分类正确率越高,未选的特征个数越多,染色体的适应度就越大。
选择操作
选择操作需要按照一定的规则从原有的种群中选择部分优秀个体用来交叉和变异。选择原则建立在对个体适应度进行评价的基础上,目的是避免基因损失,提高全局收敛性和计算效率。本文首先将整个种群中最优的前40%的个体保留下来,以确保有足够的优良个体进入下一代,对剩下的60%的个体采用轮盘算法进行选择,这样做可以弥补保留前40%个体而带来的局部最优解不易被淘汰的不利影响,有利于保持种群的多样性。
基于敏感度信息量的交叉、变异操作
独立敏感度信息量Q(i)指的是对在所有特征都被选中时计算所得到的适应度值Allfitness以及只有特征i未被选中时计算得到的适应度值Wfitness(i)按式(2)进行计算得到的数值。独立敏感度信息量刻画了适应度对特征i是否被选择的敏感程度。
![]()
互敏感度信息量R(i,j)由(3)式可得,互敏感度信息量体现了特征i与特征j之间对适应度的近似影响程度。
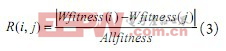





评论