
Xilinx UltraScale™:为您未来架构而打造的新一代架构
因此,基于UltraScale架构的All Programmable器件能提供超过1 Tb/s的DDR SDRAM存储器带宽,用以满足领先的新一代系统设计提出的海量数据流、快速处理和超大存储器等要求。与软核PHY相比,硬化的SDRAM PHY模块能将读取时延降低30%,同时该模块能控制DDR4 SDRAM,从而将用于外部存储器的功耗降低20%以上。
本文引用地址:http://www.amcfsurvey.com/article/147542.htm片上Block RAM性能往往是影响系统最大时钟速率的关键因素。赛灵思已对UltraScale架构All Programmable器件中的Block RAM进行了重新设计,以便在降低功耗的同时与系统中其他可编程模块的性能相匹配。新的Block RAM架构支持高速存储器级联,消除了DSP和包处理中存在的瓶颈。输出多路复用器在这种新架构中的使用方式很独特,使得Vivado设计套件工具在无需附加片让布线或逻辑资源的情况下也能高效创建大型、快速的RAM阵列和FIFO。
赛灵思还加强了基于UltraScale架构的Block RAM FIFO配置,以便在相同FIFO上支持不同宽度的输入与输出端口。当FIFO需要从一个系统时钟域跨越到另一个域时(UltraScale架构现在支持很多个时钟域),这项功能很有帮助。
实现快速、智能处理
为满足最终用户要求,DSP和包处理系统的性能需要不断提高,如图8示。
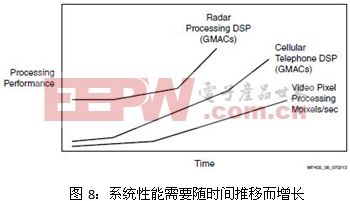
人们需要从噪声中提取更多信号信息;需要创建更加逼真的图像;需要应对无止境的数据包流量增长,所有这些都在对性能提出更高要求。然而,与此同时,还要将成本控制在规定的预算范围内,这样就给设计带来了诸多实际限制。如图9所示,图中描述了LTE和LTE Advanced(LTE-A)基站的性能与成本随时间的变化趋势。
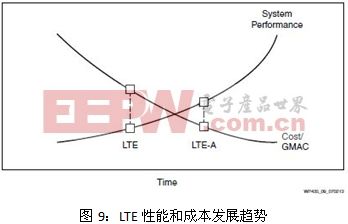
简而言之,客户需要以更低成本获得更高的系统性能,这是大多数电子产业永恒不变的趋势,而这也正是UltraScale架构的优势所在。
在领先的性能优势基础之上增强DSP
赛灵思针对UltraScale架构显著增强了已经具备行业最高性能的Virtex-7 FPGA的DSP48E1 DSP slice,以实现更快的数字信号处理能力,同时减少DSP模块外部的布线或逻辑资源使用量。在DSP slice上应用的一系列创新功能可以改善乘法运算和MACC运算,从而增强功能并降低功耗。
基于UltraScale架构的DSP48E2 DSP slice包含27×18位乘法器,可将更大的函数映射到更少的DSP slice中。例如,DSP48E2 block凭借更宽的27×18位乘法器能够以更少的资源实现IEEE Std 754双精度算法,与采用赛灵思7系列All Programmable器件中的DSP48E1模块实现相同功能相比,所采用的DSP模块数量可减少三分之二。
在DSP48E2 slice中包含宽MUX和宽XOR函数后,像错误校正与控制(ECC)、循环冗余校验(CRC)以及前向纠错(FEC)等非DSP运算就可以将DSP slice作为高速、硬化的宽逻辑模块来使用。这些增强特性有助于提高性能,降低功耗,并减少可配置逻辑模块(CLB)的使用量,从而将更多CLB用于实现其他功能。正是通过为DSP等模块增加新功能,UltraScale架构得以同时满足新一代应用对于提高处理能力以及降低成本方面的要求。
扩展的智能数据包处理性能
无止境的带宽需求正持续推高网络通信基础设施的升级投入。数字视频传输所形成的海量数据流加速了100Gb/s网络设备的成熟,同时也加大了对400G解决方案的需求。数据包处理甚至可以给当前业内数百Gb每秒速率的最先进架构带来严峻的性能挑战。在线路速度下执行的校验和计算与桥接等基础数据包处理功能会对性能和资源利用率带来显著影响。
除了解决与高性能数据包处理有关的海量数据流问题外,UltraScale架构还包含多种专为数据包处理定制的创新功能。其中包括:对DSP48模块进行修改以支持线速度下进行的CRC 32校验和计算;加入了硬化的Gb以太网MAC和Interlaken芯片到芯片接口,用以支持智能数据包处理的性能突破和最新的集成等级。

存储器相关文章:存储器原理





评论