
Xilinx UltraScale™:为您未来架构而打造的新一代架构
更为复杂的问题在于,通过大量的宽数据总线来扩展性能会带来额外的代价,那就是需要显著增加逻辑电路开销用以支持宽总线的实施,从而进一步加大实现时序收敛的难度。
本文引用地址:http://www.amcfsurvey.com/article/147542.htm以以太网数据包大小为例可以很好地说明这个情况。以太网的数据包最小为64字节(512位)。假设采用2048位宽的总线来实现400G的系统,那么总线最多容纳4个数据包。
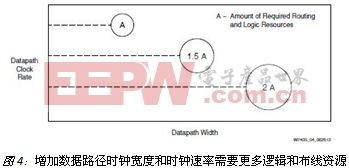
在2048位宽的总线中存在多种数据包组合形式,例如4个完整数据包或者1个、2个或3个完整或部分数据包,这样需要使用大量逻辑来处理不同的情况与组合。需要大量复杂的重复逻辑来应对这些可能的组合。此外,如果总线要求对四个数据包进行同时处理并写入到存储器中,那么可能需要对逻辑的某些部分进行加速(或扩展性能)。可以考虑通过逻辑加速或用四个独立的相同存储器控制器来相继处理多个数据包,但这些方式会进一步加大布线资源的压力,迫使架构必须具备更多的高性能、低歪斜布线资源。参见图4。
半导体工艺的扩展影响互连技术
随着业界向20nm或更高级半导体工艺技术推进,在与铜线互连有关的RC延迟方面出现了新的挑战,它会阻碍向新工艺节点演进所实现的性能提升效果。晶体管互连延迟的增加会直接影响所能实现的总体系统性能,因此更加需要所使用的布线架构能提供满足新一代应用要求的性能等级。UltraScale布线架构在开发过程中充分考虑了新一代工艺技术的特点,而且能明显减轻铜线互连的影响——如不进行妥善处理会成为系统性能瓶颈。
UltraScale互连架构:针对海量数据流进行优化
UltraScale新一代互连架构的推出体现了可编程逻辑布线技术的真正突破。赛灵思致力于满足从多Gb智能包处理到多Tb数据路径等新一代应用需求,即必须支持海量数据流。在实现宽总线逻辑模块(将总线宽度扩展至512位、1024位甚至更高)的过程中,布线或互连拥塞问题一直是影响实现时序收敛和高质量结果的主要制约因素。过于拥堵的逻辑设计通常无法在早期器件架构中进行布线;即使工具能够对拥塞的设计进行布线,最终设计也经常需要在低于预期的时钟速率下运行。而UltraScale布线架构则能完全消除布线拥塞问题。结论很简单:只要设计合理,就能进行布线。
我们来做个类比。位于市中心的一个繁忙十字路口,交通流量的方向是从北到南,从南到北,从东到西,从西到东,有些车辆正试图掉头,所有交通车辆试图同时移动。这样通常就会造成大堵车。现在考虑一下将这样的十字路口精心设计为现代化高速公路或主干道,情况又会如何。道路设计人员设计出了专用坡道(快行道),用以将交通流量从主要高速路口的一端顺畅地疏导至另一端。交通流量可以从高速路的一端全速移动到另一端,不存在堵车现象。
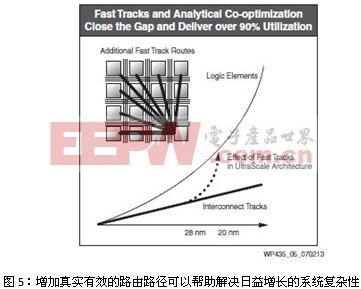
赛灵思为UltraScale架构加入了类似的快行道。这些新增的快行道可供附近的逻辑元件之间传输数据,尽管这些元件并不一定相邻,但它们仍通过特定的设计实现逻辑上的连接。这样,UltraScale架构所能管理的数据量就会呈指数级上升,如图5所示。
UltraScale架构堆叠硅片互联技术全面强化所有功能
很少有开发的技术能够像堆叠硅片互联(SSI)技术集成那样对器件容量和性能产生如此重大的影响,这已得到了赛灵思第一代基于7系列All Programmable器件的3D IC产品的验证。集成SSI技术后,设计人员可以构建出工艺技术领先行业标准整整一代水平的更大型器件。而且该技术在赛灵思第二代基于UltraScale架构的3D IC产品中也同样会达到这种效果。
由于3D IC中硅片间通信连接比独立封装的硅片间通信连接更密集、更快速,因此硅片间的通信所需功耗更低(假设硅片无需驱动硅片到封装间互连以及板级互连的附加阻抗)。所以,与独立封装的硅片相比,SSI技术的集成能够在显著扩大容量和性能的同时降低功耗。此外,由于无法轻易访问电路板层面的硅片间通信,这样系统安全性也得到了加强。

存储器相关文章:存储器原理





评论