
粗粒度的时空计算
摘要:不断提高计算机的能力是支持数学上的infinite的技术途径之一,本文介绍了标量计算机、并行计算模式、阵列语言、阵列计算机等技术。但强大的计算能力遭遇到了能耗问题。圆片级的硅直通技术(TSV)是降低能耗的途径之一。粗粒度的阵列计算机的规则性是适合于TSV技术的。
本文引用地址:http://www.amcfsurvey.com/article/143176.htm
前言
按照牛顿物理学,人们可感知的3维空间中的事物是随1维时间而演变的[1] ;而按照爱因斯坦的狭义相对论,时间和空间并不是有所分别的两件东西,两者是合成4维的时空(space-time)的,时间是第4个维度。狭义相对论是4维时空的数学框架,和牛顿物理学本质上是相同的。因此,可以认为人们可感知的客观世界的一切事物是在4维时空中演变的。计算机是用来对事物演变的数据完成时空计算的,其计算模式的实现应该是自然反应时空计算的概念的。数学家是以描述客观世界的数学语言为基础发明计算机的。数学是无穷(infinite)的科学,是研究数和形的。计算机就是以无穷的存储空间(图灵抽象机的无穷长的带,和冯.诺依曼计算机的输入/输出体系结构)和无止境的提高计算能力(也就是提高处理器的计算频率,以及增加处理器的复杂度)来支持数学上的infinite的,而数和形的研究不仅有细粒度标量计算的特点,还有粗粒度阵列计算的特点。
标量计算机
芯片技术问世之后,计算机的设计工作越来越多地转移到了芯片上。1971年Intel公司的Ted Hoff(特德.霍夫)工程师发明了世界上第一颗微处理器芯片Intel 4004[2]。处理器将ISA(Instruction Set Architecture)的设计工作转移到了芯片上。按照冯.诺依曼体系结构的Flynn分类[3] ,单处理器计算机,是以单指令流单数据流的SISD体系结构为基础的标量计算机(Scalar Computer)。细粒度的标量计算是“从点开始,从点到线,从线到面”再“分层处理” 完成事物演变的时空计算的,是一种(时间)1维的计算机,粗粒度的阵列计算在标量计算机上是顺序完成的。标量计算机是以ISA作为更高抽象层次的接口,使程序设计不必了解ISA的实现细节,能从算法解决问题的方式中直觉地产生出来,成为一种确定而可预测的过程,促进了细粒度时空计算的软件繁荣[4] 。
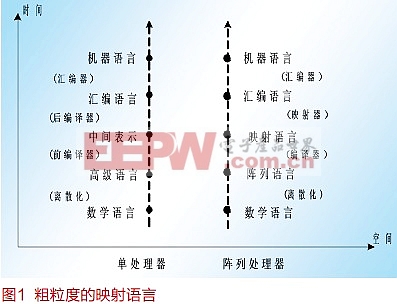
并行计算模式
1974年 Robert Dennard等提出了按比例缩小定律。芯片的集成度是在功耗密度与成本几乎不变的情况下,按摩尔预言的速度提高的。1987年人们提出了系统芯片(SoC,System On Chip)的概念,要将计算机的系统设计工作也转移到芯片上来,发展出了TLP(Tread Level Parallel,进程级并行)、 DLP(Data Level Parallel,数据级并行)和OLP(Operation Level Parallel,操作级并行)三种并行计算模式。但其实现,遭遇到了计算可扩展性限制和能源使用问题。只有OLP计算模式实现了操作粗粒度的时空计算,但是采用ASIC/FPGA阵列芯片,而不是阵列处理器实现的。
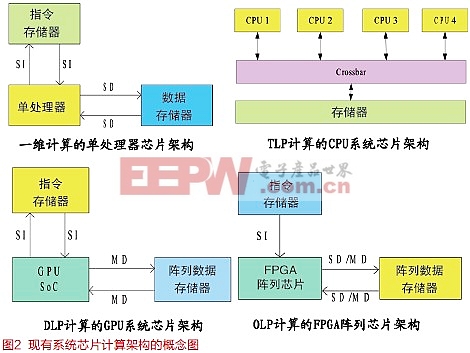
由多核/众核CPU系统芯片实现的TLP计算模式,是将计算任务分成多个线程安排在每个标量处理器核(CPU)上执行的。线程之间是通过共享存储器通信的,没有直接的互连关系,实际上是一种单指令流多线程流的SIMT(Single Instruction Multiple Thread)执行。虽然线程可以同时开始执行计算,但不一定能同时完成计算,存在如何同步(同时完成)的问题;线程之间也可能存在数据相关,不能完全独立的执行,有互斥(数据依赖)的问题。使多核程序设计是一种内在不确定性的过程(nondeterministic process),需要彻底了解多核计算机的实现细节[4] 。
按照冯.诺依曼体系结构的Flynn分类,DLP计算模式应该是以单指令流多数据流的SIMD体系结构为基础,实现数据粗粒度的时空计算的。而现在实现DLP计算模式的GPU/GPGPU系统芯片,计算效率虽然比多核芯片的高得多,已应用在超级计算机中,但都不能有效实现数据粗粒度的时空计算。例如,索尼、东芝和IBM公司联合开发的总线互连的Cell芯片,只是DLP计算模式的一种SIMT执行[5]。Nvidia公司的GPGPU系统芯片,是一种GPU+CPU的系统芯片,由于GPU和CPU的数目是固定的,在不同应用中会出现比例分配不平衡和数据传输的问题[6] 。














评论